Supported SSML tags
Amazon Polly supports the following SSML tags:
| Action | SSML tag | Availability with neural voices | Availability with long-form voices | Availability with generative voices |
|---|---|---|---|---|
|
<break> |
Full availability |
Full availability |
Full availability |
|
| <emphasis> |
Not available |
Not available |
Not available |
|
| <lang> |
Full availability |
Full availability |
Full availability |
|
| <mark> |
Full availability |
Full availability |
Full availability |
|
|
<p> |
Full availability |
Full availability |
Full availability |
|
|
<phoneme> |
Full availability |
Full availability |
Not available |
|
|
<prosody> |
Partial availability |
Partial availability |
Not available |
|
|
<prosody amazon:max-duration> |
Not available |
Not available |
Not available |
|
|
<s> |
Full availability |
Full availability |
Full availability |
|
|
<say-as> |
Partial availability |
Partial availability |
Partial availability |
|
|
<speak> |
Full availability |
Full availability |
Full availability |
|
|
<sub> |
Full availability |
Full availability |
Full availability |
|
|
<w> |
Full availability |
Full availability |
Full availability |
|
|
<amazon:auto-breaths> |
Not available |
Not available |
Not available |
|
| <amazon:domain name="news"> |
Select neural voices only |
Not available |
Not available |
|
|
<amazon:effect name="drc"> |
Full availability |
Full availability |
Not available |
|
|
<amazon:effect phonation="soft"> |
Not available |
Not available |
Not available |
|
|
<amazon:effect vocal-tract-length> |
Not available |
Not available |
Not available |
|
|
<amazon:effect name="whispered"> |
Not available |
Not available |
Not available |
Note
If you use unsupported SSML tags in standard, neural, or long-form format, you will get an error.
Identifying SSML-enhanced text
<speak>
This tag is supported by generative, long-form, neural, and standard TTS formats.
The <speak> tag is the root element of all
Amazon Polly SSML text. All SSML-enhanced text must be enclosed within
a pair of <speak> tags.
<speak>Mary had a little lamb.</speak>Adding a pause
<break>
This tag is supported by generative, long-form, neural, and standard TTS formats.
To add a pause to your text, use the <break> tag. You can
set a pause based on strength (equivalent to the pause after a
comma, a sentence, or a paragraph), or you can set it to a
specific length of time in seconds or milliseconds. If you don't
specify an attribute to determine the pause length, Amazon Polly uses
the default, which is <break
strength="medium"/>, which adds a pause the length
of a pause after a comma.
strength attribute values:
-
none: No pause. Usenoneto remove a normally occurring pause, such as after a period. -
x-weak: Has the same strength asnone, no pause. -
weak: Sets a pause of the same duration as the pause after a comma. -
medium: Has the same strength asweak. -
strong: Sets a pause of the same duration as the pause after a sentence. -
x-strong: Sets a pause of the same duration as the pause after a paragraph.
time attribute values:
-
[number]s10s. -
[number]ms10000ms.
For example:
<speak>
Mary had a little lamb <break time="3s"/>Whose fleece was white as snow.
</speak>If you don't use an attribute with the break tag,
the result varies depending on text:
-
If there is no other punctuation next to the
breaktag, it creates a<break strength="medium"/>(comma-length pause). -
If the tag is next to a comma, it upgrades the tag to a
<break strength="strong"/>(sentence-length pause). -
If the tag is next to a period, it upgrades the tag to
<break strength="x-strong"/>(paragraph-length pause).
Emphasizing words
<emphasis>
This tag is supported only by the standard TTS format.
To emphasize words, use the <emphasis> tag. Emphasizing
words changes the speaking rate and volume. More emphasis makes
Amazon Polly speak the text louder and slower. Less emphasis makes it
speak quieter and faster. To specify the degree of emphasis, use
the level attribute.
level attribute values:
-
Strong: Increases the volume and slows the speaking rate so that the speech is louder and slower. -
Moderate: Increases the volume and slows the speaking rate, but less thanstrong.Moderateis the default. -
Reduced: Decreases the volume and speeds up the speaking rate. Speech is softer and faster.
Note
The normal speaking rate and volume for a voice falls
between the moderate and reduced
levels.
For example:
<speak> I already told you I <emphasis level="strong">really like</emphasis> that person. </speak>
Specifying another language for specific words
<lang>
This tag is supported by generative, long-form, neural, and standard TTS formats.
Specify another language for a specific word, phrase, or
sentence with the <lang> tag. Foreign language words and
phrases are generally spoken better when they are enclosed
within a pair of <lang> tags. To specify the
language, use the xml:lang attribute. For a
complete list of available languages, see Languages in Amazon Polly.
Unless you apply the <lang> tag, all of
the words in the input text are spoken in the language of the
voice specified in the voice-id. If you apply the
<lang> tag, the words are spoken in that
language.
For example, if the voice-id is Joanna (who
speaks US English), Amazon Polly speaks the following in the Joanna
voice without a French accent:
<speak>
Je ne parle pas français.
</speak>If you use the Joanna voice with the <lang>
tag, Amazon Polly speaks the sentence in the Joanna voice in
American-accented French:
<speak>
<lang xml:lang="fr-FR">Je ne parle pas français.</lang>.
</speak>Because Joanna is not a native French voice, pronunciation is based on her native language, US English. For example, although perfect French pronunciation features an uvual trill /R/ in the word français, Joanna's US English voice pronounces this phoneme as the corresponding sound /r/.
If you use the voice-id of Giorgio, who speaks
Italian, with the following text, Amazon Polly speaks the sentence in
Giorgio's voice with an Italian pronunciation:
<speak>
Mi piace Bruce Springsteen.
</speak>If you use the same voice with the following
<lang> tag, Amazon Polly pronounces Bruce
Springsteen in Italian-accented English:
<speak>
Mi piace <lang xml:lang="en-US">Bruce Springsteen.</lang>
</speak>This tag can also be used as a substitute for the optional DefaultLangCode option when synthesizing speech. However, doing so requires that you format your text using SSML.
Placing a custom tag in your text
<mark>
This tag is supported by generative, long-form, neural, and standard TTS formats.
To put a custom tag within the text, use the <mark> tag. Amazon Polly takes no action on the tag, but returns the location of the tag in the SSML metadata. This tag can be anything you want to call out, as long as it maintains the following format:
<mark name="tag_name"/>For example, suppose that the tag name is "animal" and the input text is:
<speak>
Mary had a little <mark name="animal"/>lamb.
</speak>Amazon Polly might return the following SSML metadata:
{"time":767,"type":"ssml","start":25,"end":46,"value":"animal"}Adding a pause between paragraphs
<p>
This tag is supported by generative, long-form, neural, and standard TTS formats.
To add a pause between paragraphs in your text, use the <p> tag. Using this tag provides a longer pause than native speakers usually place at commas or the end of a sentence. Use the <p> tag to enclose the paragraph:
<speak>
<p>This is the first paragraph. There should be a pause after this text is spoken.</p>
<p>This is the second paragraph.</p>
</speak>This is equivalent to specifying a pause using <break strength="x-strong"/>.
Using phonetic pronunciation
<phoneme>
This tag is supported by long-form, neural, and standard TTS formats.
To make Amazon Polly use phonetic pronunciation for specific text, use the <phoneme> tag.
Two attributes are required with the <phoneme>
tag. They indicate the phonetic alphabet Amazon Polly uses and
the phonetic symbols of the corrected pronunciation:
-
alphabet-
ipa— Indicates that the International Phonetic Alphabet (IPA) will be used. -
x-sampa— Indicates that the Extended Speech Assessment Methods Phonetic Alphabet (X-SAMPA) will be used.
-
-
ph-
Specifies the phonetic symbols for pronunciation. For more information, see Phoneme and Viseme Tables for Supported Languages
-
With the <phoneme> tag, Amazon Polly uses the
pronunciation specified by the ph attribute instead
of the standard pronunciation associated by default with the
language used by the selected voice.
For instance, the word "pecan" can be pronounced two ways. In
the following example, “pecan” is assigned a different
pronunciation in each line. Amazon Polly pronounces pecan as specified
in the ph attributes, instead of using the default
pronunciation.
International Phonetic Alphabet (IPA)
<speak> You say, <phoneme alphabet="ipa" ph="pɪˈkɑːn">pecan</phoneme>. I say, <phoneme alphabet="ipa" ph="ˈpi.kæn">pecan</phoneme>. </speak>
Extended Speech Assessment Methods Phonetic Alphabet (X-SAMPA)
<speak> You say, <phoneme alphabet='x-sampa' ph='pI"kA:n'>pecan</phoneme>. I say, <phoneme alphabet='x-sampa' ph='"pi.k{n'>pecan</phoneme>. </speak>
Mandarin Chinese uses Pinyin for phonetic pronunciation..
Pinyin
<speak> 你说 <phoneme alphabet="x-amazon-pinyin" ph="bo2">薄</phoneme>。 我说 <phoneme alphabet="x-amazon-pinyin" ph="bao2">薄</phoneme>。 </speak>
Japanese uses Yomigana and Pronunciation Kana.
Yomigana
<speak> 名前は<phoneme alphabet="x-amazon-yomigana" ph="ひろかず">浩一</phoneme>です。 名前は<phoneme alphabet="x-amazon-yomigana" ph="ヒロカズ">浩一</phoneme>です。 名前は<phoneme alphabet="x-amazon-yomigana" ph="Hirokazu">浩一</phoneme>です。 </speak>
Pronunciation Kana
<speak> 名前は<phoneme alphabet="x-amazon-pron-kana" ph="ヒロ'カズ">浩一</phoneme>です。 </speak>
Controlling volume, speaking rate, and pitch
<prosody>
Prosody tag attributes are fully supported by the standard TTS
voices. Neural and long-form voices support the volume and
rate attributes, but don't support the pitch
attribute.
To control the volume, rate, or pitch of your selected voice,
use the prosody tag.
Volume, speech rate, and pitch are dependent on the specific voice selected. In addition to differences between voices for different languages, there are differences between individual voices speaking the same language. Because of this, while attributes are similar across all languages, there are clear variations from language to language and no absolute value is available.
The prosody tag has three attributes, each of
which has several available values to set the attribute. Each
attribute uses the same syntax:
<prosody attribute="value"></prosody>-
volume-
default: Resets volume to the default level for the current voice. -
silent,x-soft,soft,medium,loud,x-loud: Sets the volume to a predefined value for the current voice. -
+ndB,-ndB: Changes volume relative to the current level. A value of+0dBmeans no change,+6dBmeans approximately twice the current volume, and-6dBmeans approximately half the current volume.
For example, you could set the volume for a passage as follows:
<speak> Sometimes it can be useful to <prosody volume="loud">increase the volume for a specific speech.</prosody> </speak>Or you could set it this way:
<speak> And sometimes a lower volume <prosody volume="-6dB">is a more effective way of interacting with your audience.</prosody> </speak> -
-
rate-
x-slow,slow,medium,fast,x-fast. Sets the pitch to a predefined value for the selected voice. -
n%: A non-negative percentage change in the speaking rate. For example, a value of 100% means no change in speaking rate, a value of 200% means a speaking rate twice the default rate, and a value of 50% means a speaking rate of half the default rate. This value has a range of 20-200%.
For example, you could set the speech rate for a passage as follows:
<speak> For dramatic purposes, you might wish to <prosody rate="slow">slow up the speaking rate of your text.</prosody> </speak>Or you could set it this way:
<speak> Although in some cases, it might help your audience to <prosody rate="85%">slow the speaking rate slightly to aid in comprehension.</prosody> </speak> -
-
pitch-
default: Resets pitch to the default level for the current voice. -
x-low,low,medium,high,x-high: Sets the pitch to a predefined value for the current voice. -
+n%or-n%: Adjusts pitch by a relative percentage. For example, a value of+0%means no baseline pitch change,+5%gives a little higher baseline pitch, and-5%results in a little lower baseline pitch.
For example, you could set the pitch for a passage as follows:
<speak> Do you like sythesized speech <prosody pitch="high">with a pitch that is higher than normal?</prosody> </speak>Or you could set it this way:
<speak> Or do you prefer your speech <prosody pitch="-10%">with a somewhat lower pitch?</prosody> </speak> -
The <prosody> tag must contain at least one attribute, but can include more within the same tag.
<speak> Each morning when I wake up, <prosody volume="loud" rate="x-slow">I speak quite slowly and deliberately until I have my coffee.</prosody> </speak>
It can also be combined with nested tags, as follows:
<speak> <prosody rate="85%">Sometimes combining attributes <prosody pitch="-10%">can change the impression your audience has of a voice</prosody> as well.</prosody> </speak>
Setting a maximum duration for synthesized speech
<prosody amazon:max-duration>
This tag is currently supported only by the standard TTS format.
To control how long you want a speech to take when it is
synthesized, use the <prosody> tag with the
amazon:max-duration attribute.
The duration of synthesized speech varies slightly, depending on the voice you select. This can make it difficult to match synthesized speech with visuals or other activities that require precise timing. This issue is magnified for translation applications because the time it takes to say particular phrases can vary widely with different languages.
The <prosody amazon:max-duration> tag matches
synthesized speech to the amount of time you want it to take
(the duration).
This tag uses the following syntax:
<prosody amazon:max-duration="time duration">With the <prosody amazon:max-duration> tag,
you can specify duration in either seconds or
milliseconds:
-
ns -
nms
For example, the following spoken text has a maximum duration of 2 seconds:
<speak>
<prosody amazon:max-duration="2s">
Human speech is a powerful way to communicate.
</prosody>
</speak>Text placed within the tag, it doesn't exceed the specified duration. If the chosen voice or language would normally take longer than that duration, Amazon Polly speeds up the speech so that it fits into the specified duration.
If the specified duration is longer than it takes to read the text at a normal rate, Amazon Polly reads the speech normally. It doesn't slow down the speech or add silence, so the resulting audio is shorter than requested.
Note
Amazon Polly increases the speed no more than 5 times the normal rate. If text is spoken faster than this, it usually doesn't make sense. If a speech cannot fit within your specified duration even when speeded up to the maximum, the audio will be speeded up but will last longer than the specified duration.
You can include a single sentence or multiple sentences within
a <prosody amazon:max-duration> tag, and you can
use multiple <prosody amazon:max-duration> tags
within your text.
