How IP Insights Works
Amazon SageMaker AI IP Insights is an unsupervised algorithm that consumes observed data in the form of (entity, IPv4 address) pairs that associates entities with IP addresses. IP Insights determines how likely it is that an entity would use a particular IP address by learning latent vector representations for both entities and IP addresses. The distance between these two representations can then serve as the proxy for how likely this association is.
The IP Insights algorithm uses a neural network to learn the latent vector
representations for entities and IP addresses. Entities are first hashed to a large but
fixed hash space and then encoded by a simple embedding layer. Character strings such as
user names or account IDs can be fed directly into IP Insights as they appear in log
files. You don't need to preprocess the data for entity identifiers. You can provide
entities as an arbitrary string value during both training and inference. The hash size
should be configured with a value that is high enough to ensure that the number of
collisions, which occur when distinct entities are mapped to
the same latent vector, remain insignificant. For more information about how to select
appropriate hash sizes, see Feature Hashing for
Large Scale Multitask Learning
During training, IP Insights automatically generates negative samples by randomly pairing entities and IP addresses. These negative samples represent data that is less likely to occur in reality. The model is trained to discriminate between positive samples that are observed in the training data and these generated negative samples. More specifically, the model is trained to minimize the cross entropy, also known as the log loss, defined as follows:
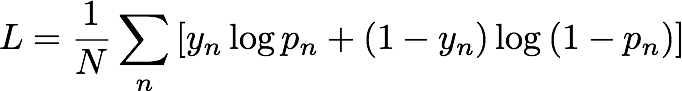
yn is the label that indicates whether the sample is from the real distribution governing observed data (yn=1) or from the distribution generating negative samples (yn=0). pn is the probability that the sample is from the real distribution, as predicted by the model.
Generating negative samples is an important process that is used to achieve an
accurate model of the observed data. If negative samples are extremely unlikely, for
example, if all of the IP addresses in negative samples are 10.0.0.0, then the model
trivially learns to distinguish negative samples and fails to accurately characterize
the actual observed dataset. To keep negative samples more realistic, IP Insights
generates negative samples both by randomly generating IP addresses and randomly picking
IP addresses from training data. You can configure the type of negative sampling and the
rates at which negative samples are generated with the
random_negative_sampling_rate and
shuffled_negative_sampling_rate hyperparameters.
Given an nth (entity, IP address pair), the IP Insights model outputs a score, Sn , that indicates how compatible the entity is with the IP address. This score corresponds to the log odds ratio for a given (entity, IP address) of the pair coming from a real distribution as compared to coming from a negative distribution. It is defined as follows:
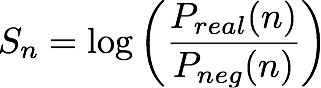
The score is essentially a measure of the similarity between the vector representations of the nth entity and IP address. It can be interpreted as how much more likely it would be to observe this event in reality than in a randomly generated dataset. During training, the algorithm uses this score to calculate an estimate of the probability of a sample coming from the real distribution, pn, to use in the cross entropy minimization, where: