After careful consideration, we have decided to discontinue Amazon Kinesis Data Analytics for SQL applications:
1. From September 1, 2025, we won't provide any bug fixes for Amazon Kinesis Data Analytics for SQL applications because we will have limited support for it, given the upcoming discontinuation.
2. From October 15, 2025, you will not be able to create new Kinesis Data Analytics for SQL applications.
3. We will delete your applications starting January 27, 2026. You will not be able to start or operate your Amazon Kinesis Data Analytics for SQL applications. Support will no longer be available for Amazon Kinesis Data Analytics for SQL from that time. For more information, see Amazon Kinesis Data Analytics for SQL Applications discontinuation.
Stagger Windows
Using stagger windows is a windowing method that is suited for analyzing groups of data that arrive at inconsistent times. It is well suited for any time-series analytics use case, such as a set of related sales or log records.
For example, VPC Flow Logs have a capture window of approximately 10 minutes. But they can have a capture window of up to 15 minutes if you're aggregating data on the client. Stagger windows are ideal for aggregating these logs for analysis.
Stagger windows address the issue of related records not falling into the same time-restricted window, such as when tumbling windows were used.
Partial Results with Tumbling Windows
There are certain limitations with using Tumbling Windows for aggregating late or out-of-order data.
If tumbling windows are used to analyze groups of time-related data, the individual records might fall into separate windows. So then the partial results from each window must be combined later to yield complete results for each group of records.
In the following tumbling window query, records are grouped into windows by row time, event time, and ticker symbol:
CREATE OR REPLACE STREAM "DESTINATION_SQL_STREAM" ( TICKER_SYMBOL VARCHAR(4), EVENT_TIME timestamp, TICKER_COUNT DOUBLE); CREATE OR REPLACE PUMP "STREAM_PUMP" AS INSERT INTO "DESTINATION_SQL_STREAM" SELECT STREAM TICKER_SYMBOL, FLOOR(EVENT_TIME TO MINUTE), COUNT(TICKER_SYMBOL) AS TICKER_COUNT FROM "SOURCE_SQL_STREAM_001" GROUP BY ticker_symbol, FLOOR(EVENT_TIME TO MINUTE), STEP("SOURCE_SQL_STREAM_001".ROWTIME BY INTERVAL '1' MINUTE);
In the following diagram, an application is counting the number of trades it receives, based on when the trades happened (event time) with one minute of granularity. The application can use a tumbling window for grouping data based on row time and event time. The application receives four records that all arrive within one minute of each other. It groups the records by row time, event time, and ticker symbol. Because some of the records arrive after the first tumbling window ends, the records do not all fall within the same one-minute tumbling window.
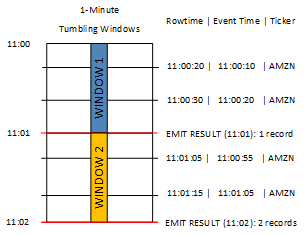
The preceding diagram has the following events.
| ROWTIME | EVENT_TIME | TICKER_SYMBOL |
|---|---|---|
| 11:00:20 | 11:00:10 | AMZN |
| 11:00:30 | 11:00:20 | AMZN |
| 11:01:05 | 11:00:55 | AMZN |
| 11:01:15 | 11:01:05 | AMZN |
The result set from the tumbling window application looks similar to the following.
| ROWTIME | EVENT_TIME | TICKER_SYMBOL | COUNT |
|---|---|---|---|
| 11:01:00 | 11:00:00 | AMZN | 2 |
| 11:02:00 | 11:00:00 | AMZN | 1 |
| 11:02:00 | 11:01:00 | AMZN | 1 |
In the result set preceding, three results are returned:
A record with a
ROWTIMEof 11:01:00 that aggregates the first two records.A record at 11:02:00 that aggregates just the third record. This record has a
ROWTIMEwithin the second window, but anEVENT_TIMEwithin the first window.A record at 11:02:00 that aggregates just the fourth record.