For example:
<speak> <prosody amazon:max-duration="2400ms"> Human speech is a powerful way to communicate. </prosody> <break strength="strong"/> <prosody amazon:max-duration="5100ms"> Even a simple ‘Hello’ can convey a lot of information depending on the pitch, intonation, and tempo. </prosody> <break strength="strong"/> <prosody amazon:max-duration="8900ms"> We naturally understand this information, which is why speech is ideal for creating applications where a screen isn’t practical or possible, or simply isn’t convenient. </prosody> </speak>
Using the <prosody amazon:max-duration> tag
can increase latency when Amazon Polly is returns synthesized speech.
The degree of latency depends on the passage and its length. We
recommend using text comprised of relatively short text
passages.
Limitations
There are limitations both in how you use <prosody
amazon:max-duration> tag and in how it works with
other SSML tags:
-
The text inside a
<prosody amazon:max-duration>tag can't be longer than 1500 characters. -
You can't nest
<prosody amazon:max-duration>tags. If you put one<prosody amazon:max-duration>tag inside another, Amazon Polly ignores the inner tag.For example, in the following, the
<prosody amazon:max-duration="5s">tag is ignored:<speak> <prosody amazon:max-duration="16s"> Human speech is a powerful way to communicate. <prosody amazon:max-duration="5s"> Even a simple ‘Hello’ can convey a lot of information depending on the pitch, intonation, and tempo. </prosody> We naturally understand this information, which is why speech is ideal for creating applications where a screen isn’t practical or possible, or simply isn’t convenient. </prosody> </speak> -
You can't use the
<prosody>tags with therateattribute within a<prosody amazon:max-duration>tag. This is because both affect the speed at which text is spoken.In the following example, Amazon Polly ignores the
<prosody rate="2">tag:<speak> <prosody amazon:max-duration="7500ms"> Human speech is a powerful way to communicate. <prosody rate="2"> Even a simple ‘Hello’ can convey a lot of information depending on the pitch, intonation, and tempo. </prosody> </prosody> </speak>
Pauses and max-duration
When using max-duration tag, you can still insert
pauses within your text. However, Amazon Polly includes the length of
the pause when calculating the maximum duration for speech.
Additionally, Amazon Polly preserves the short pauses that occur where
commas and periods are placed within a passage and includes in
the maximum duration.
For example, in the following block, the 600 millisecond break and the breaks caused by the commas and periods occur within the 8-second speech:
<speak> <prosody amazon:max-duration="8s"> Human speech is a powerful way to communicate. <break time="600ms"/> Even a simple ‘Hello’ can convey a lot of information depending on the pitch, intonation, and tempo. </prosody> </speak>
Adding a pause between sentences
<s>
This tag is supported by generative, long-form, neural, and standard TTS formats.
To add a pause between lines or sentences in your text, use
the <s> tag. Using this tag has the same effect
as:
-
Ending a sentence with a period (.)
-
Specifying a pause with
<break strength="strong"/>
Unlike the <break> tag, the <s> tag
encloses the sentence. This is useful for synthesizing speech
that is organized in lines, rather than sentence, such as
poetry.
In the following example, the <s> tag
creates a short pause after both the first and second sentences.
The final sentence has no <s> tag, but it is
also followed by a short pause because it ends with a
period.
<speak> <s>Mary had a little lamb</s> <s>Whose fleece was white as snow</s> And everywhere that Mary went, the lamb was sure to go. </speak>
Controlling how special types of words are spoken
<say-as>
Except for the characters option, the <say-as>
tag is supported by generative, long-form, neural, and standard TTS formats. Note that
if Amazon Polly is using a neural voice and encounters the <say-as>
tag with the characters option at runtime, the affected sentence
will be synthesized using the related standard voice. However, the affected
sentence will still be billed as if it uses a neural voice.
Use the <say-as> tag with the
interpret-as attribute to tell Amazon Polly how to say
certain characters, words, and numbers. This enables you to
provide additional context to eliminate any ambiguity on how
Amazon Polly should render the text.
The <say-as> tag uses one attribute,
interpret-as, which uses a number of possible available
values. Each uses the same syntax:
<say-as interpret-as="value">[text to be interpreted]</say-as>The following values are available with
interpret-as:
-
charactersorspell-out: Spells out each letter of the text, as in a-b-c.Note
This option is not currently supported for neural voices. If you're using a neural voice and this SSML code is encountered by Amazon Polly at run-time, the affected sentence will be synthesized using the related standard voice. Please note, however, that this sentence will still be billed as if it uses a neural voice.
