Generative AI troubleshooting for Apache Spark in Amazon Glue
Generative AI Troubleshooting for Apache Spark jobs in Amazon Glue is a new capability that helps data engineers and scientists diagnose and fix issues in their Spark applications with ease. Utilizing machine learning and generative AI technologies, this feature analyzes issues in Spark jobs and provides detailed root cause analysis along with actionable recommendations to resolve those issues. The generative AI troubleshooting for Apache Spark is available for jobs running on Amazon Glue version 4.0 and above.
|
Transform your Apache Spark troubleshooting with our AI-powered Troubleshooting Agent, now supporting all major deployment modes including Amazon Glue, Amazon EMR-EC2, Amazon EMR-Serverless and Amazon SageMaker AI Notebooks. This powerful agent eliminates complex debugging processes by combining natural language interactions, real-time workload analysis, and smart code recommendations into a seamless experience. For implementation details, refer to What is Apache Spark Troubleshooting Agent for Amazon EMR |
How does Generative AI Troubleshooting for Apache Spark work?
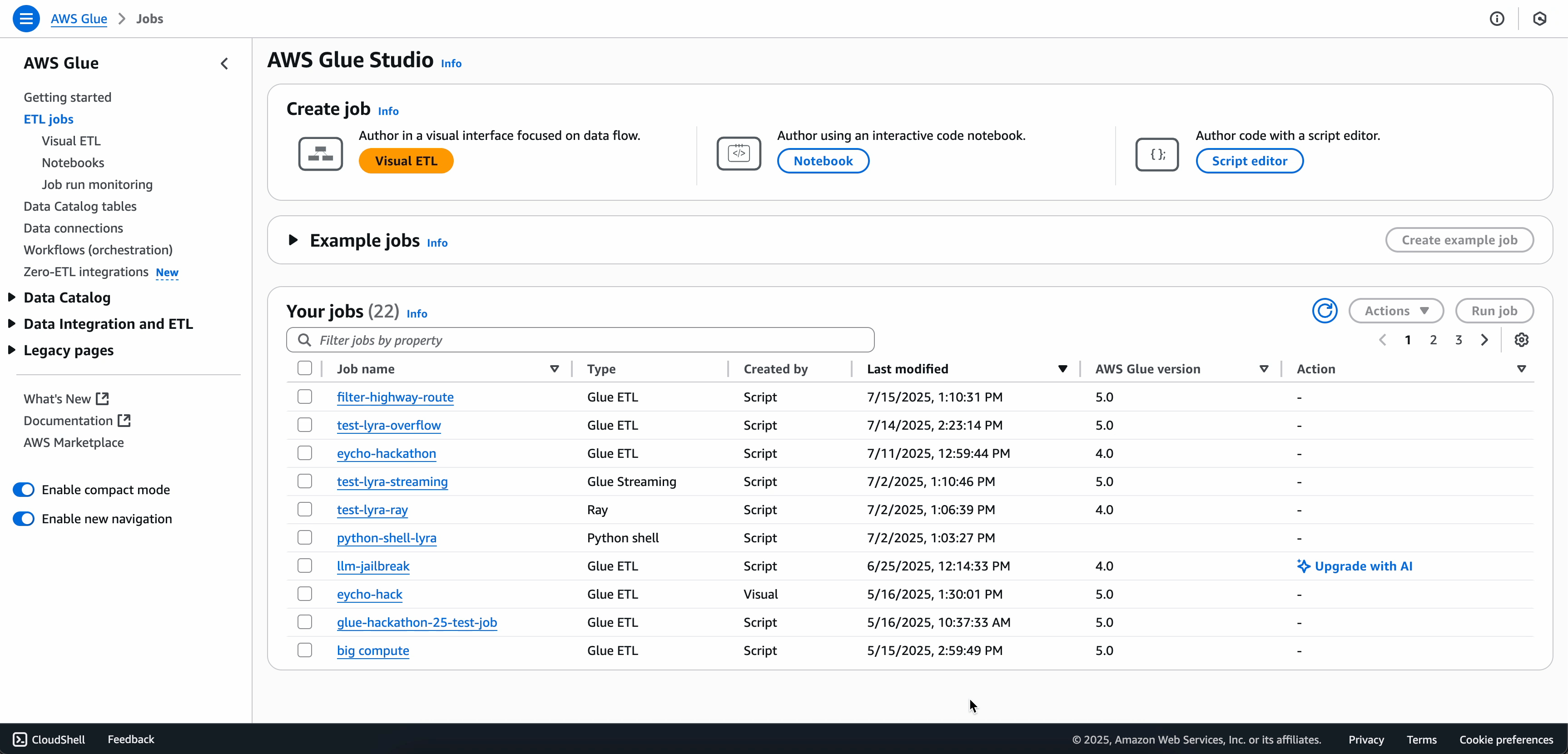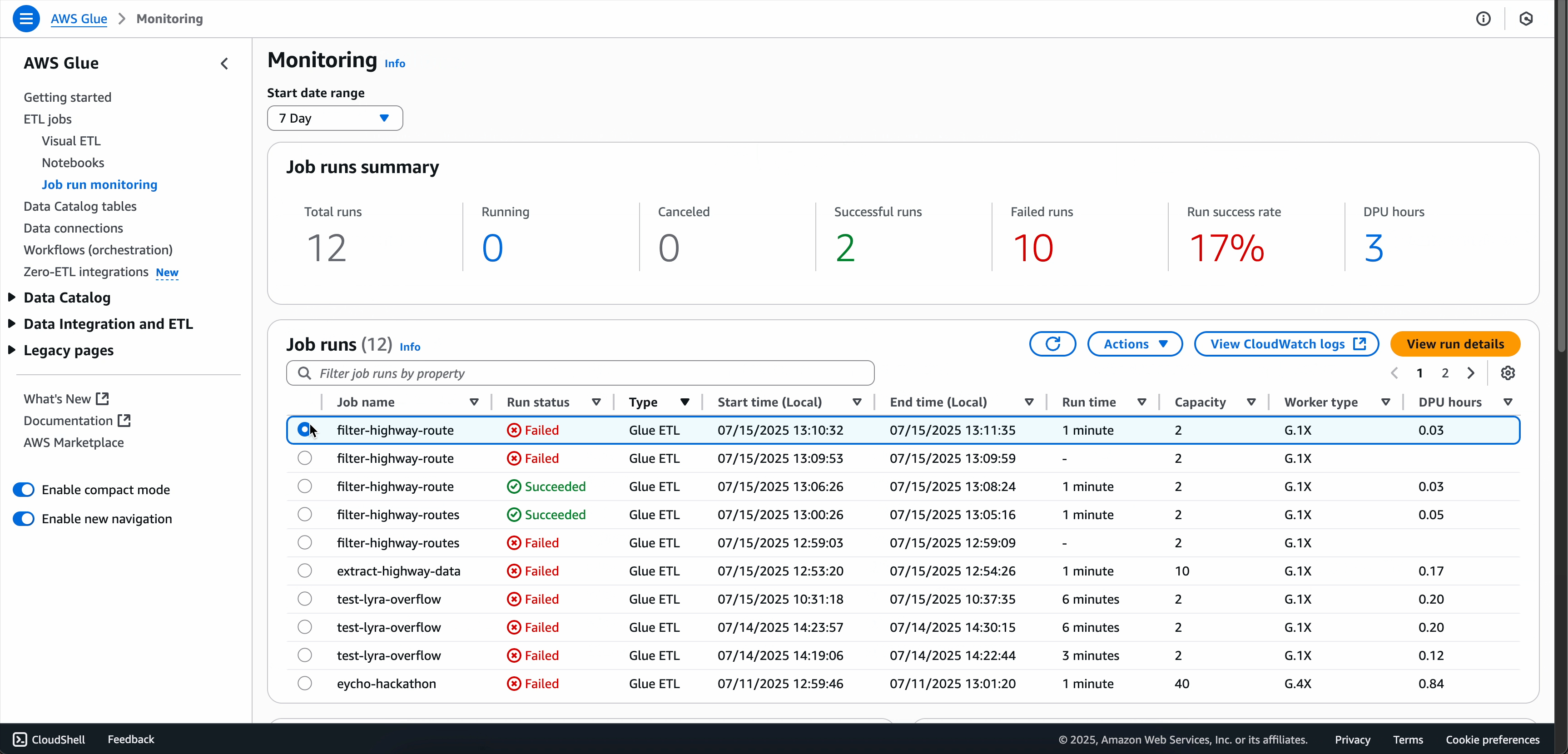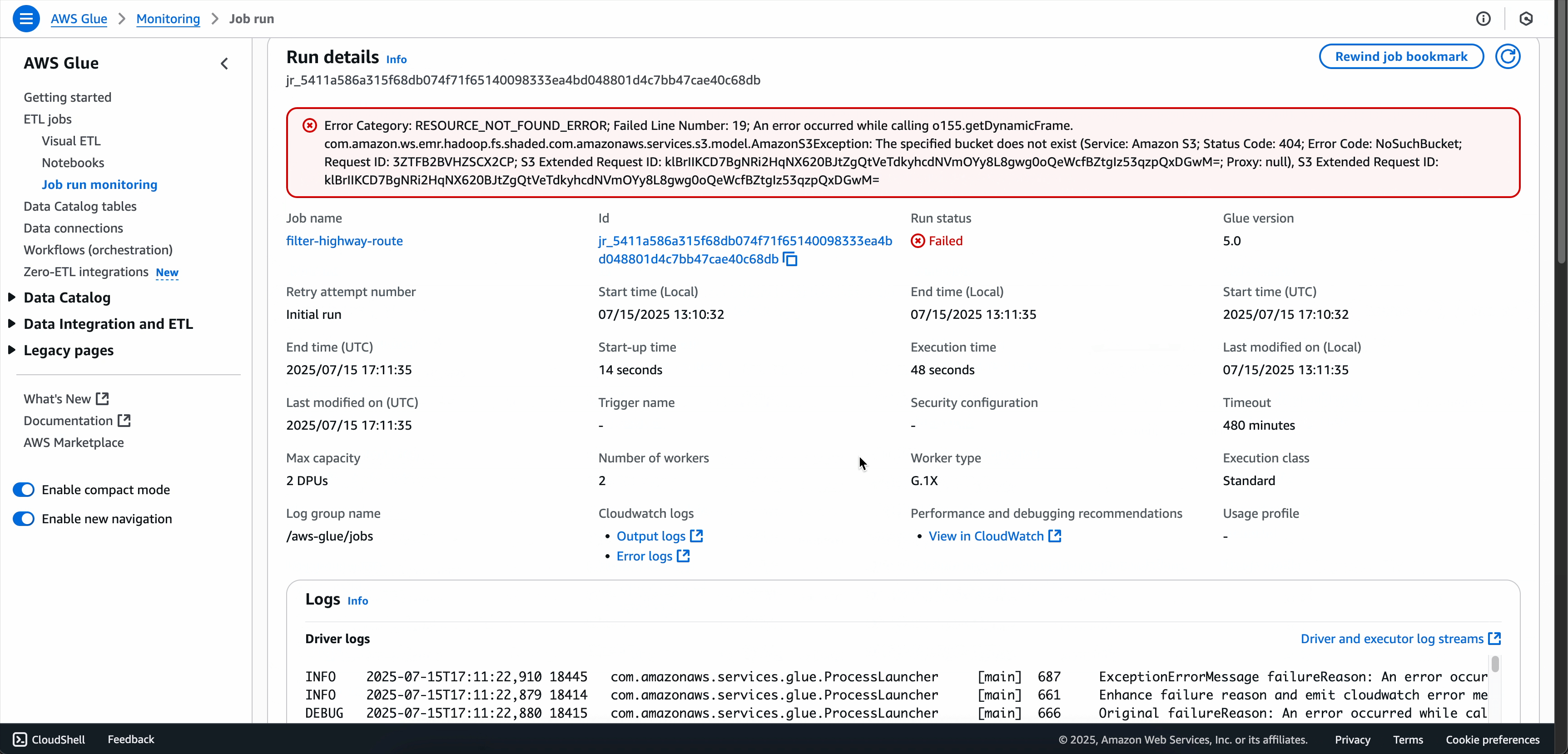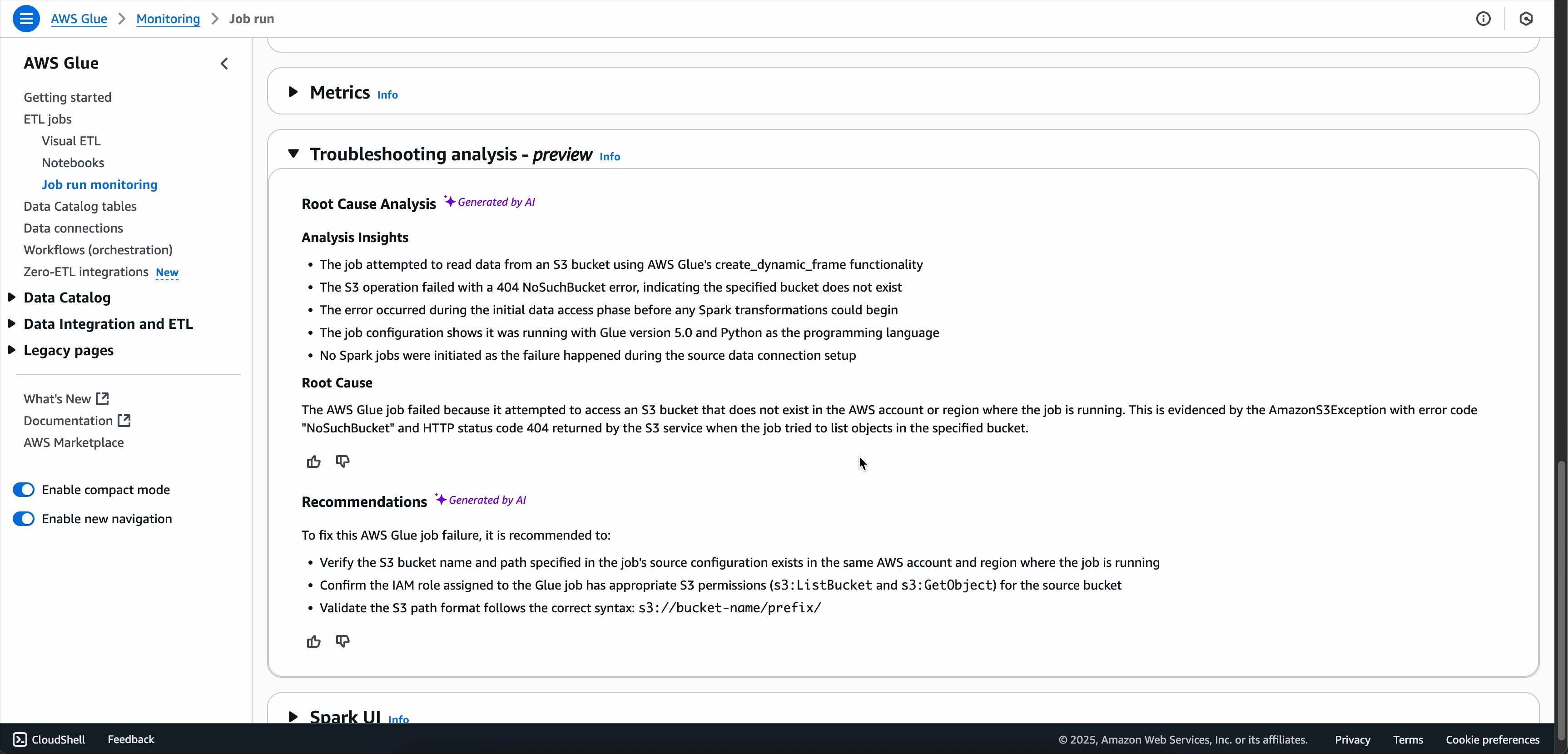
For your failed Spark jobs, Generative AI Troubleshooting analyzes the job metadata and the precise metrics and logs associated with the error signature of your job to generate a root cause analysis, and recommends specific solutions and best practices to help address job failures.
Setting up Generative AI Troubleshooting for Apache Spark for your jobs
Configuring IAM permissions
Granting permissions to the APIs used by Spark Troubleshooting for your jobs in Amazon Glue requires appropriate IAM permissions. You can obtain permissions by attaching the following custom Amazon policy to your IAM identity (such as a user, role, or group).
Note
The following two APIs are used in the IAM policy for enabling this experience through the Amazon Glue Studio Console:
StartCompletion and GetCompletion.
Assigning permissions
To provide access, add permissions to your users, groups, or roles:
-
For users and groups in IAM Identity Center: Create a permission set. Follow the instructions in Create a permission set
in the IAM Identity Center User Guide. -
For users managed in IAM through an identity provider: Create a role for identity federation. Follow the instructions in Creating a role for a third-party identity provider (federation)
in the IAM User Guide. -
For IAM users: Create a role that your user can assume. Follow the instructions in Creating a role for an IAM user
in the IAM User Guide.
Running troubleshooting analysis from a failed job run
You can access the troubleshooting feature through multiple paths in the Amazon Glue console. Here's how to get started:
Option 1: From the Jobs List page
-
Open the Amazon Glue console at https://console.aws.amazon.com/glue/
. -
In the navigation pane, choose ETL Jobs.
-
Locate your failed job in the jobs list.
-
Select the Runs tab in the job details section.
-
Click on the failed job run you want to analyze.
-
Choose Troubleshoot with AI to start the analysis.
