Managing a data lake using Lake Formation tag-based access control
Thousands of customers are building petabyte-scale data lakes on Amazon. Many of these customers use Amazon Lake Formation to easily build and share their data lakes across the organization. As the number of tables and users increase, data stewards and administrators are looking for ways to manage permissions on data lakes easily at scale. Lake Formation Tag-based access control (LF-TBAC) solves this problem by allowing data stewards to create LF-tags (based on their data classification and ontology) that can then be attached to resources.
LF-TBAC is an authorization strategy that defines permissions based on attributes. In Lake Formation, these attributes are called LF-tags. You can attach LF-tags to Data Catalog resources and Lake Formation principals. Data lake administrators can assign and revoke permissions on Lake Formation resources using LF-tags. For more information about see, Lake Formation tag-based access control.
This tutorial demonstrates how to create a Lake Formation tag-based access control policy using an Amazon public dataset. In addition, it shows how to query tables, databases, and columns that have Lake Formation tag-based access policies associated with them.
You can use LF-TBAC for the following use cases:
You have a large number of tables and principals that the data lake administrator has to grant access
You want to classify your data based on an ontology and grant permissions based on classification
The data lake administrator wants to assign permissions dynamically, in a loosely coupled way
Following are the high-level steps for configuring permissions using LF-TBAC:
-
The data steward defines the tag ontology with two LF-tags:
ConfidentialandSensitive. Data withConfidential=Truehas tighter access controls. Data withSensitive=Truerequires specific analysis from the analyst. -
The data steward assigns different permission levels to the data engineer to build tables with different LF-tags.
-
The data engineer builds two databases:
tag_databaseandcol_tag_database. All tables intag_databaseare configured withConfidential=True. All tables in thecol_tag_databaseare configured withConfidential=False. Some columns of the table incol_tag_databaseare tagged withSensitive=Truefor specific analysis needs. The data engineer grants read permission to the analyst for tables with specific expression condition
Confidential=TrueandConfidential=False,Sensitive=True.-
With this configuration, the data analyst can focus on performing analysis with the right data.
Topics
Intended audience
This tutorial is intended for data stewards, data engineers, and data analysts. When it comes to managing Amazon Glue Data Catalog and administering permission in Lake Formation, data stewards within the producing accounts have functional ownership based on the functions they support, and can grant access to various consumers, external organizations, and accounts.
The following table lists the roles that are used in this tutorial:
| Role | Description |
|---|---|
| Data steward (administrator) | The lf-data-steward user has the following access:
|
| Data engineer |
|
| Data analyst | The lf-data-analyst user has the following access:
|
Prerequisites
Before you start this tutorial, you must have an Amazon Web Services account that you can use to sign in as an administrative user with correct permissions. For more information, see Complete initial Amazon configuration tasks.
The tutorial assumes that you are familiar with IAM. For information about IAM, see the IAM User Guide
Step 1: Provision your resources
This tutorial includes an Amazon CloudFormation template for a quick setup. You can review and customize it to suit your needs. The template creates three different roles (listed in Intended audience) to perform this exercise and copies the nyc-taxi-data dataset to your local Amazon S3 bucket.
An Amazon S3 bucket
The appropriate Lake Formation settings
The appropriate Amazon EC2 resources
Three IAM roles with credentials
Create your resources
Sign into the Amazon CloudFormation console at https://console.amazonaws.cn/cloudformation
in the US East (N. Virginia) region. Choose Launch Stack
. -
Choose Next.
-
In the User Configuration section, enter password for three roles:
DataStewardUserPassword,DataEngineerUserPasswordandDataAnalystUserPassword. Review the details on the final page and select I acknowledge that Amazon CloudFormation might create IAM resources.
Choose Create.
The stack creation can take up to five minutes.
Note
After you complete the tutorial, you might want to delete the stack in Amazon CloudFormation to avoid continuing to incur charges. Verify that the resources are successfully deleted in the event status for the stack.
