使用爬网程序填充 Data Catalog
您可以使用 Amazon Glue 爬网程序,将数据库和表填充到 Amazon Glue Data Catalog。这是大多数 Amazon Glue 用户使用的主要方法。爬网程序可以在单次运行中爬取多个数据存储。完成后,爬网程序会在数据目录中创建或更新一个或多个表。您在 Amazon Glue 中定义的提取、转换和加载(ETL)任务使用这些数据目录表作为源和目标。ETL 任务从在源和目标数据目录表中指定的数据存储中读取内容并向其中写入内容。
工作流
以下流程图显示了 Amazon Glue 爬网程序如何与数据存储和其他元素交互来填充数据目录。
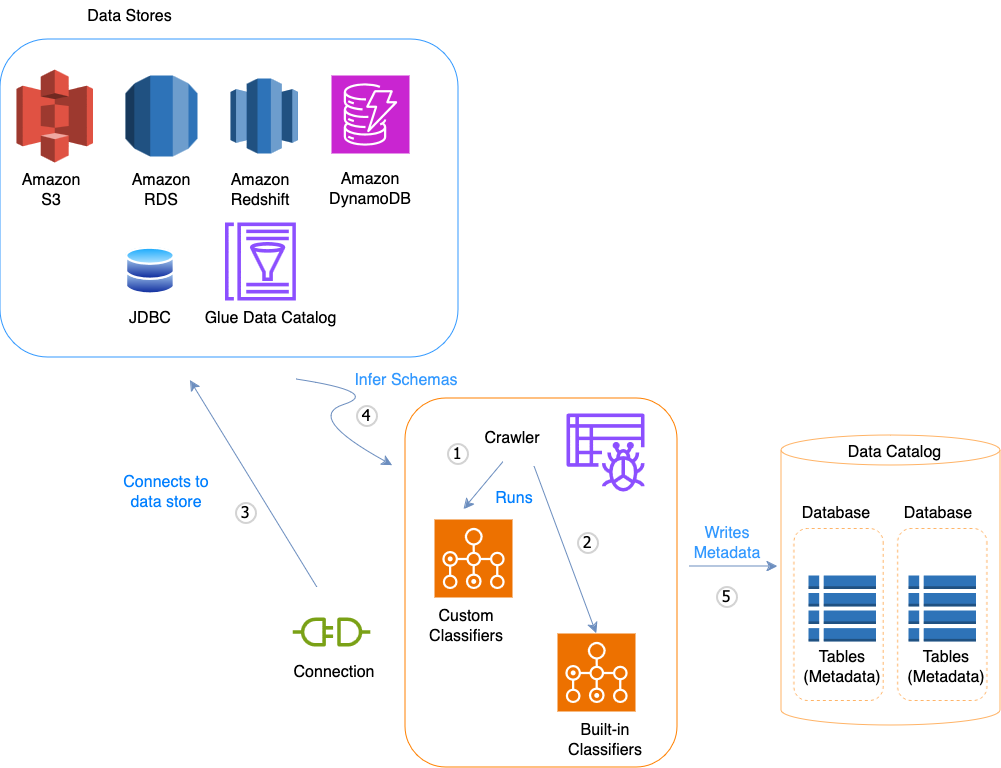
以下是爬网程序如何填充 Amazon Glue Data Catalog 的一般工作流程:
-
爬网程序运行您为推断数据的格式和架构而选择的任何自定义分类器。您为自定义分类器提供代码,它们按您指定的顺序运行。
第一个成功识别您的数据结构的自定义分类器用于创建架构。将会跳过列表中较低的自定义分类器。
-
如果没有自定义分类器与您的数据的架构匹配,则内置分类符会尝试识别数据的架构。内置分类器的示例是一个可识别 JSON 的分类器。
-
爬网程序连接到数据存储。某些数据存储需要使用连接属性才能访问爬网程序。
-
将会为您的数据创建推断的架构。
-
爬网程序向数据目录写入元数据。表定义包含有关您的数据存储中的数据的元数据。该表被写入一个充当数据目录中表的容器的数据库。表的属性包括分类,它是由推断表架构的分类器创建的标签。
主题
爬网程序的工作原理
爬网程序在运行时,会执行以下操作来询问数据存储:
-
对数据分类,以确定原始数据的格式、架构和关联属性 – 您可以通过创建自定义分类器来配置分类结果。
-
将数据分组为表或分区 – 根据爬网程序探试算法对数据分组。
-
将元数据写入数据目录 – 您可以配置爬网程序如何添加、更新和删除表和分区。
在定义爬网程序时,您可以选择一个或多个分类器来评估用于推断架构的数据的格式。当爬网程序运行时,列表中的第一个分类器可以成功识别您的数据存储,用于为表创建架构。您可以使用内置分类器或定义您自己的分类器。您可以在定义爬网程序之前,在单独的操作中定义您的自定义分类器。Amazon Glue 提供内置分类器,用于使用包含 JSON、CSV 和 Apache Avro 的格式从公共文件中推断架构。有关 Amazon Glue 中内置分类器的当前列表,请参阅内置分类器。
爬网程序创建的元数据表包含在定义爬网程序时的数据库中。如果爬网程序未指定数据库,则您的表将放置在默认数据库中。此外,每个表都有一个分类列,由第一个成功识别数据存储的分类器填充。
如果已爬取的文件被压缩,则爬网程序必须下载它才能处理它。在爬网程序运行时,它会询问文件以确定其格式和压缩类型,并将这些属性写入数据目录。某些文件格式(例如 Apache Parquet)允许您在写入文件时压缩文件的一部分。对于这些文件,压缩的数据是文件的内部组件,在将表写入数据目录时,Amazon Glue 不会填充 compressionType 属性。相反,如果整个文件通过压缩算法(例如 gzip)来压缩,则在将表写入数据目录时,会填充 compressionType 属性。
爬网程序为它创建的表生成名称。存储在 Amazon Glue Data Catalog 中的表的名称遵循以下规则:
-
仅允许使用字母数字字符和下划线 (
_)。 -
任何自定义前缀均不能超过 64 个字符。
-