-
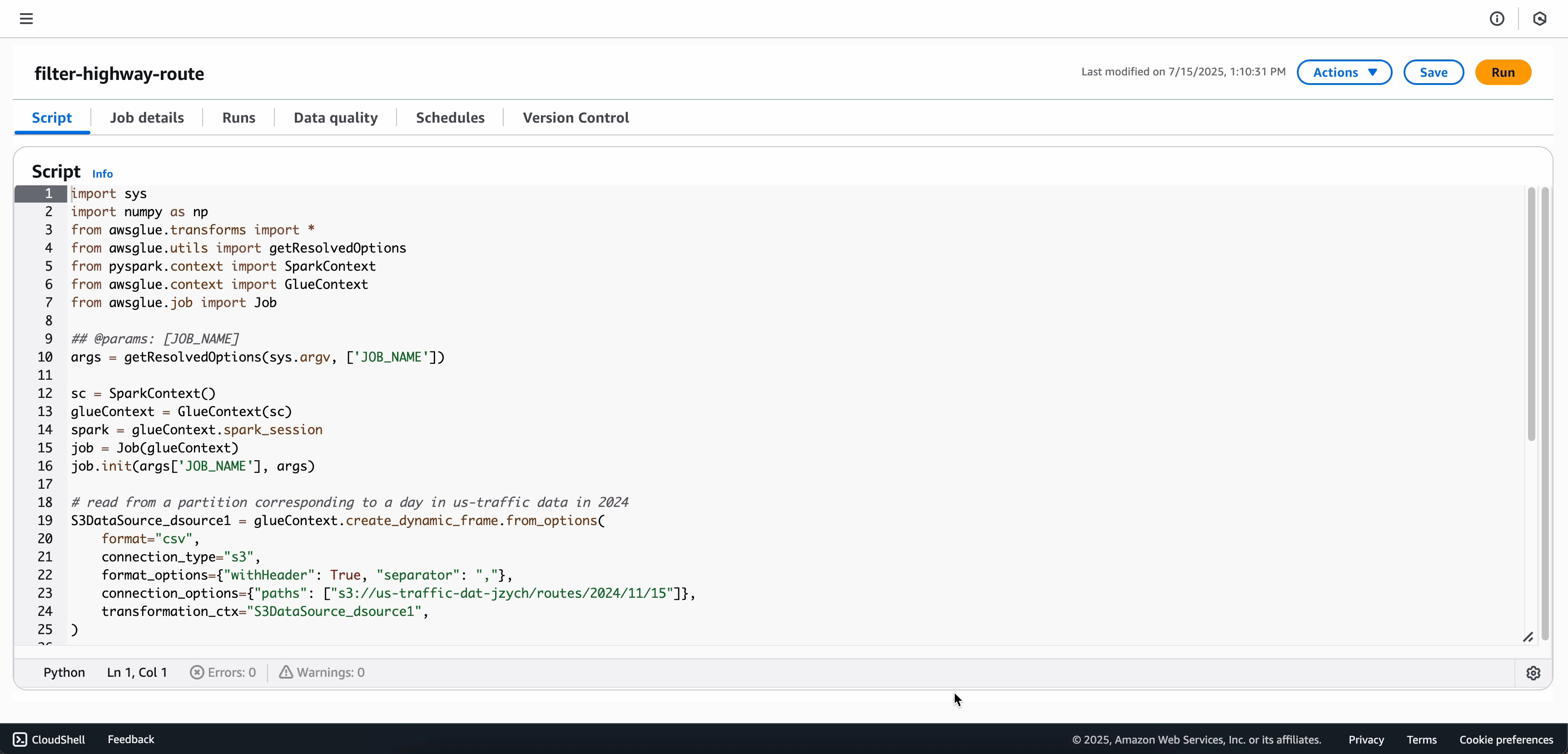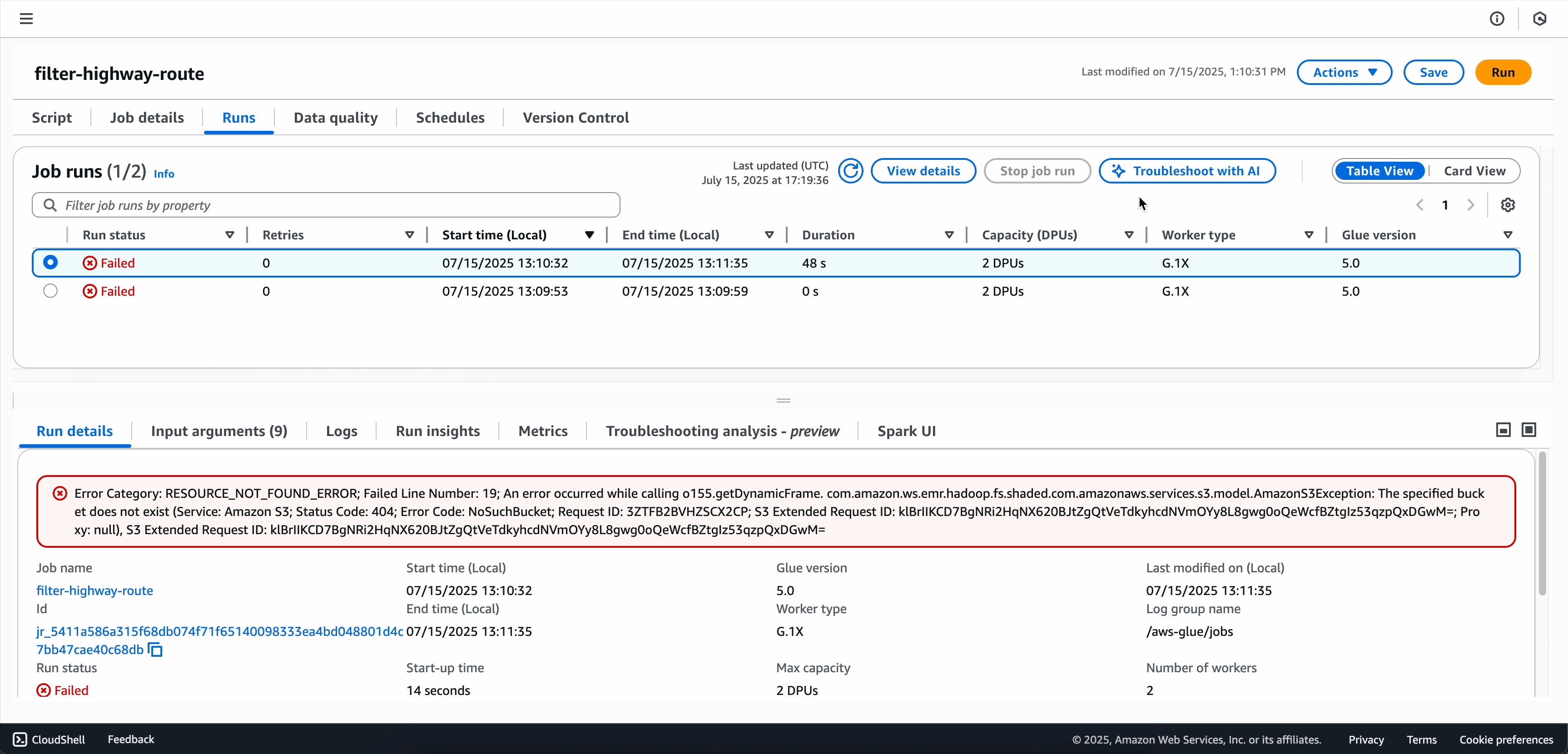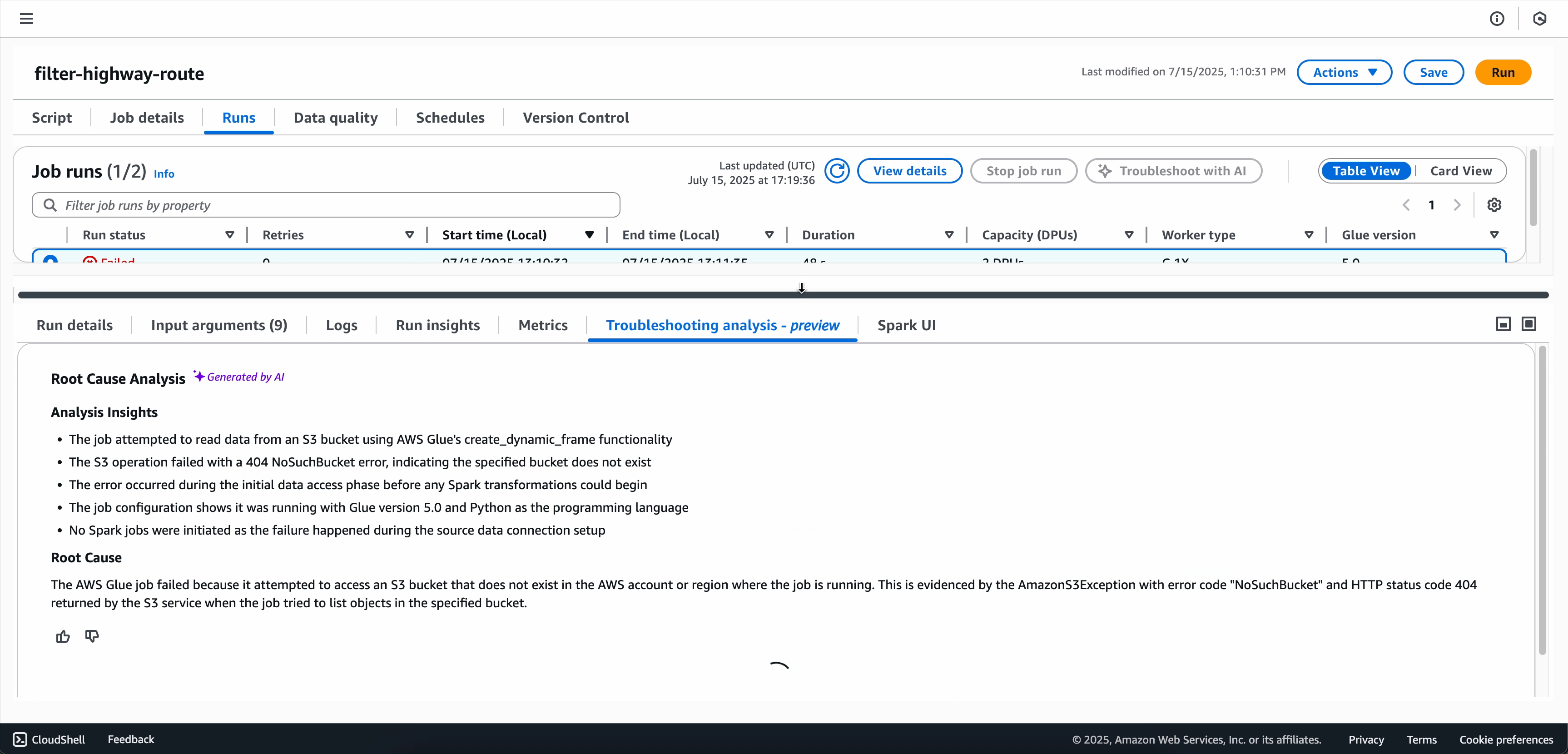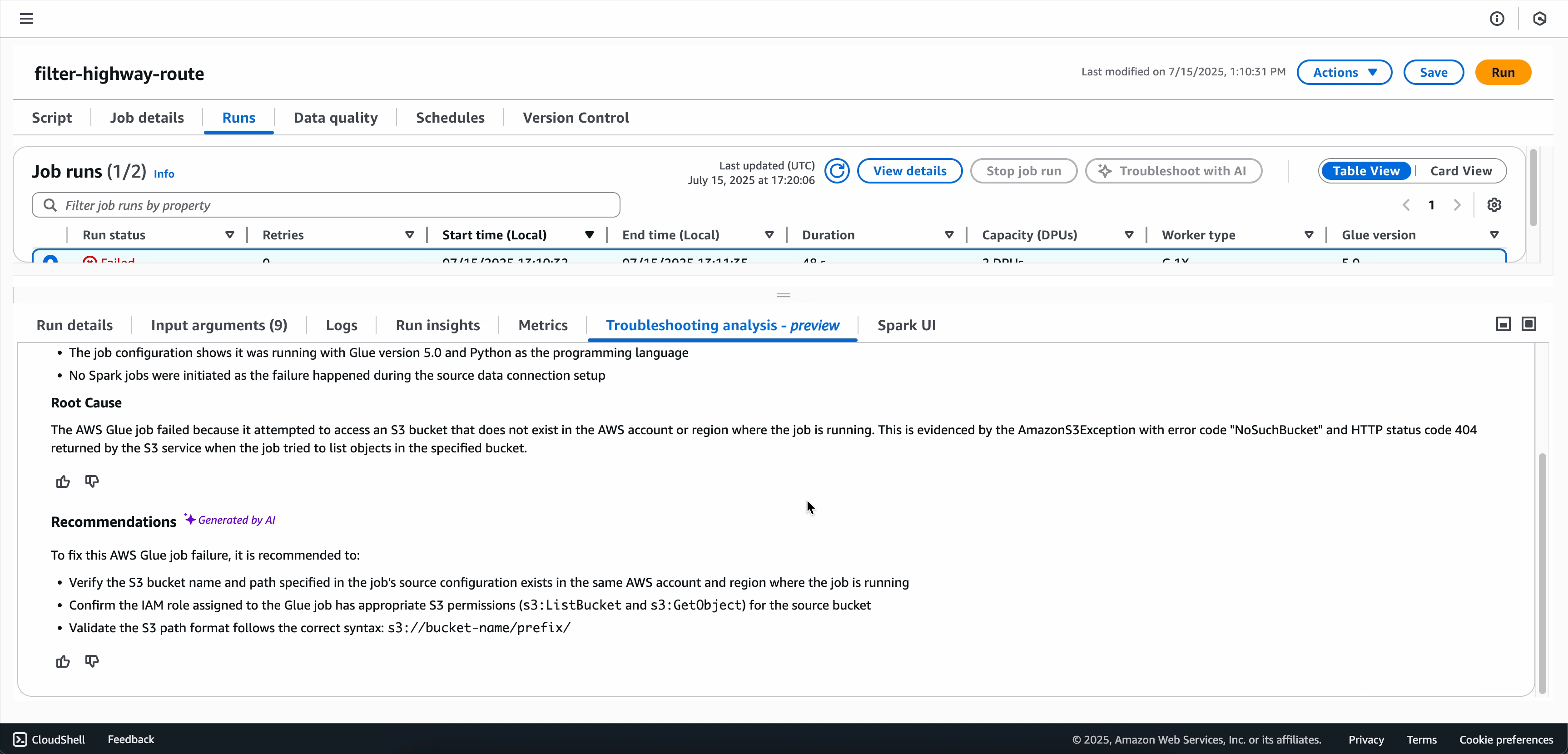
When the troubleshooting analysis is complete, you can view the root-cause analysis and recommendations in the Troubleshooting analysis tab at the bottom of the screen.
Option 2: Using the Job Run Monitoring page
-
Navigate to the Job run monitoring page.
-
Locate your failed job run.
-
Choose the Actions drop-down menu.
-
Choose Troubleshoot with AI.
Option 3: From the Job Run Details page
-
Navigate to your failed job run's details page by either clicking View details on a failed run from the Runs tab or selecting the job run from the Job run monitoring page.
-
In the job run details page, find the Troubleshooting analysis tab.
Supported troubleshooting categories