-
cardinalornumber: Interprets the numerical text as a cardinal number, as in 1,234. -
ordinal: Interprets the numerical text as an ordinal number, as in 1,234th. -
digits: Spells out each digit individually, as in 1-2-3-4. -
fraction: Interprets the numerical text as a fraction. This works for both common fractions such as 3/20, and mixed fractions, such as 2 ½. See below for more information. -
unit: Interprets a numerical text as a measurement. The value should be either a number or a fraction followed by a unit with no space in between as in1/2inch, or by just a unit, as in1meter. -
date: Interprets the text as a date. The format of the date must be specified with the format attribute. See below for more information. -
time: Interprets the numerical text as duration, in minutes and seconds, as in1'21". -
address: Interprets the text as part of a street address. -
expletive: "Beeps out" the content included within the tag. -
telephone: Interprets the numerical text as a 7-digit or 10-digit telephone number, as in2025551212. You can also use this value for handle telephone extensions, as in2025551212x345. See below for more information.Note
Currently the
telephoneoption is not available for all languages. However, it is available for voices speaking English language variants (en-AU, en-GB, en-IN, en-US, and en-GB-WLS), Spanish language variants (es-ES, es-MX, and es-US), French language variants (fr-FR and fr-CA), and Portuguese variants (pt-BR and pt-PT), as well as German (de-DE), Italian (it-IT), Japanese (ja-JP), and Russian (ru-RU). It should also be noted that in some cases, languages such as Arabic (arb) automatically handle the number set as a telephone number and so don't actually implement thetelephoneSSML tag.
Fractions
Amazon Polly interprets values within the say-as tag
that have the interpret-as="fraction" attribute as
common fractions. The following is the syntax for
fractions:
-
Fraction
Syntax:
cardinal number/cardinal number, such as 2/9.For example:
<say-as interpret-as="fraction">2/9</say-as>is pronounced "two ninths." -
Non-negative Mixed Number
Syntax:
cardinal number+cardinal number/cardinal number, such as 3+1/2.For example,
<say-as interpret-as="fraction">3+1/2</say-as>is pronounced "three and a half."Note
There must be a
+between the "3" and the "1/2". Amazon Polly doesn't support a mixed number without the+, such as "3 1/2".
Dates
When interpret-as is set to date,
you also need to indicate the format of the date.
This uses the following syntax:
<say-as interpret-as="date" format="format">[date]</say-as>
For example:
<speak> I was born on <say-as interpret-as="date" format="mdy">12-31-1900</say-as>. </speak>
The following formats can be used with the date
attribute.
-
mdy: Month-day-year. -
dmy: Day-month-year. -
ymd: Year-month-day. -
md: Month-day. -
dm: Day-month. -
ym: Year-month. -
my: Month-year. -
d: Day. -
m: Month. -
y: Year. -
yyyymmdd: Year-month-day. If you use this format, you can make Amazon Polly skip parts of the date using question marks.For example, Amazon Polly renders the following as "September 22nd":
<say-as interpret-as="date">????0922</say-as>Formatis not needed.
Telephone
Amazon Polly attempts to interpret the text you provide correctly
based on the text’s formatting even without the
<say-as> tag. For example, if your text
includes "202-555-1212," Amazon Polly interprets it as a 10-digit
telephone number and says each digit individually, with a brief
pause for each dash. In this case, you don't need to use
<say-as interpret-as="telephone">.
However, if you provide the text “2025551212” and want Amazon Polly to
say it as a phone number, you would specify <say-as
interpret-as="telephone">.
The logic for interpreting each element is language-specific. For example, US and UK English differ in how phone numbers are pronounced (in UK English, sequences of the same digit are grouped together, as in "double five" or "triple four"). To see the difference, test the following example with a US voice and with a UK voice:
<speak> Richard's number is <say-as interpret-as="telephone">2122241555</say-as> </speak>
Pronouncing acronyms and abbreviations
<sub>
This tag is supported by generative, long-form, neural, and standard TTS formats.
Use the <sub> tag with the alias
attribute to substitute a different word (or pronunciation) for
selected text such as an acronym or abbreviation.
This uses the syntax:
<sub alias="new word">abbreviation</sub>In the following example, the name "Mercury" is substituted for the element's chemical symbol to make the audio content clearer.
<speak> My favorite chemical element is <sub alias="Mercury">Hg</sub>, because it looks so shiny. </speak>
Improving pronunciation by specifying parts of speech
<w>
This tag is supported by generative, long-form, neural, and standard TTS formats.
You can use the <w> tag to customize the pronunciation of
words by specifying the word’s part of speech or alternate
meaning. This is done using the role
attribute.
This tag uses the following syntax:
<w role="attribute">text</w>The following values can be used for the role
attribute:
To specify the part of speech:
-
amazon:VB: interprets the word as a verb (present simple). -
amazon:VBD: interprets the word as past tense verb. -
amazon:DT: interprets the word as a determiner. -
amazon:IN: interprets the word as a preposition. -
amazon:JJ: interprets the word as an adjective. -
amazon:NN: interprets the word as a noun.