Step 2: Register your data location, create an LF-Tag ontology, and grant permissions
In this step, the data steward user defines the tag ontology with two LF-Tags:
Confidential and Sensitive, and gives specific IAM principals
the ability to attach newly created LF-Tags to resources.
Register a data location and define LF-Tag ontology
Perform the first step as the data steward user (
lf-data-steward) to verify the data in Amazon S3 and the Data Catalog in Lake Formation.Sign in to the Lake Formation console at https://console.amazonaws.cn/lakeformation/
as lf-data-stewardwith the password used while deploying the Amazon CloudFormation stack.In the navigation pane, under Permissions¸ choose Administrative roles and tasks.
Choose Add in the Data lake administrators section.
On the Add administrator page, for IAM users and roles, choose the user
lf-data-steward.Choose Save to add
lf-data-stewardas a Lake Formation administrator.
-
Next, update the Data Catalog settings to use Lake Formation permission to control catalog resources instead of IAM based access control.
In the navigation pane, under Administration, choose Data Catalog settings.
Uncheck Use only IAM access control for new databases.
Uncheck Use only IAM access control for new tables in new databases.
Click Save.
Next, register the data location for the data lake.
In the navigation pane, under Administration, choose Data lake locations.
Choose Register location.
On the Register location page, for Amazon S3 path, enter
s3://lf-tagbased-demo-.Account-IDFor IAM role¸ leave the default value
AWSServiceRoleForLakeFormationDataAccessas it is.Choose Lake Formation as the permission mode.
Choose Register location.
-
Next, create the ontology by defining an LF-tag.
Under Permissions in the navigation pane, choose LF-Tags and permissions..
Choose Add LF-Tag.
For Key, enter
Confidential.For Values, add
TrueandFalse.Choose Add LF-tag.
-
Repeat the steps to create the LF-Tag
Sensitivewith the valueTrue.
You have created all the necessary LF-Tags for this exercise.
Grant permissions to IAM users
-
Next, give specific IAM principals the ability to attach newly created LF-tags to resources.
Under Permissions in the navigation pane, choose LF-Tags and permissions.
In the LF-Tag permissions section, choose Grant permissions.
For Permission type, choose LF-Tag key-value pair permissions.
Select IAM users and roles.
For IAM users and roles, search for and choose the
lf-data-engineerrole.In the LF-Tags section, add the key
Confidentialwith valuesTrueandFalse, and thekeySensitivewith valueTrue.Under Permissions, select Describe and Associate for Permissions and Grantable permissions.
Choose Grant.
-
Next, grant permissions to
lf-data-engineerto create databases in our Data Catalog and on the underlying Amazon S3 bucket created by Amazon CloudFormation.Under Administration in the navigation pane, choose Administrative roles and tasks.
In the Database creators section, choose Grant.
For IAM users and roles, choose the
lf-data-engineerrole.For Catalog permissions, select Create database.
Choose Grant.
-
Next, grant permissions on the Amazon S3 bucket
(s3://lf-tagbased-demo-to theAccount-ID)lf-data-engineeruser.In the navigation pane, under Permissions, choose Data locations.
Choose Grant.
Select My account.
For IAM users and roles, choose the
lf-data-engineerrole.For Storage locations, enter the Amazon S3 bucket created by the Amazon CloudFormation template
(s3://lf-tagbased-demo-.Account-ID)Choose Grant.
-
Next, grant
lf-data-engineergrantable permissions on resources associated with the LF-Tag expressionConfidential=True.In the navigation pane, under Permissions, choose Data lake permissions.
Choose Grant.
Select IAM users and roles.
Choose the role
lf-data-engineer.In the LF-Tags or catalog resources section, select Resources matched by LF-Tags.
Choose Add LF-Tag key-value pair.
Add the key
Confidentialwith the valuesTrue.In the Database permissions section, select Describe for Database permissions and Grantable permissions.
In the Table permissions section, select Describe, Select, and Alter for both Table permissions and Grantable permissions.
Choose Grant.
-
Next, grant
lf-data-engineergrantable permissions on resources associated with the LF-Tag expressionConfidential=False.In the navigation pane, under Permissions, choose Data lake permissions.
Choose Grant.
Select IAM users and roles.
Choose the role
lf-data-engineer.Select Resources matched by LF-tags.
Choose Add LF-tag.
Add the key
Confidentialwith the valueFalse.In the Database permissions section, select Describe for Database permissions and Grantable permissions.
In the Table and column permissions section, do not select anything.
Choose Grant.
-
Next, we grant
lf-data-engineergrantable permissions on resources associated with the LF-Tag key-value pairsConfidential=FalseandSensitive=True.In the navigation pane, under Permissions, choose Data permissions.
Choose Grant.
Select IAM users and roles.
Choose the role
lf-data-engineer.Under LF-Tags or catalog resources section, select Resources matched by LF-Tags.
Choose Add LF-Tag.
Add the key
Confidentialwith the valueFalse.Choose Add LF-Tag key-value pair.
Add the key
Sensitivewith the valueTrue.In the Database permissions section, select Describe for Database permissions and Grantable permissions.
In the Table permissions section, select Describe, Select, and Alter for both Table permissions and Grantable permissions.
Choose Grant.
Step 3: Create Lake Formation databases
In this step, you create two databases and attach LF-Tags to the databases and specific columns for testing purposes.
Create your databases and table for database-level access
-
First, create the database
tag_database, the tablesource_data, and attach appropriate LF-Tags.On the Lake Formation console (https://console.amazonaws.cn/lakeformation/
), under Data Catalog, choose Databases. Choose Create database.
For Name, enter
tag_database.For Location, enter the Amazon S3 location created by the Amazon CloudFormation template
(s3://lf-tagbased-demo-.Account-ID/tag_database/)Deselect Use only IAM access control for new tables in this database.
Choose Create database.
-
Next, create a new table within
tag_database.On the Databases page, select the database
tag_database.ChooseView Tables and click Create table.
For Name, enter
source_data.For Database, choose the database
tag_database.For Table format, choose Standard Amazon Glue table.
For Data is located in, select Specified path in my account.
For Include path, enter the path to
tag_databasecreated by the Amazon CloudFormation template(s3://lf-tagbased-demo.Account-ID/tag_database/)For Data format, select CSV.
Under Upload schema, enter the following JSON array of column structure to create a schema:
[ { "Name": "vendorid", "Type": "string" }, { "Name": "lpep_pickup_datetime", "Type": "string" }, { "Name": "lpep_dropoff_datetime", "Type": "string" }, { "Name": "store_and_fwd_flag", "Type": "string" }, { "Name": "ratecodeid", "Type": "string" }, { "Name": "pulocationid", "Type": "string" }, { "Name": "dolocationid", "Type": "string" }, { "Name": "passenger_count", "Type": "string" }, { "Name": "trip_distance", "Type": "string" }, { "Name": "fare_amount", "Type": "string" }, { "Name": "extra", "Type": "string" }, { "Name": "mta_tax", "Type": "string" }, { "Name": "tip_amount", "Type": "string" }, { "Name": "tolls_amount", "Type": "string" }, { "Name": "ehail_fee", "Type": "string" }, { "Name": "improvement_surcharge", "Type": "string" }, { "Name": "total_amount", "Type": "string" }, { "Name": "payment_type", "Type": "string" } ]Choose Upload. After uploading the schema, the table schema should look like the following screenshot:
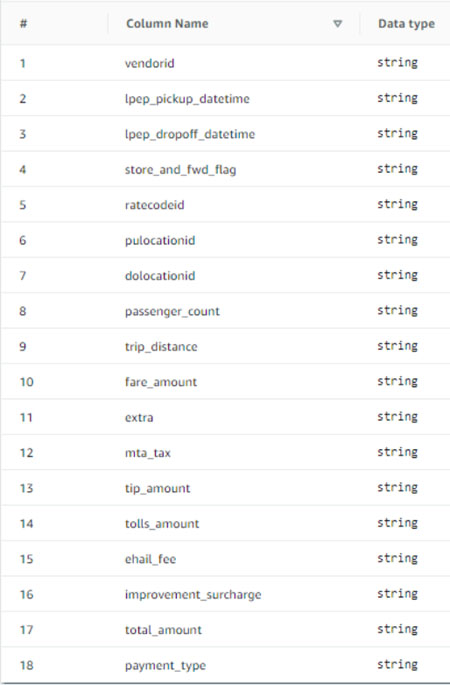
Choose Submit.
-
Next, attach LF-Tags at the database level.
On the Databases page, find and select
tag_database.On the Actions menu, choose Edit LF-Tags.
Choose Assign new LF-tag.
For Assigned keys¸ choose the
ConfidentialLF-Tag you created earlier.For Values, choose
True.Choose Save.
This completes the LF-Tag assignment to the tag_database database.
Create your database and table for column-level access
Repeat the following steps to create the database col_tag_database and table source_data_col_lvl, and attach LF-Tags at the column level.
On the Databases page, choose Create database.
-
For Name, enter
col_tag_database. -
For Location, enter the Amazon S3 location created by the Amazon CloudFormation template
(s3://lf-tagbased-demo-.Account-ID/col_tag_database/) -
Deselect Use only IAM access control for new tables in this database.
-
Choose Create database.
On the Databases page, select your new database
(col_tag_database).Choose View tables and click Create table.
For Name, enter
source_data_col_lvl.For Database, choose your new database
(col_tag_database).For Table format, choose Standard Amazon Glue table.
For Data is located in, select Specified path in my account.
Enter the Amazon S3 path for
col_tag_database(s3://lf-tagbased-demo-.Account-ID/col_tag_database/)For Data format, select
CSV.Under
Upload schema, enter the following schema JSON:[ { "Name": "vendorid", "Type": "string" }, { "Name": "lpep_pickup_datetime", "Type": "string" }, { "Name": "lpep_dropoff_datetime", "Type": "string" }, { "Name": "store_and_fwd_flag", "Type": "string" }, { "Name": "ratecodeid", "Type": "string" }, { "Name": "pulocationid", "Type": "string" }, { "Name": "dolocationid", "Type": "string" }, { "Name": "passenger_count", "Type": "string" }, { "Name": "trip_distance", "Type": "string" }, { "Name": "fare_amount", "Type": "string" }, { "Name": "extra", "Type": "string" }, { "Name": "mta_tax", "Type": "string" }, { "Name": "tip_amount", "Type": "string" }, { "Name": "tolls_amount", "Type": "string" }, { "Name": "ehail_fee", "Type": "string" }, { "Name": "improvement_surcharge", "Type": "string" }, { "Name": "total_amount", "Type": "string" }, { "Name": "payment_type", "Type": "string" } ]Choose
Upload. After uploading the schema, the table schema should look like the following screenshot.
Choose Submit to complete the creation of the table.
-
Now, associate the
Sensitive=TrueLF-Tag to the columnsvendoridandfare_amount.On the Tables page, select the table you created
(source_data_col_lvl).On the Actions menu, choose Schema.
Select the column
vendoridand choose Edit LF-Tags.For Assigned keys, choose Sensitive.
For Values, choose True.
Choose Save.
-
Next, associate the
Confidential=FalseLF-Tag tocol_tag_database. This is required forlf-data-analystto be able to describe the databasecol_tag_databasewhen logged in from Amazon Athena.On the Databases page, find and select
col_tag_database.On the Actions menu, choose Edit LF-Tags.
Choose Assign new LF-Tag.
For Assigned keys, choose the
ConfidentialLF-Tag you created earlier.For Values, choose
False.Choose Save.
Step 4: Grant table permissions
Grant permissions to data analysts for consumption of the databases tag_database
and the table col_tag_database using LF-tags Confidential and Sensitive.
-
Follow these steps to grant permissions to the
lf-data-analystuser on the objects associated with the LF-TagConfidential=True(Database:tag_database) to haveDescribethe database andSelectpermission on tables.Sign in to the Lake Formation console at https://console.amazonaws.cn/lakeformation/
as lf-data-engineer.Under Permissions, select Data lake permissions.
Choose Grant.
