Using Amazon Glue with Amazon Lake Formation for fine-grained access control
Overview
With Amazon Glue version 5.0 and higher, you can leverage Amazon Lake Formation to apply fine-grained access controls on Data Catalog tables that are backed by S3. This capability lets you configure table, row, column, and cell level access controls for read queries within your Amazon Glue for Apache Spark jobs. See the following sections to learn more about Lake Formation and how to use it with Amazon Glue.
GlueContext-based table-level access control with Amazon Lake Formation permissions supported in Glue 4.0 or before is not supported in Glue 5.0. Use the new Spark native fine-grained access control (FGAC) in Glue 5.0. Note the following details:
If you need fine grained access control (FGAC) for row/column/cell access control, you will need to migrate from
GlueContext/Glue DynamicFrame in Glue 4.0 and prior to Spark dataframe in Glue 5.0. For examples, see Migrating from GlueContext/Glue DynamicFrame to Spark DataFrameIf you need Full Table Access control (FTA), you can leverage FTA with DynamicFrames in Amazon Glue 5.0. You can also migrate to native Spark approach for additional capabilities such as Resilient Distributed Datasets (RDDs), custom libraries, and User Defined Functions (UDFs) with Amazon Lake Formation tables. For examples, see Migrating from Amazon Glue 4.0 to Amazon Glue 5.0.
If you don't need FGAC, then no migration to Spark dataframe is necessary and
GlueContextfeatures like job bookmarks, push down predicates will continue to work.Jobs with FGAC require a minimum of 4 workers: one user driver, one system driver, one system executor, and one standby user executor.
Using Amazon Glue with Amazon Lake Formation incurs additional charges.
How Amazon Glue works with Amazon Lake Formation
Using Amazon Glue with Lake Formation lets you enforce a layer of permissions on each Spark
job to apply Lake Formation permissions control when Amazon Glue executes jobs.
Amazon Glue uses Spark resource profiles
The following is a high-level overview of how Amazon Glue gets access to data protected by Lake Formation security policies.