For example, depending on its part of speech, the US English pronunciation of the word "read" varies based on the tag:
<speak> The word <say-as interpret-as="characters">read</say-as> may be interpreted as either the present simple form <w role="amazon:VB">read</w>, or the past participle form <w role="amazon:VBD">read</w>. </speak>
To specify a specific meaning:
-
amazon:DEFAULT: uses the default sense of the word. -
amazon:SENSE_1: uses the non-default sense of the word when present. For example, the noun "bass" is pronounced differently depending on its meaning. The default meaning is the lowest part of the musical range. The alternate meaning is a species of freshwater fish, also called "bass" but pronounced differently. Using<w role="amazon:SENSE_1">bass</w>renders the non-default pronunciation (freshwater fish) for the audio text.
This difference in pronunciation and meaning can be heard if you synthesize the following:
<speak> Depending on your meaning, the word <say-as interpret-as="characters">bass</say-as> may be interpreted as either a musical element: bass, or as its alternative meaning, a freshwater fish <w role="amazon:SENSE_1">bass</w>. </speak>
Note
Some languages may have a different selection of supported parts of speech.
Adding the sound of breathing
<amazon:breath> and <amazon:auto-breaths>
This tag is supported only by the standard TTS format.
Natural-sounding speech includes both correctly spoken words
and breathing sounds. By adding breathing sounds to synthesized
speech, you can make it sound more natural. The
<amazon:breath> and
<amazon:auto-breaths> tags provide
breaths. You have the following options:
-
Manual mode: you set the location, length, and volume of a breath sound within the text
-
Automated mode: Amazon Polly automatically inserts breathing sounds into the speech output
-
Mixed mode: both you and Amazon Polly add breathing sounds
Manual Mode
In manual mode, you place the
<amazon:breath/> tag in the input
text where you want to locate a breath. You can customize
the length and volume of breaths with the
duration and volume
attributes, respectively:
-
duration: Controls the length of the breath. Valid values are:default,x-short,short,medium,long,x-long. The default value ismedium. -
volume: Controls how loud breathing sounds. Valid values are:default,x-soft,soft,medium,loud,x-loud. The default value ismedium.
Note
The exact length and volume of each attribute value is dependent on the specific Amazon Polly voice used.
To set a breath sound using the defaults, use
<amazon:breath/> without attributes.
For example, to use attributes to set the duration and volume for a breath to medium, you would set the attributes as follows:
<speak> Sometimes you want to insert only <amazon:breath duration="medium" volume="x-loud"/>a single breath. </speak>
To use the defaults, you would just use the tag:
<speak> Sometimes you need <amazon:breath/>to insert one or more average breaths <amazon:breath/> so that the text sounds correct. </speak>
You can add individual breathing sounds within a passage, as follows:
<speak> <amazon:breath duration="long" volume="x-loud"/> <prosody rate="120%"> <prosody volume="loud"> Wow! <amazon:breath duration="long" volume="loud"/> </prosody> That was quite fast. <amazon:breath duration="medium" volume="x-loud"/> I almost beat my personal best time on this track. </prosody> </speak>
Automated Mode
In automated mode, you use the
<amazon:auto-breaths> tag to tell
Amazon Polly to automatically create breathing noises at
appropriate intervals. You can set the frequency of the
intervals, their volume, and their duration. Place the
</amazon:auto-breaths> tag at the
beginning of the text that you want to apply automated
breathing to and then close the tag at the end.
Note
Unlike the manual mode tag,
<amazon:breath/>, the
<amazon:auto-breaths> tag requires a
closing tag (</amazon:auto-breaths>).
You can use the following optional attributes with the
<amazon:auto-breaths> tag:
-
volume: Controls how loud the breathing sounds. Valid values are:default,x-soft,soft,medium,loud,x-loud. The default value ismedium. -
frequency: Controls how often breathing sounds occur in the text. Valid values are:default,x-low,low,medium,high,x-high. The default value ismedium. -
duration: Controls the length of the breath. Valid values are:default,x-short,short,medium,long,x-long. The default value ismedium.
By default, the frequency of breathing sounds depends on the input text. However, breathing sounds often occur after commas and periods.
The following examples show how to use the
<amazon:auto-breaths> tag. To decide
which options to use for your content, copy the applicable
examples to the Amazon Polly console and listen to the differences.
-
Using automated mode without optional parameters.
