Amazon Redshift will no longer support the creation of new Python UDFs starting Patch 198.
Existing Python UDFs will continue to function until June 30, 2026. For more information, see the
blog post
Query planning and execution workflow
The following illustration provides a high-level view of the query planning and execution workflow.
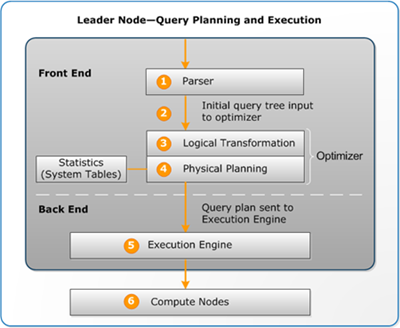
The query planning and execution workflow follow these steps:
-
The leader node receives the query and parses the SQL.
-
The parser produces an initial query tree that is a logical representation of the original query. Amazon Redshift then inputs this query tree into the query optimizer.
-
The optimizer evaluates and if necessary rewrites the query to maximize its efficiency. This process sometimes results in creating multiple related queries to replace a single one.
-
The optimizer generates a query plan (or several, if the previous step resulted in multiple queries) for the execution with the best performance. The query plan specifies execution options such as join types, join order, aggregation options, and data distribution requirements.
You can use the EXPLAIN command to view the query plan. The query plan is a fundamental tool for analyzing and tuning complex queries. For more information, see Creating and interpreting a query plan.
-
The execution engine translates the query plan into steps, segments, and streams:
- Step
-
Each step is an individual operation needed during query execution. Steps can be combined to allow compute nodes to perform a query, join, or other database operation.
- Segment
-
A combination of several steps that can be done by a single process, also the smallest compilation unit executable by a compute node slice. A slice is the unit of parallel processing in Amazon Redshift. The segments in a stream run in parallel.
- Stream
-
A collection of segments to be parceled out over the available compute node slices.
The execution engine generates compiled code based on steps, segments, and streams. Compiled code runs faster than interpreted code and uses less compute capacity. This compiled code is then broadcast to the compute nodes.
Note
When benchmarking your queries, you should always compare the times for the second execution of a query, because the first execution time includes the overhead of compiling the code. For more information, see Factors affecting query performance.
-
The compute node slices run the query segments in parallel. As part of this process, Amazon Redshift takes advantage of optimized network communication, memory, and disk management to pass intermediate results from one query plan step to the next. This also helps to speed query execution.
Steps 5 and 6 happen once for each stream. The engine creates the executable segments for one stream and sends them to the compute nodes. When the segments of that stream are complete, the engine generates the segments for the next stream. In this way, the engine can analyze what happened in the prior stream (for example, whether operations were disk-based) to influence the generation of segments in the next stream.
When the compute nodes are done, they return the query results to the leader node for final processing. The leader node merges the data into a single result set and addresses any needed sorting or aggregation. The leader node then returns the results to the client.
Note
The compute nodes might return some data to the leader node during query execution if necessary. For example, if you have a subquery with a LIMIT clause, the limit is applied on the leader node before data is redistributed across the cluster for further processing.