Reliability
Reliability is one of the six pillars of SAP Lens - Amazon Well-Architected Framework. For more information, see Reliability.
Amazon cloud offers reliability with multiple Availability Zones within an Amazon Region. This enables your SAP applications on Amazon to be more resilient. Each Region is further isolated from other Regions, providing the greatest possible fault tolerance and stability. Within each Amazon Region, there are a minimum of three, isolated, physically separate Availability Zones. For more information, see Regions and Availability Zones
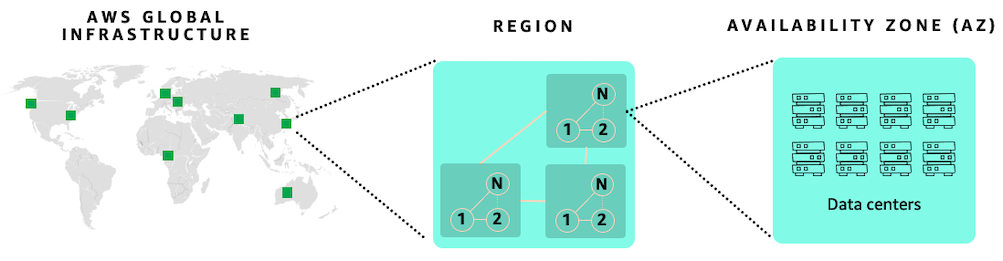
Availability Zones enable you to operate production applications and databases that are more highly available than would be possible from a single data center. Distributing your applications across multiple Availability Zones provides the ability to remain resilient in the face of most failure modes, including natural disasters or system failures.
Each Availability Zone can be multiple data centers. At full scale, it can contain hundreds of thousands of servers. They are fully isolated partitions of Amazon Global Infrastructure. An Availability Zone is physically separated from any other zones with its own separate power and networking resources. There is a distance of several kilometers, although all are within 100 km (60 miles) of each other. This distance provides isolation from the most common disasters that could affect data centers, such as floods, fire, severe storms, earthquakes, etc.
All Availability Zones within a Region are interconnected with high-bandwidth and low-latency networking, over fully redundant and dedicated metro fiber. This ensures high-throughput, low-latency networking between Availability Zones. The network performance is sufficient to accomplish synchronous replication.
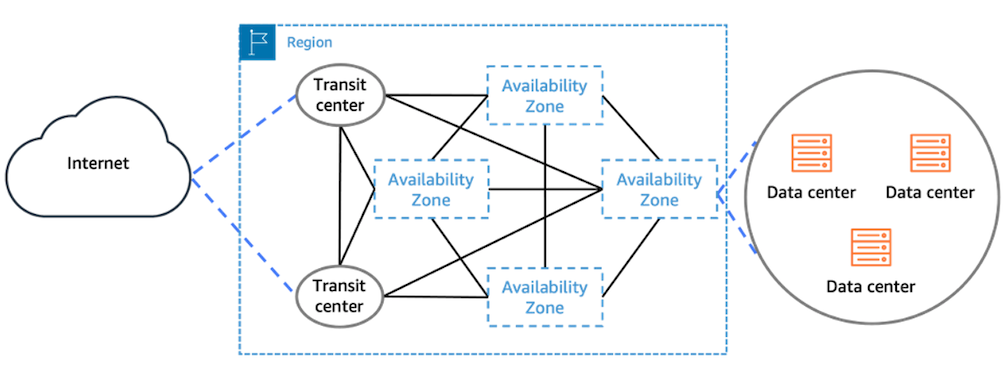
Availability Zones enable you to run your applications in a highly-available manner, with synchronous data replication and automated failover between Availability Zones. RISE with SAP can offer such high available designs for your workload in every Amazon Region.
Resiliency and Cost Considerations
SAP has options available for RISE to meet different resiliency requirements. The following key requirements are adjustable for RISE via option packages available from SAP.
-
Service Level Agreement (SLA) – describes the targeted availability of the solution.
-
Recovery Time Objective (RTO) – describes the targeted duration within which a recovery from a disaster event should be completed.
-
Recovery Point Objective (RPO) – describes the targeted level of data loss that may occur during recovery from a disaster event.
For more details, refer to the definitions provided by SAP as part of RISE agreement for specific definitions, clauses, impacts, and penalties in the event of a breach.