To analyze the complete result set, the records must be aggregated in the persistence store. This adds complexity and processing requirements to the application.
Complete Results with Stagger Windows
To improve the accuracy of analyzing time-related data records, Kinesis Data Analytics offers a new window type called stagger windows. In this window type, windows open when the first event matching the partition key arrives, and not on a fixed time interval. The windows close based on the age specified, which is measured from the time when the window opened.
A stagger window is a separate time-restricted window for each key grouping in a window clause. The application aggregates each result of the window clause inside its own time window, rather than using a single window for all results.
In the following stagger window query, records are grouped into windows by event time and ticker symbol:
CREATE OR REPLACE STREAM "DESTINATION_SQL_STREAM" ( ticker_symbol VARCHAR(4), event_time TIMESTAMP, ticker_count DOUBLE); CREATE OR REPLACE PUMP "STREAM_PUMP" AS INSERT INTO "DESTINATION_SQL_STREAM" SELECT STREAM TICKER_SYMBOL, FLOOR(EVENT_TIME TO MINUTE), COUNT(TICKER_SYMBOL) AS ticker_count FROM "SOURCE_SQL_STREAM_001" WINDOWED BY STAGGER ( PARTITION BY FLOOR(EVENT_TIME TO MINUTE), TICKER_SYMBOL RANGE INTERVAL '1' MINUTE);
In the following diagram, events are aggregated by event time and ticker symbol into stagger windows.
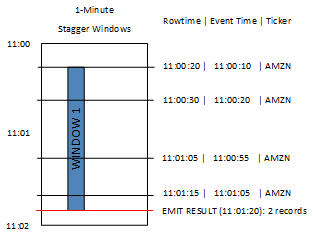
The preceding diagram has the following events, which are the same events as the tumbling window application analyzed:
| ROWTIME | EVENT_TIME | TICKER_SYMBOL |
|---|---|---|
| 11:00:20 | 11:00:10 | AMZN |
| 11:00:30 | 11:00:20 | AMZN |
| 11:01:05 | 11:00:55 | AMZN |
| 11:01:15 | 11:01:05 | AMZN |
The result set from the stagger window application looks similar to the following.
| ROWTIME | EVENT_TIME | TICKER_SYMBOL | Count |
|---|---|---|---|
| 11:01:20 | 11:00:00 | AMZN | 3 |
| 11:02:15 | 11:01:00 | AMZN | 1 |
The returned record aggregates the first three input records. The records are grouped by
one-minute stagger windows. The stagger window starts when the application receives the
first AMZN record (with a ROWTIME of 11:00:20). When the 1-minute stagger
window expires (at 11:01:20), a record with the results that fall within the stagger
window (based on ROWTIME and EVENT_TIME) is written to the
output stream. Using a stagger window, all of the records with a ROWTIME
and EVENT_TIME within a one-minute window are emitted in a single
result.
The last record (with an EVENT_TIME outside the one-minute aggregation)
is aggregated separately. This is because EVENT_TIME is one of the
partition keys that is used to separate the records into result sets, and the partition
key for EVENT_TIME for the first window is 11:00.
The syntax for a stagger window is defined in a special clause, WINDOWED BY.
This clause is used instead of the GROUP BY clause for streaming
aggregations. The clause appears immediately after the optional WHERE
clause and before the HAVING clause.
The stagger window is defined in the WINDOWED BY clause and takes two
parameters: partition keys and window length. The partition keys partition the incoming
data stream and define when the window opens. A stagger window opens when the first
event with a unique partition key appears on the stream. The stagger window closes after
a fixed time period defined by the window length. The syntax is shown in the following
code example:
... FROM <stream-name> WHERE <... optional statements...> WINDOWED BY STAGGER( PARTITION BY <partition key(s)> RANGE INTERVAL <window length, interval> );