Fanout Amazon SNS events to Amazon Event Fork Pipelines
| For event archiving and analytics, Amazon SNS now recommends using its native integration with Amazon Data Firehose. You can subscribe Firehose delivery streams to SNS topics, which allows you to send notifications to archiving and analytics endpoints such as Amazon Simple Storage Service (Amazon S3) buckets, Amazon Redshift tables, Amazon OpenSearch Service (OpenSearch Service), and more. Using Amazon SNS with Firehose delivery streams is a fully-managed and codeless solution that doesn't require you to use Amazon Lambda functions. For more information, see Fanout to Firehose delivery streams. |
You can use Amazon SNS to build event-driven applications which use subscriber services to perform work automatically in response to events triggered by publisher services. This architectural pattern can make services more reusable, interoperable, and scalable. However, it can be labor-intensive to fork the processing of events into pipelines that address common event handling requirements, such as event storage, backup, search, analytics, and replay.
To accelerate the development of your event-driven applications, you can subscribe
event-handling pipelines—powered by Amazon Event Fork Pipelines—to Amazon SNS topics. Amazon Event Fork Pipelines is a suite of open-source
nested applications
For an Amazon Event Fork Pipelines use case, see Deploying and testing the Amazon SNS event fork pipelines sample application.
Topics
How Amazon Event Fork Pipelines works
Amazon Event Fork Pipelines is a serverless design pattern. However, it is also a suite of nested serverless applications based on Amazon SAM (which you can deploy directly from the Amazon Serverless Application Repository (Amazon SAR) to your Amazon Web Services account in order to enrich your event-driven platforms). You can deploy these nested applications individually, as your architecture requires.
Topics
The following diagram shows an Amazon Event Fork Pipelines application supplemented by three nested applications. You can deploy any of the pipelines from the Amazon Event Fork Pipelines suite on the Amazon SAR independently, as your architecture requires.
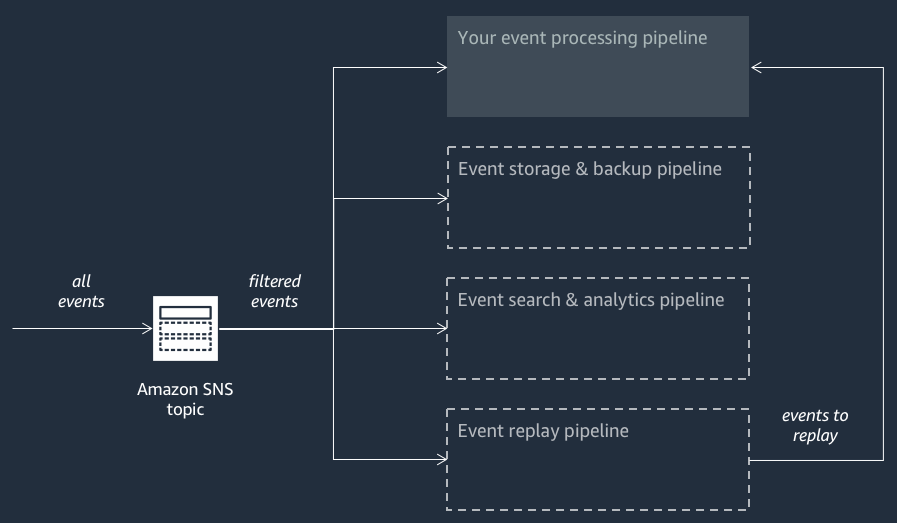
Each pipeline is subscribed to the same Amazon SNS topic, allowing itself to process events in parallel as these events are published to the topic. Each pipeline is independent and can set its own Subscription Filter Policy. This allows a pipeline to process only a subset of the events that it is interested in (rather than all events published to the topic).
Note
Because you place the three Amazon Event Fork Pipelines alongside your regular event processing pipelines (possibly already subscribed to your Amazon SNS topic), you don’t need to change any portion of your current message publisher to take advantage of Amazon Event Fork Pipelines in your existing workloads.
