Services or capabilities described in Amazon Web Services documentation might vary by Region. To see the differences applicable to the China Regions,
see Getting Started with Amazon Web Services in China
(PDF).
Specifying the table location and partitioning level
By default, when a crawler defines tables for data stored in Amazon S3 the crawler attempts to
merge schemas together, and create top-level tables (year=2019). In some cases,
you may expect the crawler to create a table for the folder month=Jan but instead
the crawler creates a partition since a sibling folder (month=Mar) was merged
into the same table.
The table level crawler option provides you the flexibility to tell the crawler where the
tables are located, and how you want partitions created. When you specify a Table
level, the table is created at that absolute level from the Amazon S3 bucket.
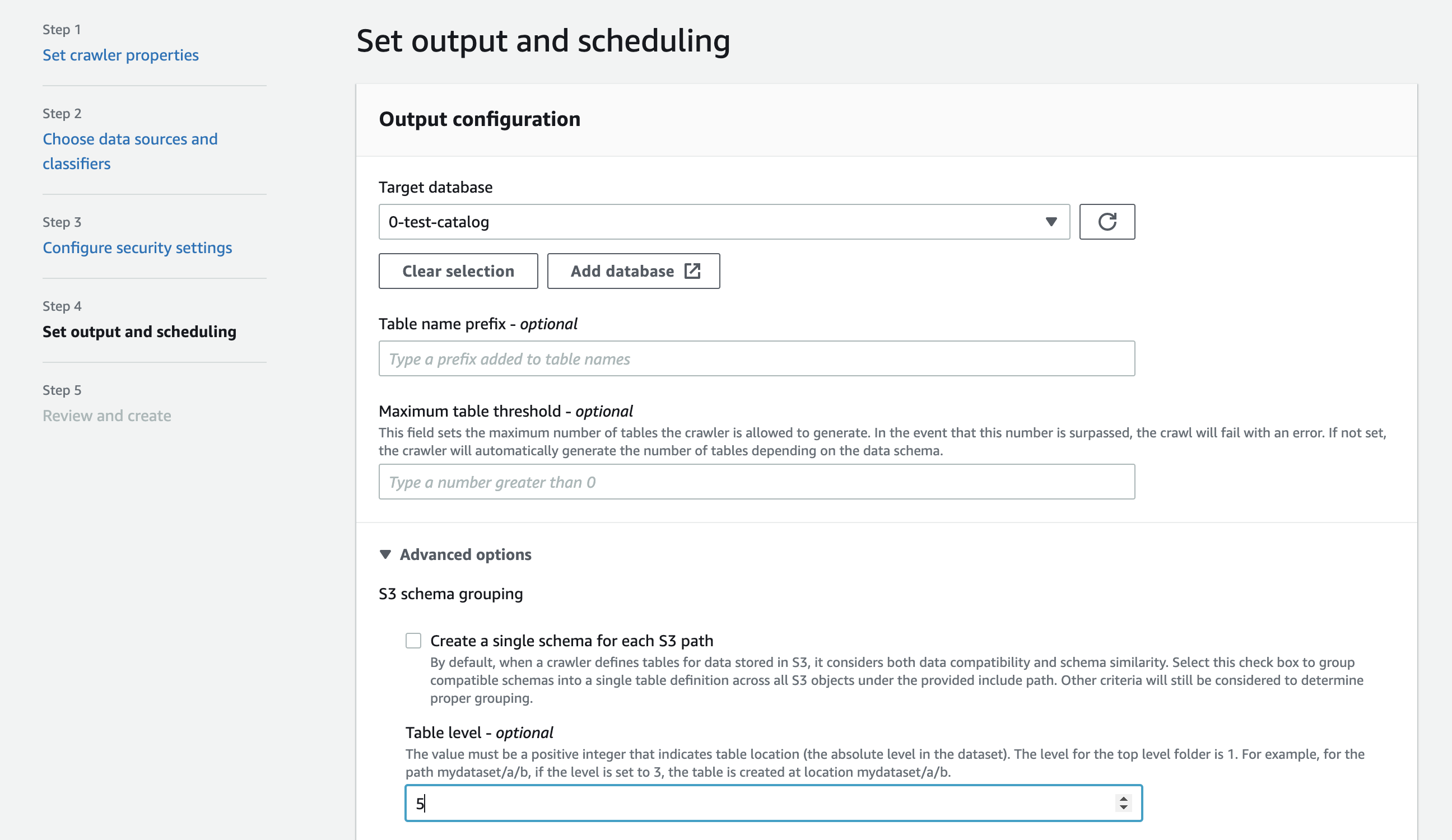
When configuring the crawler on the console, you can specify a value for the Table level crawler option.
The value must be a positive integer that indicates the table location (the absolute level in the dataset).
The level for the top level folder is 1. For example, for the path mydataset/year/month/day/hour, if the level is set to 3,
the table is created at location mydataset/year/month.
- Amazon Web Services Management Console
-
Sign in to the Amazon Web Services Management Console and open the Amazon Glue console at
https://console.amazonaws.cn/glue/.
-
Choose Crawlers under the
Data Catalog.
When you configure a crawler, under Output and scheduling, choose Table
level under Advance options.
- Amazon CLI
-
When you configure the crawler using the Amazon CLI, set the configuration
parameter as shown in the example code:
aws glue update-crawler \
--name myCrawler \
--configuration '{"Version": 1.0, "Grouping": { "TableLevelConfiguration": 2 }}'
- API
-
When you configure the crawler using the API, set the Configuration
field with a string representation of the following JSON object; for example:
configuration = jsonencode(
{
"Version": 1.0,
"Grouping": {
TableLevelConfiguration = 2
}
})
- CloudFormation
In this example, you set the Table level option available in the console
within your CloudFormation template:
"Configuration": "{
\"Version\":1.0,
\"Grouping\":{\"TableLevelConfiguration\":2}
}"