After careful consideration, we have decided to discontinue Amazon Kinesis Data Analytics for SQL applications:
1. From September 1, 2025, we won't provide any bug fixes for Amazon Kinesis Data Analytics for SQL applications because we will have limited support for it, given the upcoming discontinuation.
2. From October 15, 2025, you will not be able to create new Kinesis Data Analytics for SQL applications.
3. We will delete your applications starting January 27, 2026. You will not be able to start or operate your Amazon Kinesis Data Analytics for SQL applications. Support will no longer be available for Amazon Kinesis Data Analytics for SQL from that time. For more information, see Amazon Kinesis Data Analytics for SQL Applications discontinuation.
Example: Aggregating Partial Results from a Query
If an Amazon Kinesis data stream contains records that have an event time that does not exactly match ingestion time, a selection of results in a tumbling window contains records that arrived, but did not necessarily occur, within the window. In this case, the tumbling window contains only a partial set of the results that you want. There are several approaches that you can use to correct this issue:
-
Use a tumbling window only, and aggregate partial results in post processing through a database or data warehouse using upserts. This approach is efficient in processing an application. It handles the late data indefinitely for aggregate operators (
sum,min,max, and so on). The downside to this approach is that you must develop and maintain additional application logic in the database layer. -
Use a tumbling and sliding window, which produces partial results early, but also continues to produce complete results over the sliding window period. This approach handles late data with an overwrite instead of an upsert so that no additional application logic needs to be added in the database layer. The downside to this approach is that it uses more Kinesis processing units (KPUs) and still produces two results, which might not work for some use cases.
For more information about tumbling and sliding windows, see Windowed Queries.
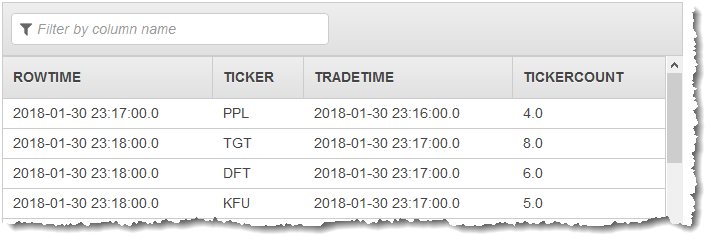
In the following procedure, the tumbling window aggregation produces two partial
results (sent to the CALC_COUNT_SQL_STREAM in-application stream) that must
be combined to produce a final result. The application then produces a second
aggregation (sent to the DESTINATION_SQL_STREAM in-application stream) that
combines the two partial results.
To create an application that aggregates partial results using an event time
Sign in to the Amazon Web Services Management Console and open the Kinesis console at https://console.amazonaws.cn/kinesis
. -
Choose Data Analytics in the navigation pane. Create a Kinesis Data Analytics application as described in the Getting Started with Amazon Kinesis Data Analytics for SQL Applications tutorial.
-
In the SQL editor, replace the application code with the following:
CREATE OR REPLACE STREAM "CALC_COUNT_SQL_STREAM" (TICKER VARCHAR(4), TRADETIME TIMESTAMP, TICKERCOUNT DOUBLE); CREATE OR REPLACE STREAM "DESTINATION_SQL_STREAM" (TICKER VARCHAR(4), TRADETIME TIMESTAMP, TICKERCOUNT DOUBLE); CREATE PUMP "CALC_COUNT_SQL_PUMP_001" AS INSERT INTO "CALC_COUNT_SQL_STREAM" ("TICKER","TRADETIME", "TICKERCOUNT") SELECT STREAM "TICKER_SYMBOL", STEP("SOURCE_SQL_STREAM_001"."ROWTIME" BY INTERVAL '1' MINUTE) as "TradeTime", COUNT(*) AS "TickerCount" FROM "SOURCE_SQL_STREAM_001" GROUP BY STEP("SOURCE_SQL_STREAM_001".ROWTIME BY INTERVAL '1' MINUTE), STEP("SOURCE_SQL_STREAM_001"."APPROXIMATE_ARRIVAL_TIME" BY INTERVAL '1' MINUTE), TICKER_SYMBOL; CREATE PUMP "AGGREGATED_SQL_PUMP" AS INSERT INTO "DESTINATION_SQL_STREAM" ("TICKER","TRADETIME", "TICKERCOUNT") SELECT STREAM "TICKER", "TRADETIME", SUM("TICKERCOUNT") OVER W1 AS "TICKERCOUNT" FROM "CALC_COUNT_SQL_STREAM" WINDOW W1 AS (PARTITION BY "TRADETIME" RANGE INTERVAL '10' MINUTE PRECEDING);The
SELECTstatement in the application code filters rows in theSOURCE_SQL_STREAM_001for stock price changes greater than 1 percent and inserts those rows into another in-application streamCHANGE_STREAMusing a pump. -
Choose Save and run SQL.
The first pump outputs a stream to CALC_COUNT_SQL_STREAM similar to the
following. Note that the result set is incomplete:
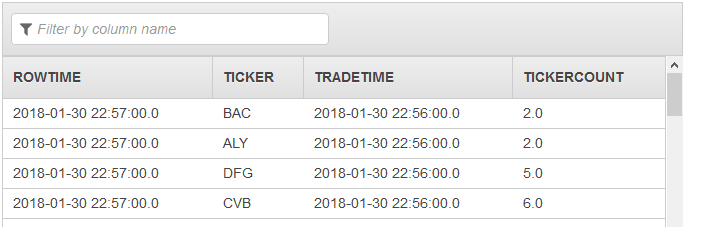
The second pump then outputs a stream to DESTINATION_SQL_STREAM that
contains the complete result set: