Redshift 连接
您可以使用 Amazon Glue for Spark 读取和写入 Amazon Redshift 数据库中的表。连接到 Amazon Redshift 数据库时,Amazon Glue 使用 Amazon Redshift SQL COPY 和 UNLOAD 命令并通过 Amazon S3 移动数据以实现最大吞吐量。在 Amazon Glue 4.0 及更高版本中,您可以使用适用于 Apache Spark 的 Amazon Redshift 集成进行读写,除了通过先前版本连接时可用的优化和功能外,还具有特定于 Amazon Redshift 的优化和功能。
了解 Amazon Glue 如何让 Amazon Redshift 用户比以往任何时候都更轻松地迁移到 Amazon Glue 进行无服务器数据集成和 ETL。
配置 Redshift 连接
要在 Amazon Glue 中使用 Amazon Redshift 集群,需要具备一些先决条件:
-
读取和写入数据库时用于临时存储的 Amazon S3 目录。
-
Amazon VPC,允许在 Amazon Redshift 集群、Amazon Glue 作业和 Amazon S3 目录之间进行通信。
-
对 Amazon Glue 作业和 Amazon Redshift 集群具有相应的 IAM 权限。
配置 IAM 角色
为 Amazon Redshift 集群设置角色
您的 Amazon Redshift 集群需要能够读取和写入 Amazon S3,才能与 Amazon Glue 作业集成。为此,您可以将 IAM 角色与要连接的新 Amazon Redshift 集群关联。您的角色应具有允许读取和写入 Amazon S3 临时目录的策略。您的角色应该有信任关系,允许 redshift.amazonaws.com 服务连接到 AssumeRole。
将 IAM 角色与 Amazon Redshift 关联
先决条件:用于临时存储文件的 Amazon S3 存储桶或目录。
-
确定您的 Amazon Redshift 集群需要哪些 Amazon S3 权限。在将数据移入和移出 Amazon Redshift 集群时,Amazon Glue 任务会对 Amazon Redshift 发出 COPY 和 UNLOAD 语句。如果您的作业修改了 Amazon Redshift 中的表,Amazon Glue 还会发出 CREATE LIBRARY 语句。有关 Amazon Redshift 执行这些语句所需的特定 Amazon S3 权限的信息,请参阅 Amazon Redshift 文档:Amazon Redshift: Permissions to access other Amazon Resources。
在 IAM 控制台中,创建具有必要权限的 IAM policy。有关创建策略的更多信息,请参阅 Creating IAM policies。
在 IAM 控制台中,创建角色和信任关系,允许 Amazon Redshift 担任该角色。按照 IAM 文档为 Amazon 服务(控制台)创建角色中的说明操作
当系统要求选择 Amazon 服务用例时,选择“Redshift - 可自定义”。
当系统要求附加策略时,请选择您之前定义的策略。
注意
有关为 Amazon Redshift 配置角色的更多信息,请参阅 Amazon Redshift 文档中的 Authorizing Amazon Redshift to access other Amazon services on your behalf。
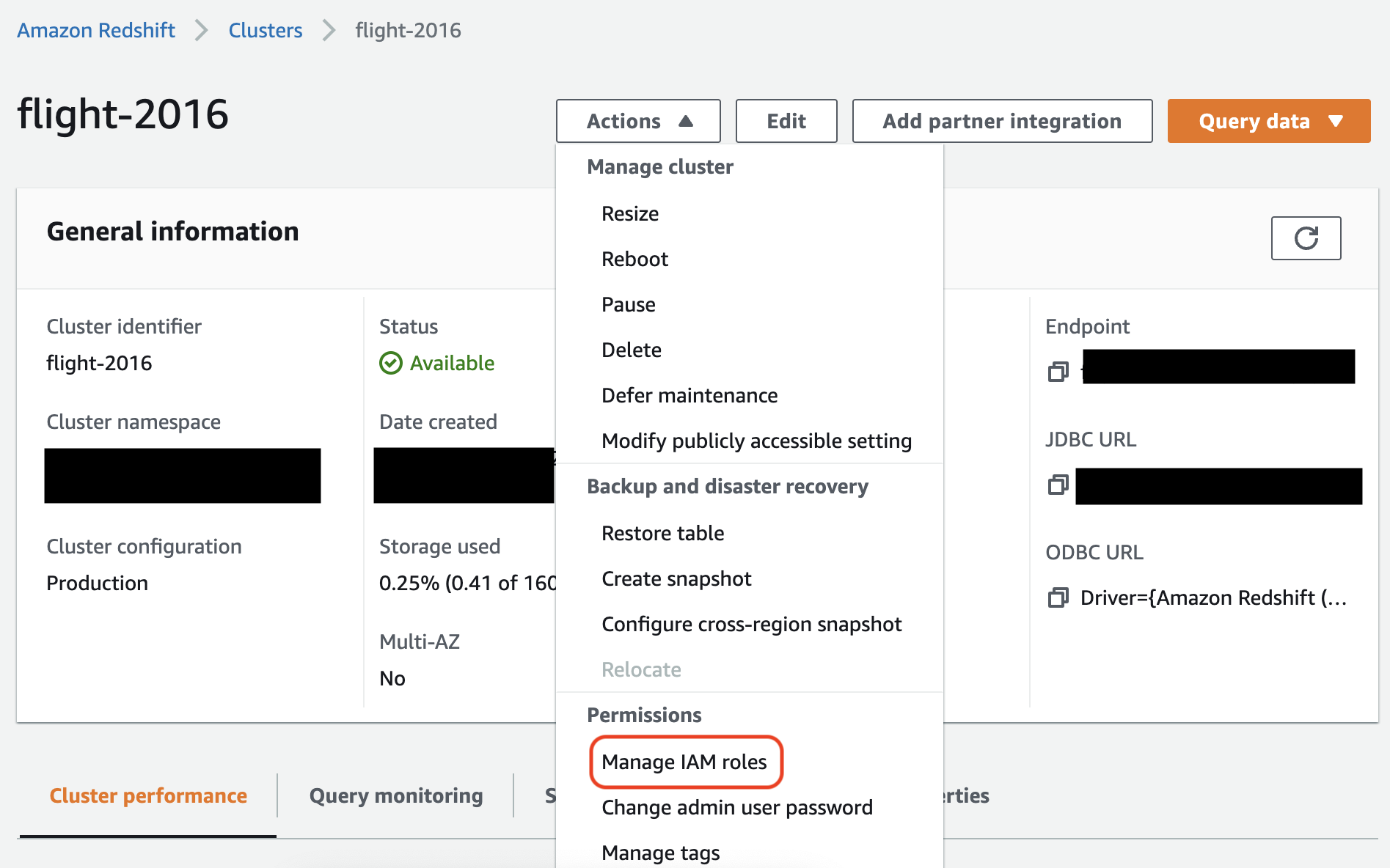
在 Amazon Redshift 控制台中,将角色与您的 Amazon Redshift 集群关联。按照 Amazon Redshift 文档中的说明操作。
在 Amazon Redshift 控制台中选择突出显示的选项,配置此设置:
注意
