Amazon ParallelCluster Auto Scaling
Note
This section only applies to Amazon ParallelCluster versions up to and including version 2.11.4. Starting with version 2.11.5, Amazon ParallelCluster doesn't support the use of SGE or Torque schedulers. You can continue using them in versions up to and including 2.11.4, but they aren't eligible for future updates or troubleshooting support from the Amazon service and Amazon Support teams.
Starting with Amazon ParallelCluster version 2.9.0, Auto Scaling isn't supported for use with Slurm Workload Manager (Slurm). To learn about Slurm and multiple queue scaling, see the Multiple queue mode tutorial.
The auto scaling strategy that's described in this topic applies to HPC clusters that are deployed with either Son of Grid Engine (SGE) or Torque Resource Manager (Torque). When deployed with one of these schedulers, Amazon ParallelCluster implements the scaling capabilities by managing the Auto Scaling group of the compute nodes, and then changing the scheduler configuration as needed. For HPC clusters that are based on Amazon Batch, Amazon ParallelCluster relies on the elastic scaling capabilities provided by the Amazon managed job scheduler. For more information, see What is Amazon EC2 Auto Scaling in the Amazon EC2 Auto Scaling User Guide.
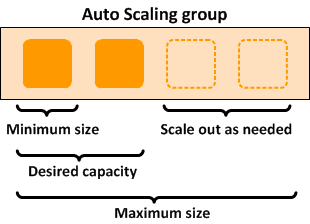
Clusters deployed with Amazon ParallelCluster are elastic in several ways. Setting the initial_queue_size specifies the minimum size value of the ComputeFleet Auto Scaling group, and also the desired capacity value. Setting the max_queue_size specifies the maximum size value of the ComputeFleet Auto Scaling group.
Scaling up
Every minute, a process called jobwatcher
With an SGE scheduler, each job requires a number of slots to run (one slot corresponds to one processing
unit, for example, a vCPU). To evaluate the number of instances that are required to serve the currently pending
jobs, the jobwatcher divides the total number of requested slots by the capacity of a single compute
node. The capacity of a compute node that corresponds to the number of available vCPUs depends on the Amazon EC2 instance
type that's specified in the cluster configuration.
With Slurm (before Amazon ParallelCluster version 2.9.0) and Torque schedulers, each job might require both a
number of nodes and a number of slots for every node, depending on circumstance. For each request, the
jobwatcher determines the number of compute nodes that are needed to fulfill the new computational
requirements. For example, let's assume a cluster with c5.2xlarge (8 vCPU) as the compute instance type,
and three queued pending jobs with the following requirements:
-
job1: 2 nodes / 4 slots each
-
job2: 3 nodes / 2 slots each
-
job3: 1 node / 4 slots each
In this example, the jobwatcher requires three new compute instances in the Auto Scaling group to serve the
three jobs.
Current limitation: auto scale up logic doesn't consider partially loaded busy nodes. For example, a node that's running a job is considered busy even if there are empty slots.
Scaling down
On each compute node, a process called nodewatcher
-
An instance has no jobs for a period of time longer than the scaledown_idletime (the default setting is 10 minutes)
-
There are no pending jobs in the cluster
To terminate an instance, nodewatcher calls the TerminateInstanceInAutoScalingGroup API
operation, which removes an instance if the size of the Auto Scaling group is at least the minimum Auto Scaling group size. This
process scales down a cluster without affecting running jobs. It also enables an elastic cluster with a fixed base
number of instances.
Static cluster
The value of auto scaling is the same for HPC as with any other workloads. The only difference is that Amazon ParallelCluster has code that makes it interact more intelligently. For example, if a static cluster is required, you set the initial_queue_size and max_queue_size parameters to the exact size of cluster that's required,. and then you set the maintain_initial_size parameter to true. This causes the ComputeFleet Auto Scaling group to have the same value for minimum, maximum, and desired capacity.