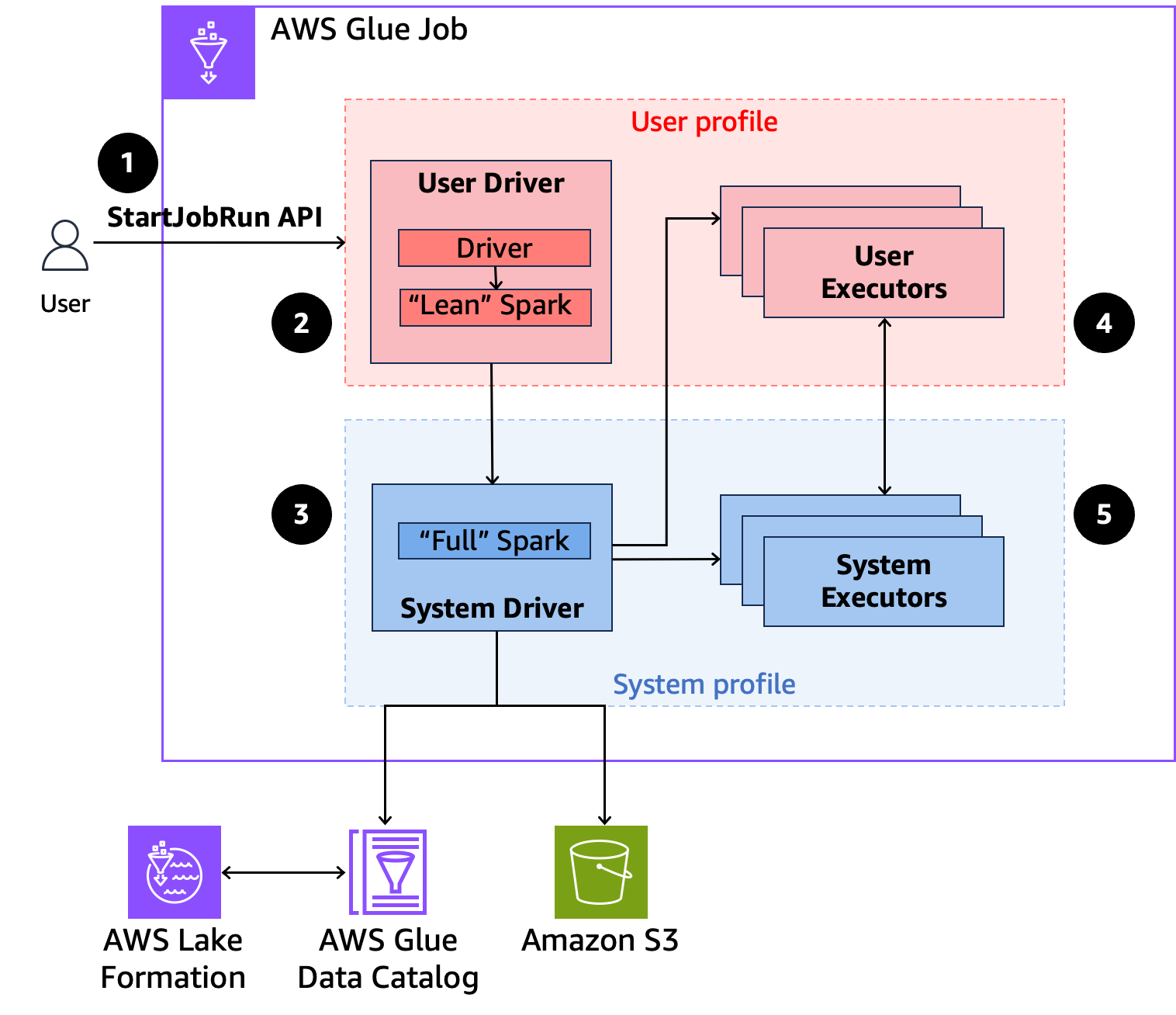
-
A user calls the
StartJobRunAPI on an Amazon Lake Formation-enabled Amazon Glue job. -
Amazon Glue sends the job to a user driver and runs the job in the user profile. The user driver runs a lean version of Spark that has no ability to launch tasks, request executors, access S3 or the Glue Catalog. It builds a job plan.
-
Amazon Glue sets up a second driver called the system driver and runs it in the system profile (with a privileged identity). Amazon Glue sets up an encrypted TLS channel between the two drivers for communication. The user driver uses the channel to send the job plans to the system driver. The system driver does not run user-submitted code. It runs full Spark and communicates with S3, and the Data Catalog for data access. It request executors and compiles the Job Plan into a sequence of execution stages.
-
Amazon Glue then runs the stages on executors with the user driver or system driver. User code in any stage is run exclusively on user profile executors.
-
Stages that read data from Data Catalog tables protected by Amazon Lake Formation or those that apply security filters are delegated to system executors.
Minimum worker requirement
A Lake Formation-enabled job in Amazon Glue requires a minimum of 4 workers: one user driver, one system driver, one system executor, and one standby User Executor. This is up from the minimum of 2 workers required for standard Amazon Glue jobs.
A Lake Formation-enabled job in Amazon Glue utilizes two Spark drivers—one for the system profile and another for the user profile. Similarly, the executors are also divided into two profiles:
System executors: handle tasks where Lake Formation data filters are applied.
User executors: are requested by the system driver as needed.
As Spark jobs are lazy in nature, Amazon Glue reserves 10% of the total workers (minimum of 1), after deducting the two drivers, for user executors.
All Lake Formation-enabled jobs have auto-scaling enabled, meaning the user executors will only start when needed.
For an example configuration, see Considerations and limitations.