Under Principals, select IAM users and roles.
For IAM users and roles, choose
lf-data-analyst.Under LF-Tags or catalog resources, select Resources matched by LF-Tags.
Choose Add LF-tag.
For Key, choose
Confidential.For Values, choose
True.For Database permissions, select
Describe.For Table permissions, choose Select and Describe.
Choose Grant.
-
Next, repeat the steps to grant permissions to data analysts for LF-Tag expression for
Confidential=False. This LF-tag is used for describing thecol_tag_databaseand the tablesource_data_col_lvlwhen logged in aslf-data-analystfrom Amazon Athena.Sign in to the Lake Formation console at https://console.amazonaws.cn/lakeformation/
as lf-data-engineer.On the Databases page, select the database
col_tag_database.Choose Action and Grant.
Under Principals, select IAM users and roles.
For IAM users and roles, choose
lf-data-analyst.Select Resources matched by LF-Tags.
Choose Add LF-Tag.
For Key, choose
Confidential.For Values¸ choose
False.For Database permissions, select
Describe.For Table permissions, do not select anything.
Choose Grant.
-
Next, repeat the steps to grant permissions to data analysts for LF-Tag expression for
Confidential=FalseandSensitive=True. This LF-tag is used for describing thecol_tag_databaseand the tablesource_data_col_lvl(column-level) when logged in aslf-data-analystfrom Amazon Athena.Sign into the Lake Formation console at https://console.amazonaws.cn/lakeformation/
as lf-data-engineer.On the Databases page, select the database
col_tag_database.Choose Action and Grant.
Under Principals, select IAM users and roles.
For IAM users and roles, choose
lf-data-analyst.Select Resources matched by LF-Tags.
Choose Add LF-tag.
For Key, choose
Confidential.For Values¸ choose
False.Choose Add LF-tag.
For Key, choose
Sensitive.For Values¸ choose
True.For Database permissions, select
Describe.For Table permissions, select
SelectandDescribe.Choose Grant.
Step 5: Run a query in Amazon Athena to verify the permissions
For this step, use Amazon Athena to run SELECT queries against the two tables (source_data and source_data_col_lvl).
Use the Amazon S3 path as the query result location (s3://lf-tagbased-demo-.Account-ID/athena-results/)
-
Sign into the Athena console at https://console.amazonaws.cn/athena/
as lf-data-analyst. In the Athena query editor, choose
tag_databasein the left panel.Choose the additional menu options icon (three vertical dots) next to
source_dataand choose Preview table.Choose Run query.
The query should take a few minutes to run. The query displays all the columns in the output because the LF-tag is associated at the database level and the
source_datatable automatically inherited theLF-tagfrom the databasetag_database.Run another query using
col_tag_databaseandsource_data_col_lvl.The second query returns the two columns that were tagged as
Non-ConfidentialandSensitive.You can also check to see the Lake Formation tag-based access policy behavior on columns to which you do not have policy grants. When an untagged column is selected from the table
source_data_col_lvl, Athena returns an error. For example, you can run the following query to choose untagged columnsgeolocationid:SELECT geolocationid FROM "col_tag_database"."source_data_col_lvl" limit 10;
Step 6: Clean up Amazon resources
To prevent unwanted charges to your Amazon Web Services account, you can delete the Amazon resources that you used for this tutorial.
-
Sign into Lake Formation console as
lf-data-engineerand delete the databasestag_databaseandcol_tag_database. -
Next, sign in as
lf-data-stewardand clean up all the LF-tag Permissions, Data Permissions and Data Location Permissions that were granted above that were grantedlf-data-engineerandlf-data-analyst.. -
Sign into the Amazon S3 console as the account owner using the IAM credentials you used to deploy the Amazon CloudFormation stack.
-
Delete the following buckets:
lf-tagbased-demo-accesslogs-
acct-idlf-tagbased-demo-
acct-id
-
Sign into Amazon CloudFormation console at https://console.amazonaws.cn/cloudformation
, and delete the stack you created. Wait for the stack status to change to DELETE_COMPLETE.