Associate Prediction Results with Input Records
When making predictions on a large dataset, you can exclude attributes that aren't needed for prediction. After the predictions have been made, you can associate some of the excluded attributes with those predictions or with other input data in your report. By using batch transform to perform these data processing steps, you can often eliminate additional preprocessing or postprocessing. You can use input files in JSON and CSV format only.
Topics
Workflow for Associating Inferences with Input Records
The following diagram shows the workflow for associating inferences with input records.
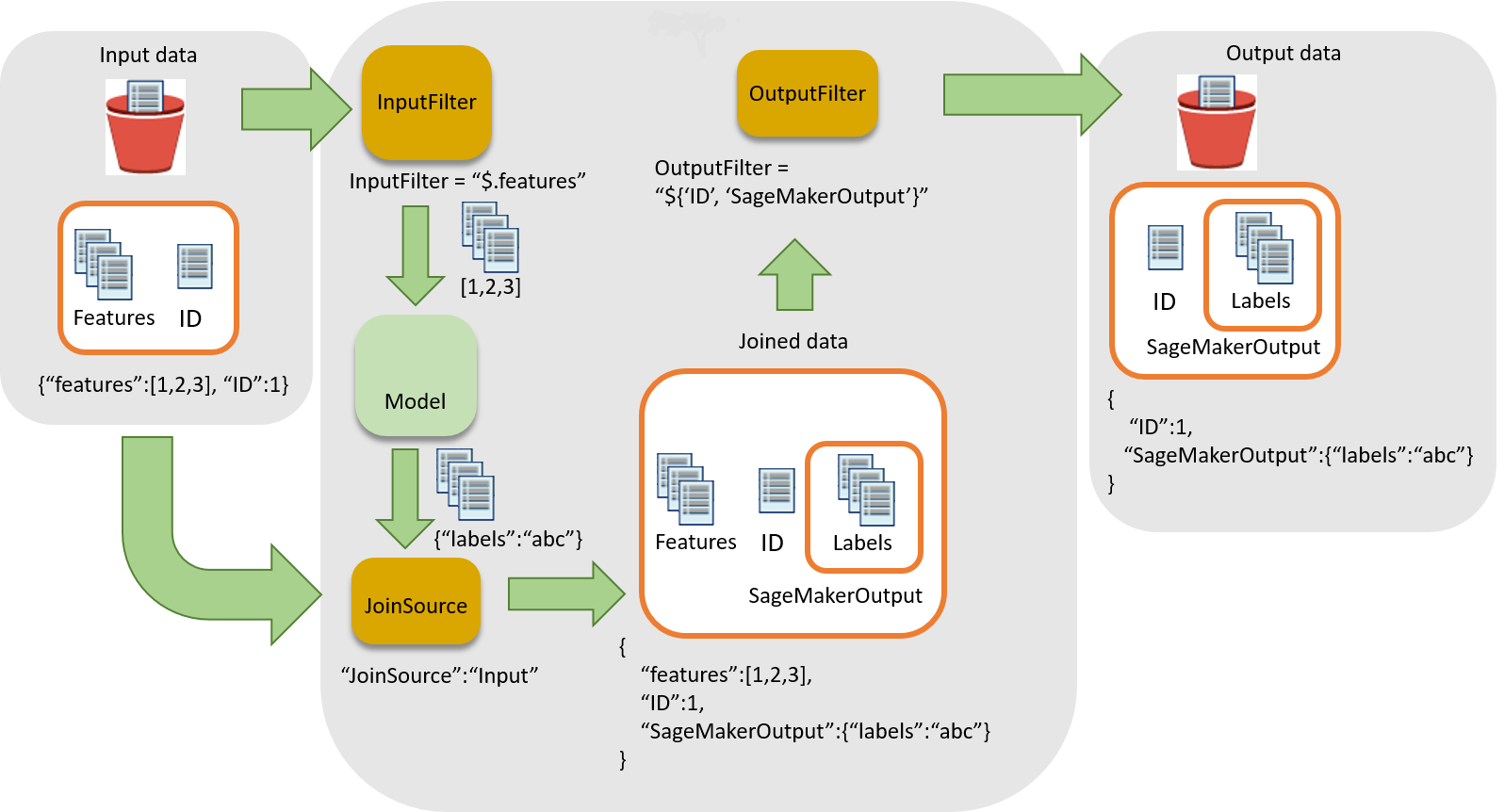
To associate inferences with input data, there are three main steps:
-
Filter the input data that is not needed for inference before passing the input data to the batch transform job. Use the
InputFilterparameter to determine which attributes to use as input for the model. -
Associate the input data with the inference results. Use the
JoinSourceparameter to combine the input data with the inference. -
Filter the joined data to retain the inputs that are needed to provide context for interpreting the predictions in the reports. Use
OutputFilterto store the specified portion of the joined dataset in the output file.
Use Data Processing in Batch Transform Jobs
When creating a batch transform job with CreateTransformJob to
process
data:
-
Specify the portion of the input to pass to the model with the
InputFilterparameter in theDataProcessingdata structure. -
Join the raw input data with the transformed data with the
JoinSourceparameter. -
Specify which portion of the joined input and transformed data from the batch transform job to include in the output file with the
OutputFilterparameter. -
Choose either JSON- or CSV-formatted files for input:
-
For JSON- or JSON Lines-formatted input files, SageMaker AI either adds the
SageMakerOutputattribute to the input file or creates a new JSON output file with theSageMakerInputandSageMakerOutputattributes. For more information, seeDataProcessing. -
For CSV-formatted input files, the joined input data is followed by the transformed data and the output is a CSV file.
-
If
you use an algorithm with the DataProcessing structure, it must support
your chosen format for both input and output
files. For example, with the TransformOutput field of the
CreateTransformJob API, you must set both the ContentType and Accept parameters to one of the following values:
text/csv, application/json, or
application/jsonlines. The syntax for specifying columns in a CSV
file and specifying attributes in a JSON file are different. Using the wrong syntax
causes an error. For more information, see Batch Transform Examples. For more information
about input and output file formats for built-in algorithms, see Built-in algorithms and pretrained models in Amazon SageMaker.
The record delimiters for the input and output must also be consistent with your
chosen file input. The SplitType parameter indicates how to split the records in
the input dataset. The AssembleWith parameter indicates how to reassemble the
records for the output. If you set input and output formats to
text/csv, you must also set the SplitType and
AssembleWith parameters to line. If you set the input
and output formats to application/jsonlines, you can set both
SplitType and AssembleWith to
line.
For CSV files, you cannot use embedded newline characters. For JSON files, the
attribute name SageMakerOutput is reserved for output. The JSON input
file can't have an attribute with this name. If it does, the data in the input file
might be overwritten.
Supported JSONPath Operators
To filter and join the input data and inference, use a JSONPath subexpression.
SageMaker AI supports only a subset of the defined JSONPath operators. The following table
lists the supported JSONPath operators. For CSV data, each row is taken as a JSON
array, so only index based JSONPaths can be applied, e.g. $[0],
$[1:]. CSV data should also follow RFC format
| JSONPath Operator | Description | Example |
|---|---|---|
$ |
The root element to a query. This operator is required at the beginning of all path expressions. |
$ |
. |
A dot-notated child element. |
|
* |
A wildcard. Use in place of an attribute name or numeric value. |
|
[' |
A bracket-notated element or multiple child elements. |
|
[ |
An index or array of indexes. Negative index values are also
supported. A |
|
[ |
An array slice operator.
The array slice() method extracts a section of an array and
returns a new array. If you omit
|
|
When using the bracket-notation to specify multiple child elements of a given
field, additional nesting of children within brackets is not supported. For example,
$.field1.['child1','child2'] is supported while
$.field1.['child1','child2.grandchild'] is not.
For more information about JSONPath operators, see JsonPath
Batch Transform Examples
The following examples show some common ways to join input data with prediction results.
Topics
Example: Output Only Inferences
By default, the DataProcessing parameter doesn't join inference results
with input. It outputs only the inference results.
If you want to explicitly specify to
not
join results with input, use the Amazon SageMaker Python SDK
sm_transformer = sagemaker.transformer.Transformer(…) sm_transformer.transform(…, input_filter="$", join_source= "None", output_filter="$")
To output inferences using the Amazon SDK for Python, add the following code to your CreateTransformJob request. The following code mimics the default behavior.
{ "DataProcessing": { "InputFilter": "$", "JoinSource": "None", "OutputFilter": "$" } }
Example: Output Inferences Joined with Input Data
If you're using the Amazon SageMaker Python SDKassemble_with and
accept parameters when initializing the transformer object.
When you use the transform call, specify Input for the
join_source parameter, and specify the split_type
and content_type parameters as well. The split_type
parameter must have the same value as assemble_with, and the
content_type parameter must have the same value as
accept. For more information about the parameters and their
accepted values, see the Transformer
sm_transformer = sagemaker.transformer.Transformer(…, assemble_with="Line", accept="text/csv") sm_transformer.transform(…, join_source="Input", split_type="Line", content_type="text/csv")
If you're using the Amazon SDK for Python (Boto 3), join all input data with
the inference by adding the following code to your CreateTransformJob request. The values for
Accept and ContentType must match, and the values
for AssembleWith and SplitType must also match.
{ "DataProcessing": { "JoinSource": "Input" }, "TransformOutput": { "Accept": "text/csv", "AssembleWith": "Line" }, "TransformInput": { "ContentType": "text/csv", "SplitType": "Line" } }
For JSON or JSON Lines input files, the results are in the
SageMakerOutput key in the input JSON file. For example, if the
input is a JSON file that contains the key-value pair {"key":1},
the data transform result might be {"label":1}.
SageMaker AI
stores
both
in the input file in the SageMakerInput
key.
{ "key":1, "SageMakerOutput":{"label":1} }
Note
The joined result for JSON must be a key-value pair object. If the input
isn't a key-value pair object, SageMaker AI creates a new JSON file. In the new JSON
file, the input data is stored in the SageMakerInput key and
the results are stored as the SageMakerOutput value.
For
a CSV file, for example, if the record is [1,2,3], and the label
result is [1], then the output file would contain
[1,2,3,1].
Example: Output Inferences Joined with Input Data and Exclude the ID Column from the Input (CSV)
If you are using the Amazon SageMaker Python SDKinput_filter in your transformer call. For
example, if your input data includes five columns and the first one is the ID
column, use the following transform request to select all columns except the ID
column as features. The transformer still outputs all of the input columns
joined with the inferences. For more information about the parameters and their
accepted values, see the Transformer
sm_transformer = sagemaker.transformer.Transformer(…, assemble_with="Line", accept="text/csv") sm_transformer.transform(…, split_type="Line", content_type="text/csv", input_filter="$[1:]", join_source="Input")
If you are using the Amazon SDK for Python (Boto 3), add the following code to
your
CreateTransformJob request.
{ "DataProcessing": { "InputFilter": "$[1:]", "JoinSource": "Input" }, "TransformOutput": { "Accept": "text/csv", "AssembleWith": "Line" }, "TransformInput": { "ContentType": "text/csv", "SplitType": "Line" } }
To specify columns in SageMaker AI, use the index of the array elements. The first column is index 0, the second column is index 1, and the sixth column is index 5.
To exclude the first column from the input, set InputFilter to "$[1:]". The colon
(:) tells SageMaker AI to include all of the elements between two
values, inclusive. For example, $[1:4] specifies the second through
fifth columns.
If you omit the number after the colon, for example, [5:], the
subset includes all columns from the 6th column through the last column. If you
omit the number before the colon, for example, [:5], the subset
includes all columns from the first column (index 0) through the sixth
column.
Example: Output Inferences Joined with an ID Column and Exclude the ID Column from the Input (CSV)
If you are using the Amazon SageMaker Python SDKoutput_filter in the transformer call. The
output_filter uses a JSONPath subexpression to specify which
columns to return as output after joining the input data with the inference
results. The following request shows how you can make predictions while
excluding an ID column and then join the ID column with the inferences. Note
that in the following example, the last column (-1) of the output
contains the inferences. If you are using JSON files, SageMaker AI stores the inference
results in the attribute SageMakerOutput. For more information
about the parameters and their accepted values, see the Transformer
sm_transformer = sagemaker.transformer.Transformer(…, assemble_with="Line", accept="text/csv") sm_transformer.transform(…, split_type="Line", content_type="text/csv", input_filter="$[1:]", join_source="Input", output_filter="$[0,-1]")
If you are using the Amazon SDK for Python (Boto 3), join only the ID column
with the inferences by adding the following code to your CreateTransformJob request.
{ "DataProcessing": { "InputFilter": "$[1:]", "JoinSource": "Input", "OutputFilter": "$[0,-1]" }, "TransformOutput": { "Accept": "text/csv", "AssembleWith": "Line" }, "TransformInput": { "ContentType": "text/csv", "SplitType": "Line" } }
Warning
If you are using a JSON-formatted input file, the file can't contain the
attribute name SageMakerOutput. This attribute name is reserved
for the inferences in the output file. If your JSON-formatted input file
contains an attribute with this name, values in the input file might be
overwritten with the inference.