名称的最大长度不能超过 128 个字符。爬网程序截断生成的名称以适应限制范围。
-
如果遇到重复的表名,则爬网程序会向名称中添加哈希字符串后缀。
如果您的爬网程序多次运行 (也许是按计划),它会在您的数据存储中查找新的或已更改的文件或表。爬网程序的输出包括自上次运行以来找到的新表和分区。
爬网程序如何确定何时创建分区?
当 Amazon Glue 爬网程序扫描 Amazon S3 数据存储并检测到某个存储桶中有多个文件夹时,它会在文件夹结构中确定表的根,以及哪些文件夹是表的分区。表的名称基于 Amazon S3 前缀或文件夹名称。您提供一个包含路径,它指向要爬网的文件夹级别。当某个文件夹级别的大部分架构都相似时,爬网程序将创建一个表而不是独立表的分区。要影响爬网程序,以创建单独的表,可在定义爬网程序时将每个表的根文件夹添加为单独的数据存储。
例如,考虑以下 Amazon S3 文件夹结构。

四个最低级别文件夹的路径如下:
S3://sales/year=2019/month=Jan/day=1 S3://sales/year=2019/month=Jan/day=2 S3://sales/year=2019/month=Feb/day=1 S3://sales/year=2019/month=Feb/day=2
假设爬网程序目标设置为 Sales,并且 day=n 文件夹中的所有文件都具有相同的格式(例如 JSON,未加密),并且具有相同或非常相似的架构。爬网程序将创建一个包含四个分区的表,分区键为 year、month 和 day。
在下一个示例中,考虑以下 Amazon S3 结构:
s3://bucket01/folder1/table1/partition1/file.txt s3://bucket01/folder1/table1/partition2/file.txt s3://bucket01/folder1/table1/partition3/file.txt s3://bucket01/folder1/table2/partition4/file.txt s3://bucket01/folder1/table2/partition5/file.txt
如果 table1 和 table2 下的文件架构相似,并且在爬网程序中通过包含路径 s3://bucket01/folder1/ 定义了单个数据存储,爬网程序将创建一个具有两个分区键列的表。第一个分区键列包含 table1 和 table2,第二个分区键列包含 table1 分区的 partition1 到 partition3 以及 table2 分区的 partition4 和 partition5。要创建两个单独的表,可用两个数据存储来定义爬网程序。在本示例中,将第一个包含路径定义为 s3://bucket01/folder1/table1/,将第二个定义为 s3://bucket01/folder1/table2。
注意
在 Amazon Athena 中,每个表对应一个 Amazon S3 前缀,所有对象都在其中。如果对象具有不同架构,Athena 则不会将同一前缀内的不同对象识别为不同的表。如果爬网程序从同一个 Amazon S3 前缀中创建多个表,则可能出现这种情况。这可能会导致 Athena 中的查询返回零个结果。为使 Athena 正确识别和查询表,请在创建爬网程序时,使 Amazon S3 文件夹结构中的每个不同的表架构具有单独的包含路径。有关更多信息,请参阅将 Athena 与 Amazon Glue 一起使用时的最佳实践以及这篇 Amazon 知识中心文章