The impact of an outage on your organisation and loss of data can cause loss of productivity, loss of income, and can damage reputation. Weighing the trade-off between cost and resiliency can help assess the risk to your organisation.
Resiliency and Performance Considerations
When you opt for short distance disaster recovery option in RISE, the SAP application servers and database servers will be installed across multi Availability Zones. This architecture supports highly available design for your SAP workload.
While using the application servers in multiple Availability Zones in an active-active configuration, it increases the resiliency. In parallel, a higher latency cross Availability Zones from application server to database server is introduced. You can refer to SAP Note 3496343
-
Network latency between the SAP application server and database server should be less than 0.7 milliseconds as per SAP Note 1100926
-
Network latency for HANA system replication with synchronous data replication (which is required to achieve zero data loss) to be less than 1 millisecond
You can use the Amazon Network Manager – Infrastructure Performance tool to automatically measure Inter-AZ, Intra-AZ and Inter-Region network latency. Alternatively, you can use SAP’s NIPING
When SAP application servers and database servers distributed across multiple Availability Zones (AZs), it significantly enhances system reliability and availability, outweighing the impact of increased network latency.
Cross Availability Zones traffic may increase the time required to perform certain transactions or batch jobs that make frequent calls to the database. In case the impact is high, we recommend keeping this traffic within the same Availability Zone using SAP Logon Groups
To automate and optimise the running of such performance-critical batch jobs and transactions on application servers located in the same Availability Zone as the database server, Amazon provides example ABAP code
You may implement further optimization through C-State parameters
When it is not feasible to run application servers in active-active mode across multi Availability Zones, you can run in active-passive mode by utilizing ABAPSetServerInactive (SAP Note 3075829)
In rare cases, where you observe performance impacts due to latency within one Availability Zone, you may use Cluster Placement Groups to achieve lowest possible latency. You can refer to the Placement Strategies Guide from Amazon.
In summary, these are the architecture patterns in multi Availability Zones deployment:
| App Servers in AZ1 | App Servers in AZ2 | Failover Mechanism from AZ1 to AZ2 |
|---|---|---|
|
Active |
Active |
Automated script (i.e. pacemaker) |
|
Active |
Active |
Manual adjustment of Logon Groups, RFC and Batch Server Groups |
|
Active |
Active |
Automatic script to adjust Logon Groups, RFC and Batch Server Groups |
|
Active |
Passive |
Manual activation of the passive application servers |
|
Active |
Passive |
Automatic script to activate the passive application servers |
To achieve high reliability of SAP workloads, we recommend the following tasks:
-
Discuss with SAP on the Availability SLA requirement for RISE deployment. This will drive the components (i.e. database and application servers) that will be deployed across multiple Availability Zones to maximise reliability and availability of RISE.
-
If you have business scenarios involving batch jobs and/or transactions that makes frequent calls to the database servers, it may be adversely impacted by inter-AZ network latency, you can consider using SAP’s workload distribution mechanism (SAP Logon Groups, RFC Server Groups and Batch Server Groups) to ensure these jobs and transactions run on the application servers located in the same Availability Zone as the database server
-
You may implement further optimization of network latency by referring to Amazon re:Post article Inter-AZ Latency for SAP.
-
When active-active mode is not feasible, you can run in active–passive mode of application servers utilizing ABAPSetServerInactive (SAP Note 3075829).
-
You can consider putting other workloads, that are outside of RISE, within the same Availability Zone in order to achieve better network latency and lower data transfer cost.
Disaster recovery options
You can implement a disaster recovery solution by replicating data into a second Amazon Region. Your SAP workloads are protected in the event of rare occurrence of local or regional failures.
RISE with SAP S/4HANA Cloud, private edition offers the following two options.
-
Short distance disaster recovery or Metro disaster recovery – RISE with SAP uses multiple Availability Zones in an Amazon Region. Unique Amazon region with three or more Availability Zones provide the option of short distance disaster recovery in every Amazon regions.
-
Long distance disaster recovery or Regional disaster recovery – RISE with SAP uses a secondary Amazon Region as standby for failover systems. Owing to the physical distance between two Amazon Regions, data is replicated asynchronously between two Amazon Regions.
For more details, see SAP documentation SAP Service Description: Disaster Recovery and Customer Invoked Failover