<speak> <amazon:auto-breaths>Amazon Polly is a service that turns text into lifelike speech, allowing you to create applications that talk and build entirely new categories of speech- enabled products. Amazon Polly is a text-to-speech service that uses advanced deep learning technologies to synthesize speech that sounds like a human voice. With dozens of lifelike voices across a variety of languages, you can select the ideal voice and build speech- enabled applications that work in many different countries.</amazon:auto-breaths> </speak> -
Using automated mode with volume control. The unspecified parameters (
durationandfrequency) are set to the default values (medium).<speak> <amazon:auto-breaths volume="x-soft">Amazon Polly is a service that turns text into lifelike speech, allowing you to create applications that talk and build entirely new categories of speech-enabled products. Amazon Polly is a text-to-speech service, that uses advanced deep learning technologies to synthesize speech that sounds like a human voice. With dozens of lifelike voices across a variety of languages, you can select the ideal voice and build speech- enabled applications that work in many different countries.</amazon:auto-breaths> </speak> -
Using automated mode with frequency control. The unspecified parameters (
durationandvolume) are set to the default values (medium).<speak> <amazon:auto-breaths frequency="x-low">Amazon Polly is a service that turns text into lifelike speech, allowing you to create applications that talk and build entirely new categories of speech-enabled products. Amazon Polly is a text-to-speech service, that uses advanced deep learning technologies to synthesize speech that sounds like a human voice. With dozens of lifelike voices across a variety of languages, you can select the ideal voice and build speech- enabled applications that work in many different countries.</amazon:auto-breaths> </speak> -
Using automated mode with multiple parameters. For the unspecified
Durationparameter, Amazon Polly uses the default value (medium).<speak> <amazon:auto-breaths volume="x-loud" frequency="x-low">Amazon Polly is a service that turns text into lifelike speech, allowing you to create applications that talk and build entirely new categories of speech-enabled products. Amazon Polly is a text-to-speech service, that uses advanced deep learning technologies to synthesize speech that sounds like a human voice. With dozens of lifelike voices across a variety of languages, you can select the ideal voice and build speech-enabled applications that work in many different countries.</amazon:auto-breaths> </speak>
Newscaster speaking style
<amazon:domain name="news">
The newscaster style is available only for the Matthew or
Joanna voices, which are available only in American English
(en-US), Lupe, in US Spanish (es-US) and Amy, in British English
(en-GB). It is only supported when using Neural
format.
To use the newscaster style, you use SSML tags and the following syntax::
<amazon:domain name="news">text</amazon:domain>
For example, you might use the newscaster style with the Amy voice as follows:
<speak> <amazon:domain name="news"> From the Tuesday, April 16th, 1912 edition of The Guardian newspaper: The maiden voyage of the White Star liner Titanic, the largest ship ever launched, has ended in disaster. The Titanic started her trip from Southampton for New York on Wednesday. Late on Sunday night she struck an iceberg off the Grand Banks of Newfoundland. By wireless telegraphy she sent out signals of distress, and several liners were near enough to catch and respond to the call. </amazon:domain> </speak>
Adding dynamic range compression
<amazon:effect name="drc">
This tag is supported by long-form, neural, and standard TTS formats.
Depending on the text, language, and voice used in an audio
file, the sounds range from soft to loud. Environmental sounds,
such as the sound of a moving vehicle, can often mask the softer
sounds, which makes the audio track difficult to hear clearly.
To enhance the volume of certain sounds in your audio file, use
the dynamic range compression (drc) tag.
The drc tag sets a midrange "loudness" threshold
for your audio, and increases the volume (the gain) of the
sounds around that threshold. It applies the greatest gain
increase closest to the threshold, and the gain increase is
lessened farther away from the threshold.

This makes the middle-range sounds easier to hear in a noisy environment, which makes the entire audio file clearer.
The drc tag is a Boolean parameter (it's either
present or it isn't). It uses the syntax:
<amazon:effect name="drc"> and is closed
with </amazon:effect>.
You can use the drc tag with any voice or
language supported by Amazon Polly. You can apply it to an entire
section of the recording, or for only a few words. For
example:
<speak> Some audio is difficult to hear in a moving vehicle, but <amazon:effect name="drc"> this audio is less difficult to hear in a moving vehicle.</amazon:effect> </speak>
Note
When you use "drc" in the amazon:effect
syntax, it is case-sensitive.
Using drc with the prosody
volume Tag
As the following graphic shows, the prosody
volume tag evenly increases the volume of an
entire audio file from the original level (dotted line) to
an adjusted level (solid line). To further increase the
volume of certain parts of the file, use the
drc tag with the prosody
volume tag. Combining tags doesn't affect the
settings of the prosody volume tag.
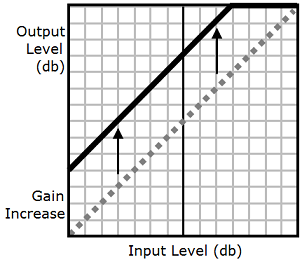
When you use the drc and prosody
volume tags together, Amazon Polly applies the
drc tag first, increasing the middle-range
sounds (those near the threshold). It then applies the
prosody volume tag and further increases the
volume of the entire audio track evenly.
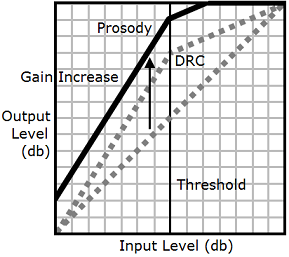
To use the tags together, nest one inside the other. For example:
<speak> <prosody volume="loud">This text needs to be understandable and loud. <amazon:effect name="drc"> This text also needs to be more understandable in a moving car.</amazon:effect></prosody> </speak>
In this text, the prosody volume tag increases
the volume of the entire passage to "loud." The drc
tag enhances the volume of the middle-range values in the second
sentence.
