Services or capabilities described in Amazon Web Services documentation might vary by Region. To see the differences applicable to the China Regions,
see Getting Started with Amazon Web Services in China
(PDF).
Setup required when the crawler and registered Amazon S3 location reside in different accounts (cross-account crawling)
To allow the crawler to access a data store in a different account using
Lake Formation credentials, you must first register the Amazon S3 data location with Lake Formation. Then, you grant
data location permissions to the crawler's account by taking the following steps.
You can complete the following steps using the Amazon Web Services Management Console or Amazon CLI.
- Amazon Web Services Management Console
-
In the account where the Amazon S3 location is registered (account B):
-
Register an Amazon S3 path with Lake Formation. For more information, see Registering Amazon S3
location.
-
Grant Data location permissions to the account (account A) where the crawler will be run. For more information, see
Grant data location permissions.
-
Create an empty database in Lake Formation with the underlying location as the target
Amazon S3 location. For more information, see Creating a database.
-
Grant account A (the account where the crawler will be run) access to the
database that you created in the previous step. For more information, see Granting
database permissions.
-
In the account where the crawler is created and will be run (account A):
-
Using the Amazon RAM console, accept the database that was shared from the external account (account B). For more information, see Accepting a resource share invitation from Amazon Resource Access Manager.
-
Create an IAM role for the crawler. Add lakeformation:GetDataAccess policy to the role.
-
In the Lake Formation console (https://console.amazonaws.cn/lakeformation/), grant Data location permissions on the target Amazon S3 location to the IAM role used for the crawler run so that the crawler can read the data from the destination in Lake Formation.
For more information, see Granting data location permissions.
-
Create a resource link on the shared database. For more information, see Create a resource link.
-
Grant the crawler role access permissions (Create) on the shared database and (Describe) the resource link. The resource link is specified in the output for the crawler.
-
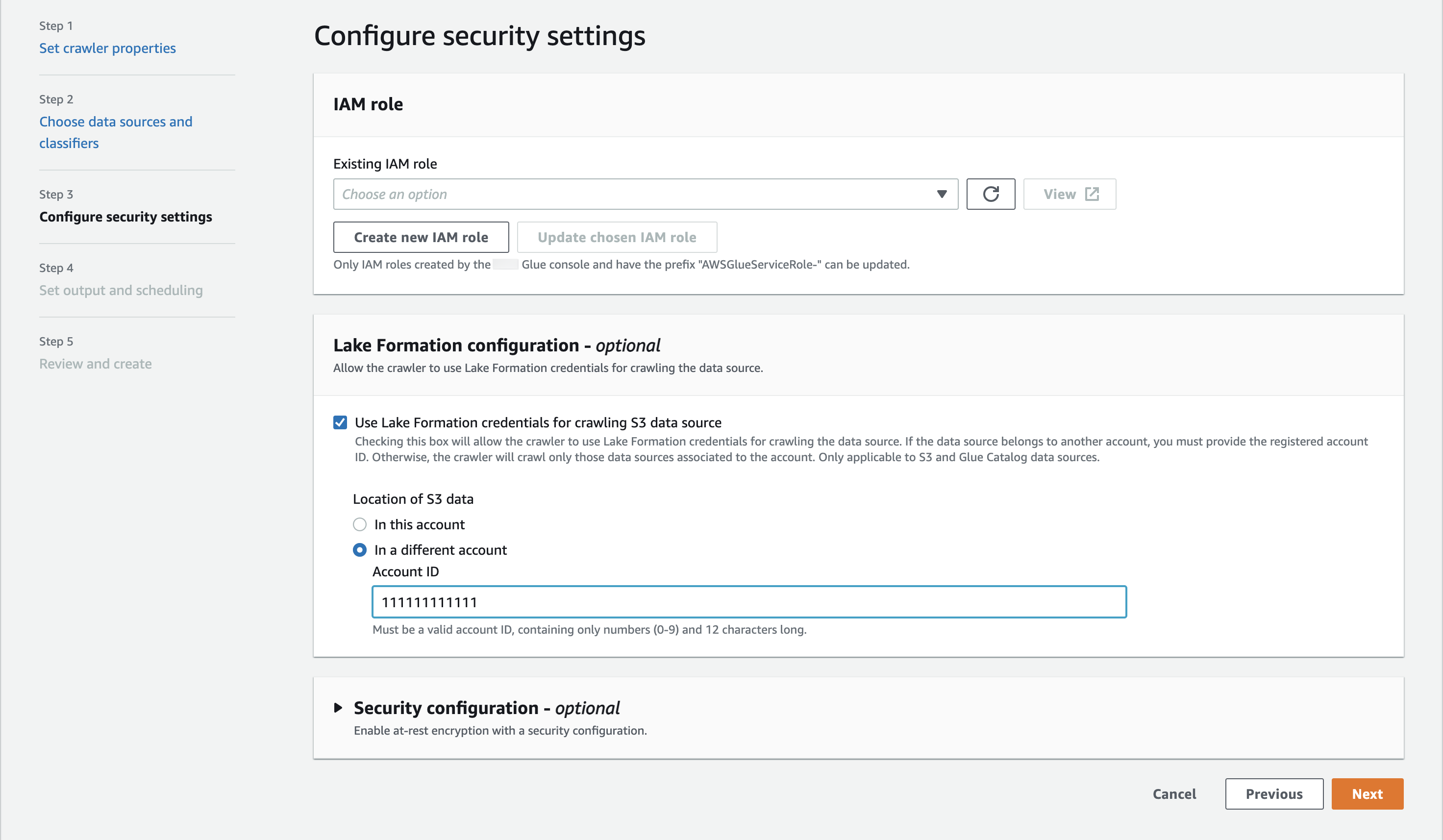
In the Amazon Glue console (https://console.amazonaws.cn/glue/), while configuring the crawler,
select the option Use Lake Formation credentials for crawling Amazon S3 data
source.
For cross-account crawling, specify the Amazon Web Services account ID where the
target Amazon S3 location is registered with Lake Formation. For in-account crawling, the
accountId field is optional.
- Amazon CLI
-
aws glue --profile demo create-crawler --debug --cli-input-json '{
"Name": "prod-test-crawler",
"Role": "arn:aws:iam::111122223333:role/service-role/AWSGlueServiceRole-prod-test-run-role",
"DatabaseName": "prod-run-db",
"Description": "",
"Targets": {
"S3Targets":[
{
"Path": "s3://amzn-s3-demo-bucket"
}
]
},
"SchemaChangePolicy": {
"UpdateBehavior": "LOG",
"DeleteBehavior": "LOG"
},
"RecrawlPolicy": {
"RecrawlBehavior": "CRAWL_EVERYTHING"
},
"LineageConfiguration": {
"CrawlerLineageSettings": "DISABLE"
},
"LakeFormationConfiguration": {
"UseLakeFormationCredentials": true,
"AccountId": "111111111111"
},
"Configuration": {
"Version": 1.0,
"CrawlerOutput": {
"Partitions": { "AddOrUpdateBehavior": "InheritFromTable" },
"Tables": {"AddOrUpdateBehavior": "MergeNewColumns" }
},
"Grouping": { "TableGroupingPolicy": "CombineCompatibleSchemas" }
},
"CrawlerSecurityConfiguration": "",
"Tags": {
"KeyName": ""
}
}'
A crawler using Lake Formation credentials is only supported for Amazon S3 and Data Catalog targets.
For targets using Lake Formation credential vending, the underlying Amazon S3 locations must belong to the same bucket. For example, customers can use multiple targets (s3://amzn-s3-demo-bucket1/folder1, s3://amzn-s3-demo-bucket1/folder2) as long as all target locations are under the same bucket (amzn-s3-demo-bucket1). Specifying different buckets (s3://amzn-s3-demo-bucket1/folder1, s3://amzn-s3-demo-bucket2/folder2) is not allowed.
Currently for Data Catalog target crawlers, only a single catalog target with a single catalog table is allowed.