The event storage and backup pipeline
The following diagram shows the Event Storage and Backup Pipeline
This pipeline is comprised of an Amazon SQS queue that buffers the events delivered by the Amazon SNS topic, an Amazon Lambda function that automatically polls for these events in the queue and pushes them into an stream, and an Amazon S3 bucket that durably backs up the events loaded by the stream.

To fine-tune the behavior of your Firehose stream, you can configure it to buffer, transform, and compress your events prior to loading them into the bucket. As events are loaded, you can use Amazon Athena to query the bucket using standard SQL queries. You can also configure the pipeline to reuse an existing Amazon S3 bucket or create a new one.
The event search and analytics pipeline
The following diagram shows the Event Search and Analytics Pipeline
This pipeline is comprised of an Amazon SQS queue that buffers the events delivered by the Amazon SNS topic, an Amazon Lambda function that polls events from the queue and pushes them into an stream, an Amazon OpenSearch Service domain that indexes the events loaded by the Firehose stream, and an Amazon S3 bucket that stores the dead-letter events that can’t be indexed in the search domain.
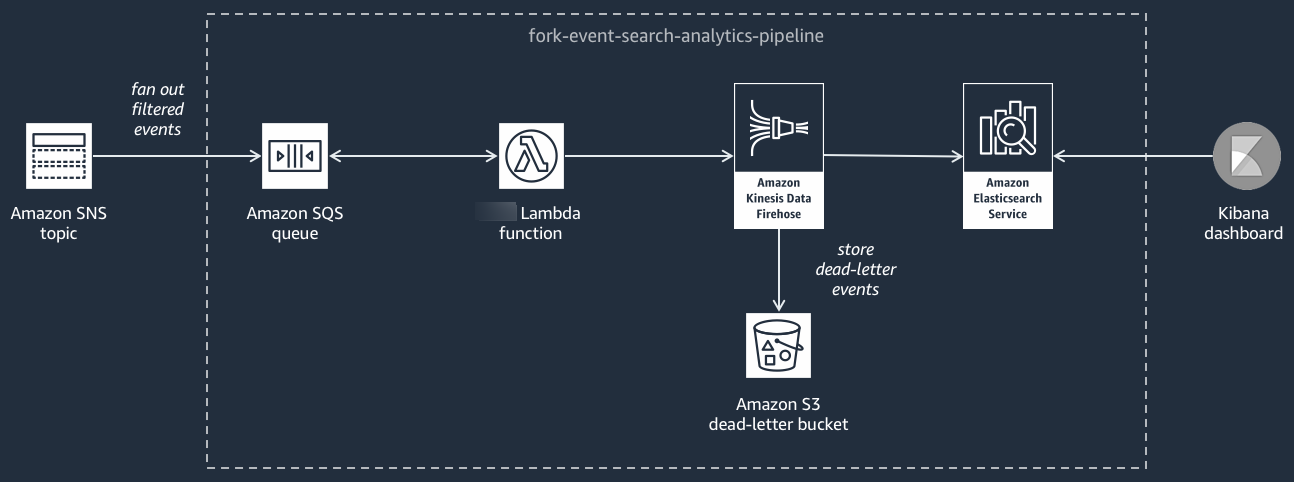
To fine-tune your Firehose stream in terms of event buffering, transformation, and compression, you can configure this pipeline.
You can also configure whether the pipeline should reuse an existing OpenSearch domain in your Amazon Web Services account or create a new one for you. As events are indexed in the search domain, you can use Kibana to run analytics on your events and update visual dashboards in real-time.
The event replay pipeline
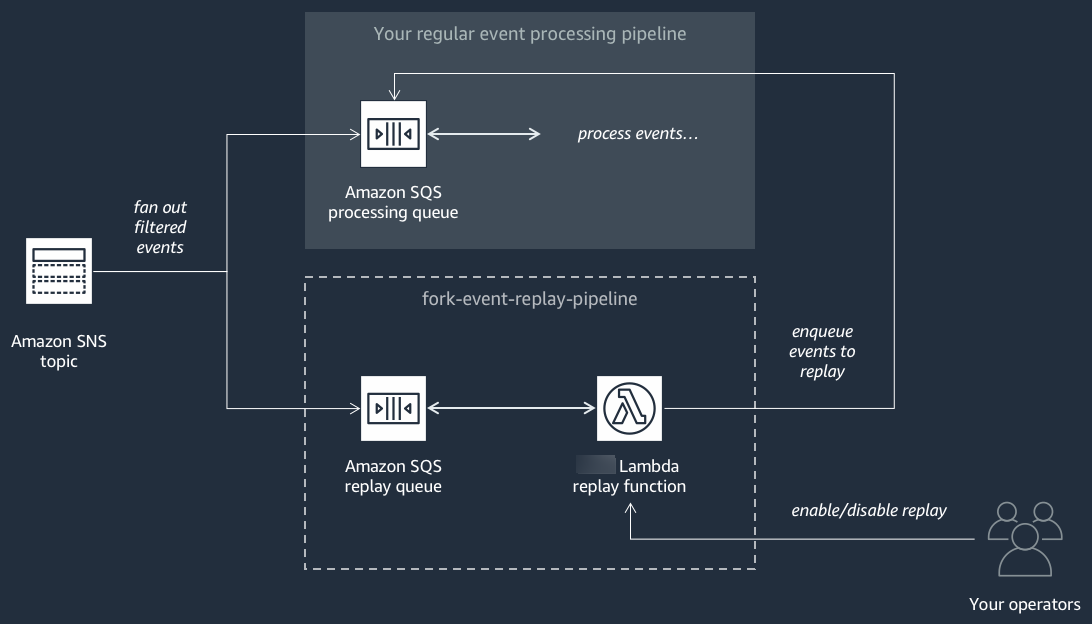
The following diagram shows the Event Replay Pipeline
This pipeline is comprised of an Amazon SQS queue that buffers the events delivered by the Amazon SNS topic, and an Amazon Lambda function that polls events from the queue and redrives them into your regular event processing pipeline, which is also subscribed to your topic.
Note
By default, the replay function is disabled, not redriving your events. If you need to reprocess events, you must enable the Amazon SQS replay queue as an event source for the Amazon Lambda replay function.
Deploying Amazon Event Fork Pipelines
The Amazon Event Fork Pipelines suite
In a production scenario, we recommend embedding Amazon Event Fork Pipelines within your overall
application's Amazon SAM template. The nested-application feature lets you do this by adding
the resource AWS::Serverless::Application to your Amazon SAM template, referencing the
Amazon SAR ApplicationId and the SemanticVersion of the nested
application.
For example, you can use the Event Storage and Backup Pipeline as a nested application by
adding the following YAML snippet to the Resources section of your Amazon SAM
template.
Backup:
Type: AWS::Serverless::Application
Properties:
Location:
ApplicationId: arn:aws-cn:serverlessrepo:us-east-2:123456789012:applications/fork-event-storage-backup-pipeline
SemanticVersion: 1.0.0
Parameters:
#The ARN of the Amazon SNS topic whose messages should be backed up to the Amazon S3 bucket.
TopicArn: !Ref MySNSTopicWhen you specify parameter values, you can use Amazon CloudFormation intrinsic functions to reference
other resources in your template. For example, in the YAML snippet above, the
TopicArn parameter references the AWS::SNS::Topic resource
MySNSTopic, defined elsewhere in the Amazon SAM template. For more information, see
the Intrinsic Function
Reference in the Amazon CloudFormation User Guide.
Note
The Amazon Lambda console page for your Amazon SAR application includes the Copy as SAM Resource button, which copies the YAML required for nesting an Amazon SAR application to the clipboard.