Amazon S3 Tables integration with Amazon Glue Data Catalog and Amazon Lake Formation
Amazon S3 Tables provide S3 storage that's specifically optimized for analytics workloads, improving query performance while reducing costs. The data in S3 Tables is stored in a new bucket type: a table bucket, which stores tables as subresources. S3 tables have built-in support for Apache Iceberg standard, which allows you to easily query tabular data in Amazon S3 table buckets using popular query engines like Apache Spark.
You can integrate Amazon S3 Tables with Amazon Glue Data Catalog using either IAM access controls or with IAM and Lake Formation grants:
-
IAM access control: Uses IAM policies to control access to S3 Tables and Data Catalog. In this access control approach, you need IAM permissions on both S3 Tables resources and Data Catalog objects to access resources.
-
Lake Formation access control: Uses Amazon Lake Formation grants in addition to Amazon Glue IAM permissions to control access to S3 Tables through the Data Catalog. In this mode, principals require IAM permissions to interact with the Data Catalog, and Lake Formation grants determine which catalog resources (databases, tables, columns, rows) the principal can access. This mode supports both coarse-grained access control (database-level and table-level grants) and fine-grained access control (column-level and row-level security). When a registered role is configured and credential vending is enabled, S3 Tables IAM permissions are not required for the principal, as Lake Formation vends credentials on behalf of the principal using the registered role. Lake Formation access control also supports credential vending for third-party analytics engines.
This section provides guidance to configure the integration with Amazon Lake Formation for the following scenarios:
-
Scenario A: You integrated S3 Tables and Data Catalog using IAM access controls and now plan to use Amazon Lake Formation. See Changing access controls for S3 Tables integration to learn more.
-
Scenario B: You plan to integrate S3 Tables and Data Catalog using Amazon Lake Formation and do not have them integrated in your account and Region today. Start with the Prerequisites for integrating Amazon S3 tables catalog with the Data Catalog and Lake Formation section and follow Enabling Amazon S3 Tables integration.
-
Scenario C: You integrated S3 Tables and Data Catalog using Amazon Lake Formation and now plan to use IAM. See Changing access controls for S3 Tables integration to learn more.
Make sure that you follow the steps in Integrating S3 Tables with Amazon analytics services so that you have the appropriate permissions to access the Amazon Glue Data Catalog and your table resources, and to work with Amazon analytics services.
Topics
How Data Catalog and Lake Formation integration works
When you integrate the S3 tables catalog with the Data Catalog and Lake Formation, the
Amazon Glue service creates a single federated catalog called s3tablescatalog in
your account's default Data Catalog specific to your Amazon Web Services Region. The integration maps all Amazon S3 table bucket
resources in your account and Amazon Web Services Region under the federated catalog in the following
manner:
Amazon S3 table buckets become a multi-level catalog in the Data Catalog.
-
The associated Amazon S3 namespace is registered as a database in the Data Catalog.
-
The Amazon S3 tables in the table bucket becomes tables in the Data Catalog.
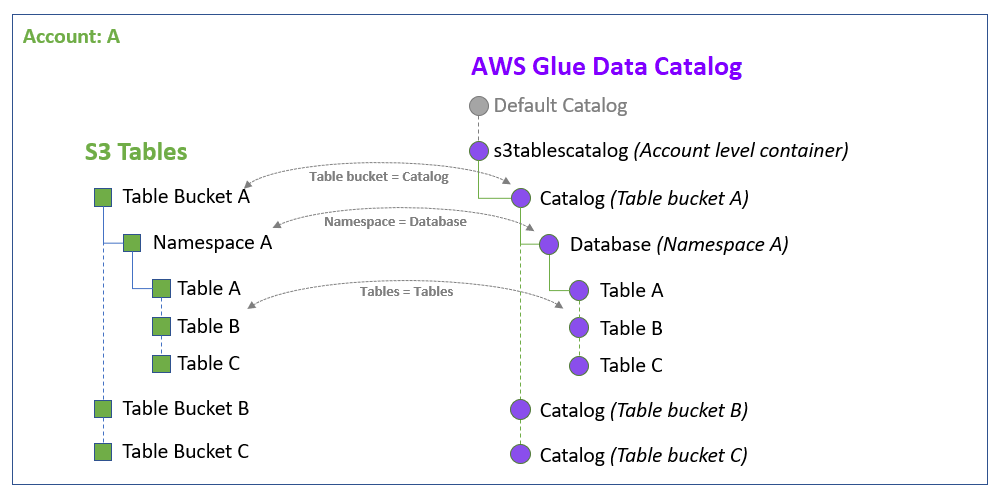
After integrating with Lake Formation, you can create Apache Iceberg tables in the table buckets catalog, and access them via integrated Amazon analytics engines such as Amazon Athena, Amazon EMR as well as third-party analytics engines.
When you also enable Lake Formation with integration, it enables fine-grained access control through Amazon Lake Formation. This security approach means that, in addition to Amazon Identity and Access Management (IAM) permissions, you must grant your IAM principal with Lake Formation permissions on your tables before you can work with them.
There are two main types of permissions in Amazon Lake Formation:
-
Metadata access permissions control the ability to create, read, update, and delete metadata databases and tables in the Data Catalog.
-
Underlying data access permissions control the ability to read and write data to the underlying Amazon S3 locations that the Data Catalog resources point to.
Lake Formation uses a combination of its own permissions model and the IAM permissions model to control access to Data Catalog resources and underlying data:
-
For a request to access Data Catalog resources or underlying data to succeed, the request must pass permission checks by both IAM and Lake Formation.
-
IAM permissions control access to the Lake Formation and Amazon Glue APIs and resources, whereas Lake Formation permissions control access to the Data Catalog resources, Amazon S3 locations, and the underlying data.
Lake Formation permissions apply only in the Region in which they were granted, and a principal must be authorized by a data lake administrator or another principal with the necessary permissions in order to be granted Lake Formation permissions.