This service focuses on three primary categories of issues that data engineers and developers frequently encounter in their Spark applications:
-
Resource setup and access errors: When running Spark applications in Amazon Glue, resource setup and access errors are among the most common yet challenging issues to diagnose. These errors often occur when your Spark application attempts to interact with Amazon resources but encounters permission issues, missing resources, or configuration problems.
-
Spark driver and executor memory issues: Memory-related errors in Apache Spark jobs can be complex to diagnose and resolve. These errors often manifest when your data processing requirements exceed the available memory resources, either on the driver node or executor nodes.
-
Spark disk capacity issues: Storage-related errors in Amazon Glue Spark jobs often emerge during shuffle operations, data spilling, or when dealing with large-scale data transformations. These errors can be particularly tricky because they might not manifest until your job has been running for a while, potentially wasting valuable compute time and resources.
-
Query execution errors: Query failures in Spark SQL and DataFrame operations can be difficult to troubleshoot because error messages may not clearly point to the root cause, and queries that work fine with small datasets can suddenly fail at scale. These errors become even more challenging when they occur deep within complex transformation pipelines, where the actual issue may stem from data quality problems in earlier stages rather than the query logic itself.
Note
Before implementing any suggested changes in your production environment, review the suggested changes thoroughly. The service provides recommendations based on patterns and best practices, but your specific use case might require additional considerations.
Supported regions
Generative AI troubleshooting for Apache Spark is available in the following regions:
-
Africa: Cape Town (af-south-1)
-
Asia Pacific: Hong Kong (ap-east-1), Tokyo (ap-northeast-1), Seoul (ap-northeast-2), Osaka (ap-northeast-3), Mumbai (ap-south-1), Singapore (ap-southeast-1), Sydney (ap-southeast-2), and Jakarta (ap-southeast-3)
-
Europe: Frankfurt (eu-central-1), Stockholm (eu-north-1), Milan (eu-south-1), Ireland (eu-west-1), London (eu-west-2), and Paris (eu-west-3)
-
Middle East: Bahrain (me-south-1) and UAE (me-central-1)
-
North America: Canada (ca-central-1)
-
South America: São Paulo (sa-east-1)
-
United States: North Virginia (us-east-1), Ohio (us-east-2), North California (us-west-1), and Oregon (us-west-2)