Replicating data using Amazon Services
Amazon Glue
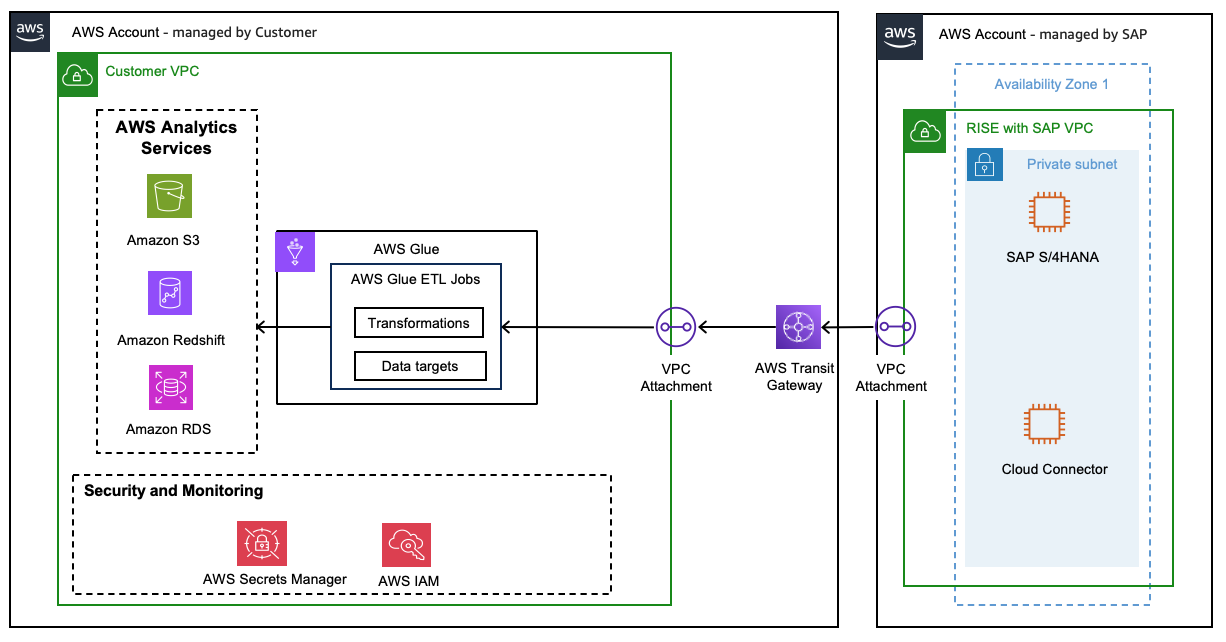
Amazon Glue
The Connecting to SAP OData using Glue user guide offers comprehensive instructions for setting up Glue ETL jobs, configuring SAP OData connections, and reading data from SAP, including handling incremental transfers.
Amazon Glue Zero-ETL is a set of fully managed integrations by Amazon that minimizes the need to build ETL data pipelines for common ingestion and replication use cases. It makes data available in Amazon SageMaker Lakehouse and Amazon Redshift from multiple operational, transactional, and application sources. Leveraging the SAP OData Connectors, you can create full data replication jobs from SAP, with fully managed replication (Inserts, updates and deletions) as well as schema evolution.
Amazon Glue and Glue Zero-ETL serve distinct roles in data integration, with each offering unique advantages for different use cases. While Amazon Glue excels in complex ETL operations, data discovery, preparation, and extraction, particularly for specialized scenarios like SAP ODP-based replication. Amazon Glue Zero-ETL is designed as a more streamlined, no-code solution for fully managed data replication scenarios.
Amazon Glue requires more hands-on management, including code deployment and maintenance, but offers greater flexibility and control over data transformation processes. Amazon Glue performance is enhanced by its serverless, scale-out Apache Spark environment, which allows you to allocate Data Processing Units (DPUs) for scalable compute. This allows parallel processing and event-driven execution.