Amazon Redshift will no longer support the creation of new Python UDFs starting Patch 198.
Existing Python UDFs will continue to function until June 30, 2026. For more information, see the
blog post
Authentication with the Spark connector
The following diagram describes the authentication between Amazon S3, Amazon Redshift, the Spark driver, and Spark executors.
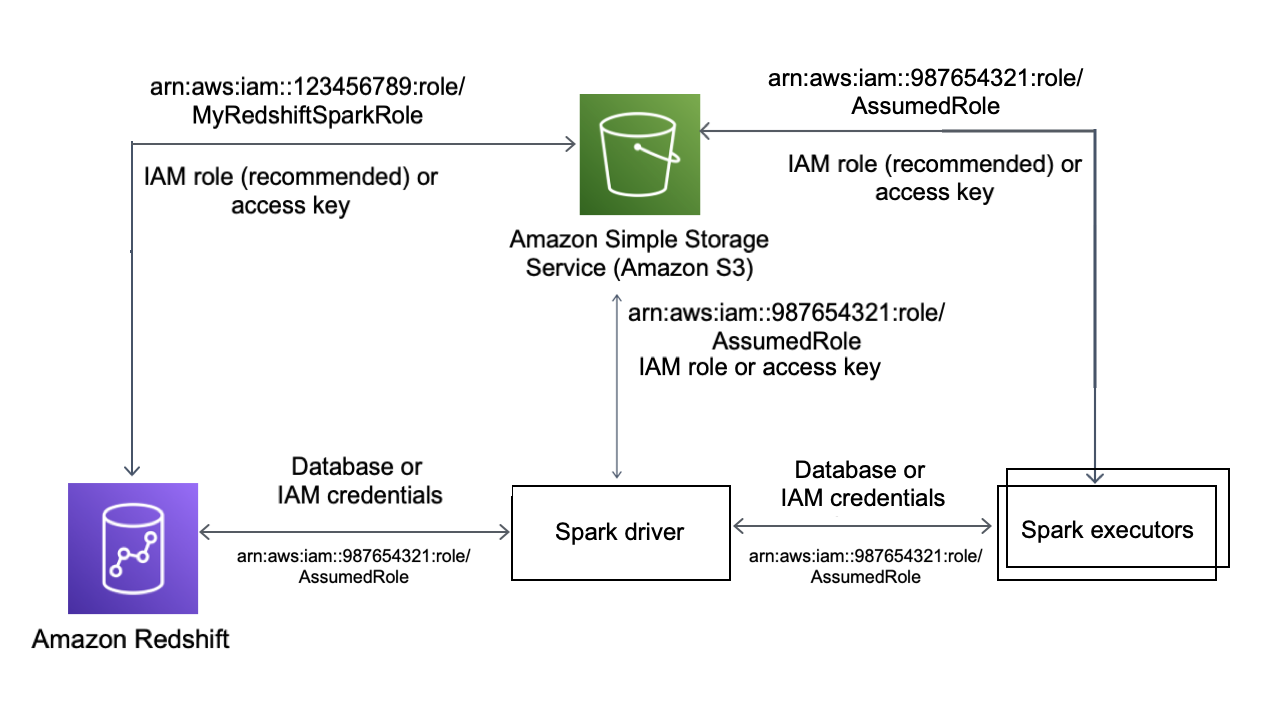
Authentication between Redshift and Spark
You can use the Amazon Redshift provided JDBC driver version 2.x driver to connect to Amazon Redshift with the Spark connector by specifying sign-in credentials. To use IAM, configure your JDBC url to use IAM authentication. To connect to a Redshift cluster from Amazon EMR or Amazon Glue, make sure that your IAM role has the necessary permissions to retrieve temporary IAM credentials. The following list describes all of the permissions that your IAM role needs to retrieve credentials and run Amazon S3 operations.
-
Redshift:GetClusterCredentials (for provisioned Redshift clusters)
-
Redshift:DescribeClusters (for provisioned Redshift clusters)
-
Redshift:GetWorkgroup (for Amazon Redshift Serverless workgroups)
-
Redshift:GetCredentials (for Amazon Redshift Serverless workgroups)
For more information about GetClusterCredentials, see IAM policies for GetClusterCredentials.
You also must make sure that Amazon Redshift can assume the IAM role during
COPY and UNLOAD operations.
If you’re using the latest JDBC driver, the driver will automatically manage the transition from an Amazon Redshift self-signed certificate to an ACM certificate. However, you must specify the SSL options to the JDBC url.
The following is an example of how to specify the JDBC driver URL and
aws_iam_role to connect to Amazon Redshift.
df.write \ .format("io.github.spark_redshift_community.spark.redshift ") \ .option("url", "jdbc:redshift:iam://<the-rest-of-the-connection-string>") \ .option("dbtable", "<your-table-name>") \ .option("tempdir", "s3a://<your-bucket>/<your-directory-path>") \ .option("aws_iam_role", "<your-aws-role-arn>") \ .mode("error") \ .save()
Authentication between Amazon S3 and Spark
If you’re using an IAM role to authenticate between Spark and Amazon S3, use one of the following methods:
-
The Amazon SDK for Java will automatically attempt to find Amazon credentials by using the default credential provider chain implemented by the DefaultAWSCredentialsProviderChain class. For more information, see Using the Default Credential Provider Chain.
-
You can specify Amazon keys via Hadoop configuration properties
. For example, if your tempdirconfiguration points to as3n://filesystem, set thefs.s3n.awsAccessKeyIdandfs.s3n.awsSecretAccessKeyproperties in a Hadoop XML configuration file or callsc.hadoopConfiguration.set()to change Spark's global Hadoop configuration.
For example, if you are using the s3n filesystem, add:
sc.hadoopConfiguration.set("fs.s3n.awsAccessKeyId", "YOUR_KEY_ID") sc.hadoopConfiguration.set("fs.s3n.awsSecretAccessKey", "YOUR_SECRET_ACCESS_KEY")
For the s3a filesystem, add:
sc.hadoopConfiguration.set("fs.s3a.access.key", "YOUR_KEY_ID") sc.hadoopConfiguration.set("fs.s3a.secret.key", "YOUR_SECRET_ACCESS_KEY")
If you’re using Python, use the following operations:
sc._jsc.hadoopConfiguration().set("fs.s3n.awsAccessKeyId", "YOUR_KEY_ID") sc._jsc.hadoopConfiguration().set("fs.s3n.awsSecretAccessKey", "YOUR_SECRET_ACCESS_KEY")
-
Encode authentication keys in the
tempdirURL. For example, the URIs3n://ACCESSKEY:SECRETKEY@bucket/path/to/temp/direncodes the key pair (ACCESSKEY,SECRETKEY).
Authentication between Redshift and Amazon S3
If you’re using the COPY and UNLOAD commands in your query, you also must grant Amazon S3 access to Amazon Redshift to run queries on your behalf. To do so, first authorize Amazon Redshift to access other Amazon services, then authorize the COPY and UNLOAD operations using IAM roles.
As a best practice, we recommend attaching permissions policies to an IAM role and then assigning it to users and groups as needed. For more information, see Identity and access management in Amazon Redshift.
Integration with Amazon Secrets Manager
You can retrieve your Redshift username and password credentials from a stored
secret in Amazon Secrets Manager. To automatically supply Redshift credentials, use the
secret.id parameter. For more information about how to create a
Redshift credentials secret, see Create an
Amazon Secrets Manager database secret.
| GroupID | ArtifactID | Supported Revision(s) | Description |
|---|---|---|---|
| com.amazonaws.secretsmanager | aws-secretsmanager-jdbc | 1.0.12 | The Amazon Secrets Manager SQL Connection Library for Java lets Java Developers to easily connect to SQL databases using secrets stored in Amazon Secrets Manager. |
Note
Acknowledgement: This documentation contains sample code and language developed
by the Apache Software Foundation