Job runtime role IAM permissions
Lake Formation permissions control access to Amazon Glue Data Catalog resources, Amazon S3 locations, and the
underlying data at those locations. IAM permissions control access to the Lake Formation and
Amazon Glue APIs and resources. Although you might have the Lake Formation permission to access a table
in the Data Catalog (SELECT), your operation fails if you don’t have the IAM permission on
the glue:Get* API operation.
The following is an example policy of how to provide IAM permissions to access a script in S3, uploading logs to S3, Amazon Glue API permissions, and permission to access Lake Formation.
Setting up Lake Formation permissions for job runtime role
First, register the location of your Hive table with Lake Formation. Then create permissions for your job runtime role on your desired table. For more details about Lake Formation, see What is Amazon Lake Formation? in the Amazon Lake Formation Developer Guide.
After you set up the Lake Formation permissions, you can submit Spark jobs on Amazon Glue.
Submitting a job run
After you finish setting up the Lake Formation grants, you can submit Spark jobs on Amazon Glue. To run Iceberg jobs, you must provide the following Spark configurations. To configure through Glue job parameters, put the following parameter:
Key:
--confValue:
spark.sql.catalog.spark_catalog=org.apache.iceberg.spark.SparkSessionCatalog --conf spark.sql.catalog.spark_catalog.warehouse=<S3_DATA_LOCATION> --conf spark.sql.catalog.spark_catalog.glue.account-id=<ACCOUNT_ID> --conf spark.sql.catalog.spark_catalog.client.region=<REGION> --conf spark.sql.catalog.spark_catalog.glue.endpoint=https://glue.<REGION>.amazonaws.com
Using an Interactive Session
After you finish setting up the Amazon Lake Formation grants, you can use Interactive Sessions on Amazon Glue. You must provide the following
Spark configurations via the %%configure magic prior to executing code.
%%configure { "--enable-lakeformation-fine-grained-access": "true", "--conf": "spark.sql.catalog.spark_catalog=org.apache.iceberg.spark.SparkSessionCatalog --conf spark.sql.catalog.spark_catalog.warehouse=<S3_DATA_LOCATION> --conf spark.sql.catalog.spark_catalog.catalog-impl=org.apache.iceberg.aws.glue.GlueCatalog --conf spark.sql.catalog.spark_catalog.io-impl=org.apache.iceberg.aws.s3.S3FileIO --conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions --conf spark.sql.catalog.spark_catalog.client.region=<REGION> --conf spark.sql.catalog.spark_catalog.glue.account-id=<ACCOUNT_ID> --conf spark.sql.catalog.spark_catalog.glue.endpoint=https://glue.<REGION>.amazonaws.com" }
FGAC for Amazon Glue 5.0 Notebook or interactive sessions
To enable Fine-Grained Access Control (FGAC) in Amazon Glue you must specify the Spark confs required for Lake Formation as part of the %%configure magic before you create first cell.
Specifying it later using the calls SparkSession.builder().conf("").get() or SparkSession.builder().conf("").create() will not be enough. This is a change from the Amazon Glue 4.0 behavior.
Open-table format support
Amazon Glue version 5.0 or later includes support for fine-grained access control based on Lake Formation. Amazon Glue supports Hive and Iceberg table types. The following table describes all of the supported operations.
| Operations | Hive | Iceberg |
|---|---|---|
| DDL commands | With IAM role permissions only | With IAM role permissions only |
| Incremental queries | Not applicable | Fully supported |
| Time travel queries | Not applicable to this table format | Fully supported |
| Metadata tables | Not applicable to this table format | Supported, but certain tables are hidden. See considerations and limitations for more information. |
DML INSERT |
With IAM permissions only | With IAM permissions only |
| DML UPDATE | Not applicable to this table format | With IAM permissions only |
DML DELETE |
Not applicable to this table format | With IAM permissions only |
| Read operations | Fully supported | Fully supported |
| Stored procedures | Not applicable | Supported with the exceptions of register_table and migrate. See
considerations and limitations for more information. |