Note
When using the drc and prosody
volume tags together, use standard XML practices
for nesting tags.
Speaking softly
<amazon:effect phonation="soft">
This tag is currently supported only by the standard TTS format.
To specify that input text should be spoken in a softer-than-normal voice, use the <amazon:effect phonation="soft"> tag.
This uses the syntax:
<amazon:effect phonation="soft">text</amazon:effect>For example, you might use this tag with the Matthew voice as follows:
<speak> This is Matthew speaking in my normal voice. <amazon:effect phonation="soft">This is Matthew speaking in my softer voice.</amazon:effect> </speak>
Controlling timbre
<amazon:effect vocal-tract-length>
This tag is currently supported only by the standard TTS format.
Timbre is the tonal quality of a voice that helps you tell the difference between voices, even when they have the same pitch and loudness. One of the most important physiological features that contributes to speech timbre is the length of the vocal tract. The vocal tract is a cavity of air that spans from the top of the vocal folds up to the edge of the lips.
To control the timbre of output speech in Amazon Polly, use the
vocal-tract-length tag. This tag has the effect
of changing the length of the speaker’s vocal tract, which
sounds like a change in the speaker’s size. When you increase
the vocal-tract-length, the speaker sounds
physically bigger. When you decrease it, the speaker sounds
smaller. You can use this tag with any of the voices in the
Amazon Polly Text-to-Speech portfolio.
To change timbre, use the following values:
-
+n%or-n%: Adjusts the vocal tract length by a relative percentage change in the current voice. For example, +4% or -2%. Valid values range from +100% to -50%. Values outside this range are clipped. For example, +111% sounds like +100% and -60% sounds like -50%. -
n%: Changes the vocal tract length to an absolute percentage of the tract length of the current voice. For example, 110% or 75%. An absolute value of 110% is equivalent to a relative value of +10%. An absolute value of 100% is the same as the default value for the current voice.
The following example shows how to change the vocal tract length to change timbre:
<speak> This is my original voice, without any modifications. <amazon:effect vocal-tract-length="+15%"> Now, imagine that I am much bigger. </amazon:effect> <amazon:effect vocal-tract-length="-15%"> Or, perhaps you prefer my voice when I'm very small. </amazon:effect> You can also control the timbre of my voice by making minor adjustments. <amazon:effect vocal-tract-length="+10%"> For example, by making me sound just a little bigger. </amazon:effect><amazon:effect vocal-tract-length="-10%"> Or, making me sound only somewhat smaller. </amazon:effect> </speak>
Combining Multiple Tags
You can combine the vocal-tract-length tag with
any other SSML tag that is supported by Amazon Polly. Because timbre
(vocal tract length) and pitch are closely connected, you might
get the best results by using both the
vocal-tract-length and the <prosody
pitch> tags. To produce the most realistic voice, we
recommend that you use different percentages of change for the
two tags. Experiment with various combinations to get the
results you want.
The following example shows how to combine tags.
<speak> The pitch and timbre of a person's voice are connected in human speech. <amazon:effect vocal-tract-length="-15%"> If you are going to reduce the vocal tract length, </amazon:effect><amazon:effect vocal-tract-length="-15%"> <prosody pitch="+20%"> you might consider increasing the pitch, too. </prosody></amazon:effect> <amazon:effect vocal-tract-length="+15%"> If you choose to lengthen the vocal tract, </amazon:effect> <amazon:effect vocal-tract-length="+15%"> <prosody pitch="-10%"> you might also want to lower the pitch. </prosody></amazon:effect> </speak>
Whispering
<amazon:effect name="whispered">
This tag is currently supported only by the standard TTS format.
This tag indicates that the input text should be spoken in a whispered voice rather than as normal speech. This can be used with any of the voices in the Amazon Polly Text-to-Speech portfolio.
This uses the following syntax:
<amazon:effect name="whispered">text</amazon:effect>For example:
<speak> <amazon:effect name="whispered">If you make any noise, </amazon:effect> she said, <amazon:effect name="whispered">they will hear us.</amazon:effect> </speak>
In this case, the synthesized speech spoken by the character is whispered, but the phrase "she said" is spoken in the normal synthesized speech of the selected Amazon Polly voice.
You can enhance the "whispered" effect by slowing down the prosody rate by up to 10%, depending on the effect you want.
For example:
<speak> When any voice is made to whisper, <amazon:effect name="whispered"> <prosody rate="-10%">the sound is slower and quieter than normal speech </prosody></amazon:effect> </speak>
When generating speech marks for a whispered voice, the audio stream must also include the whispered voice to ensure that the speech marks match the audio stream.