Adding a JDBC connection using your own JDBC drivers
You can use your own JDBC driver when using a JDBC connection. When the default driver utilized by the Amazon Glue crawler is unable to connect to a database, you can use your own JDBC Driver. For example, if you want to use SHA-256 with your Postgres database, and older postgres drivers do not support this, you can use your own JDBC driver.
Supported datasources
| Supported datasources | Unsupported datasources |
|---|---|
| MySQL | Snowflake |
| Postgres | |
| Oracle | |
| Redshift | |
| SQL Server | |
| Aurora* |
*Supported if the native JDBC driver is being used. Not all driver features can be leveraged.
Adding a JDBC driver to a JDBC connection
Note
If you choose to bring in your own JDBC driver versions, Amazon Glue crawlers will consume resources in Amazon Glue jobs and Amazon S3 buckets to ensure your provided driver are run in your environment. The additional usage of resources will be reflected in your account. The cost for Amazon Glue crawlers and jobs is under the Amazon Glue category in billing. Additionally, providing your own JDBC driver does not mean that the crawler is able to leverage all of the driver's features.
To add your own JDBC driver to a JDBC connection:
-
Add the JDBC driver file to an Amazon S3 location. You can create a bucket and/or folder or use an existing bucket and/or folder.
-
In the Amazon Glue console, choose Connections in the left-hand menu under Data Catalog, then create a new connection.
-
Complete the fields for Connection properties and choose JDBC for Connection type.
-
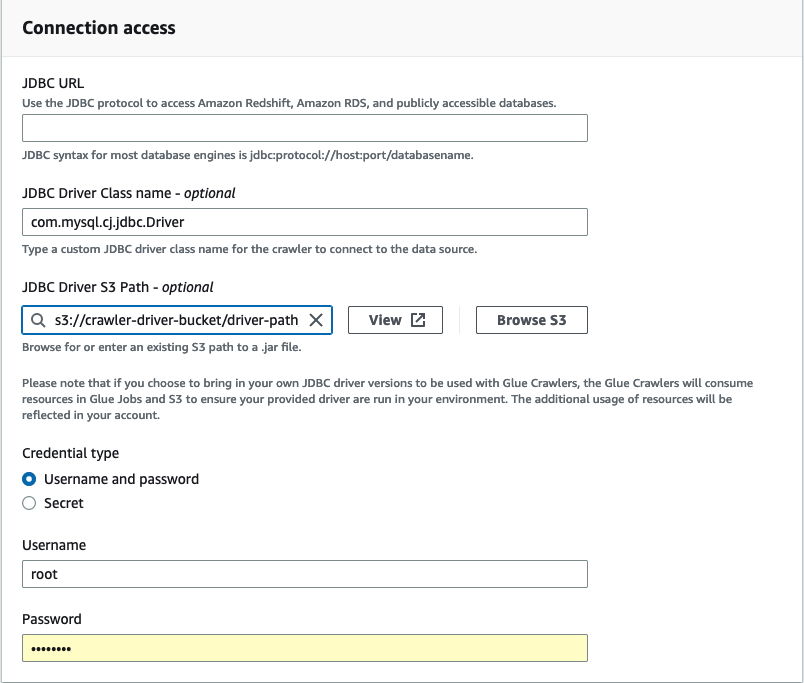
In Connection access, enter the JDBC URL and JDBC Driver Class name – optional. The driver class name must be for a datasource supported by Amazon Glue crawlers.
-
Choose the Amazon S3 path where the JDBC driver is located in the JDBC Driver Amazon S3 Path – optional field.
-
Complete the fields for Credential type if entering a username and password or secret. When complete, choose Create connection.
Note
Testing connection is not supported currently. When crawling the data source with a JDBC driver you provided, the crawler skips this step.
-
Add the newly created connection to a crawler. In the Amazon Glue console, choose Crawlers in the left-hand menu under Data Catalog, then create a new crawler.
-
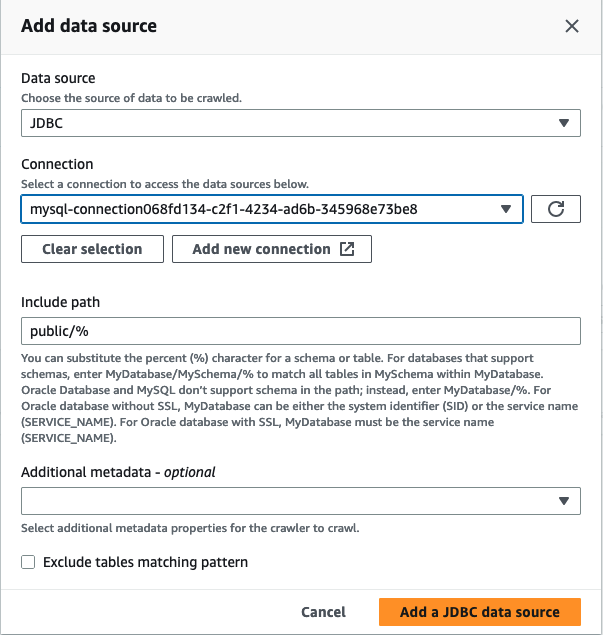
In the Add crawler wizard, in Step 2 choose Add a data source.
-
Choose JDBC as the data source and choose the the connection that was created in the previous steps. Complete
-
In order to use your own JDBC driver with a Amazon Glue crawler, add the following permissions to the role used by the crawler:
-
Grant permissions for the following job actions:
CreateJob,DeleteJob,GetJob,GetJobRun,StartJobRun. -
Grant permissions for IAM actions:
iam:PassRole -
Grant permissions for Amazon S3 actions:
s3:DeleteObjects,s3:GetObject,s3:ListBucket,s3:PutObject. -
Grant service principal access to bucket/folder in the IAM policy.
Example IAM policy:
The Amazon Glue crawler creates two folders: _glue_job_crawler and _crawler.
If the driver jar is located in the
s3://amzn-s3-demo-bucket/driver.jar"folder, add the following resources:"Resource": [ "arn:aws:s3:::amzn-s3-demo-bucket/_glue_job_crawler/*", "arn:aws:s3:::amzn-s3-demo-bucket/_crawler/*" ]If the driver jar is located in the
s3://amzn-s3-demo-bucket/tmp/driver/subfolder/driver.jar"folder, add the following resources:"Resource": [ "arn:aws:s3:::amzn-s3-demo-bucket/tmp/_glue_job_crawler/*", "arn:aws:s3:::amzn-s3-demo-bucket/tmp/_crawler/*" ] -
-
If you are using a VPC, you must allow access to the Amazon Glue endpoint by creating the interface endpoint and add it to your route table. For more information, see Creating an interface VPC endpoint for Amazon Glue
-
If you are using encryption in your Data Catalog, create the Amazon KMS interface endpoint and add it to your route table. For more information, see Creating a VPC endpoint for Amazon KMS.