默认情况下,Amazon Glue 作业会传入使用您指定的角色创建的 Amazon Redshift 临时凭证来运行作业。我们建议不使用这些凭证。出于安全考虑,这些凭证将在 1 小时后过期。
为 Amazon Glue 作业设置角色
Amazon Glue 作业需要角色才能访问 Amazon S3 存储桶。您不需要 Amazon Redshift 集群的 IAM 权限,您的访问权限由 Amazon VPC 中的连接和您的数据库凭证控制。
设置 Amazon VPC
设置 Amazon Redshift 数据存储访问权限
登录到 Amazon Web Services 管理控制台并打开 Amazon Redshift 控制台,网址:https://console.aws.amazon.com/redshiftv2/
。 -
在左侧导航窗格中,选择集群。
-
选择要从 Amazon Glue 访问的集群名称。
-
在 Cluster Properties (集群属性) 部分,从 VPC security groups (VPC 安全组) 中选择一个安全组以允许 Amazon Glue 使用。记录下所选的安全组名称以供将来参考。选择安全组将打开 Amazon EC2 控制台 Security Groups (安全组) 列表。
-
选择要修改的安全组并导航到入站选项卡。
-
添加一个自引用规则,以允许 Amazon Glue 组件进行通信。具体来讲,添加或确认有一条类型为
All TCP的规则,协议为TCP,端口范围包括所有端口,其源具有与组 ID相同的安全组名。入站规则类似如下:
Type 协议 端口范围 来源 所有 TCP
TCP
0–65535
database-security-group
例如:

-
同时也为出站流量添加一条规则。打开到所有端口的出站流量,例如:
Type 协议 端口范围 目标 所有流量
ALL
ALL
0.0.0.0/0
或创建一条 Type (类型) 为
All TCP、Protocol (协议) 为TCP、Port Range (端口范围) 包括所有端口及其 Destination (目标) 具有与 Group ID (组 ID) 相同的安全组名称的自引用规则。如果使用 Amazon S3 VPC 终端节点,还可以添加 HTTPS 规则以访问 Amazon S3。安全组规则中必须提供s3-prefix-list-id以允许从该 VPC 到 Amazon S3 VPC 终端节点的流量。例如:
Type 协议 端口范围 目标 所有 TCP
TCP
0–65535
security-groupHTTPS
TCP
443
s3-prefix-list-id
设置 Amazon Glue
您需要创建一个提供 Amazon VPC 连接信息的 Amazon Glue Data Catalog 连接。
在控制台中配置 Amazon Redshift Amazon VPC 与 Amazon Glue 的连接
-
按照步骤创建 Data Catalog 连接:添加 Amazon Glue 连接。创建连接后,保留连接名称
connectionName,以供下一步使用。选择连接类型时,请选择 Amazon Redshift。
选择 Redshift 集群时,按名称选择集群。
为集群上的 Amazon Redshift 用户提供默认连接信息。
您的 Amazon VPC 设置将自动配置。
注意
通过 Amazon SDK 创建 Amazon Redshift 连接时,您需要手动为 Amazon VPC 提供
PhysicalConnectionRequirements。 -
在 Amazon Glue 作业配置中,提供
connectionName作为附加网络连接。
示例:从 Amazon Redshift 表中读取
您可以从 Amazon Redshift 集群和 Amazon Redshift Serverless 环境中读取。
先决条件:您想读取的 Amazon Redshift 表。按照上一节 配置 Redshift 连接 中的步骤进行操作,之后您应该拥有临时目录 temp-s3-dir 和 IAM 角色 rs-role-name 的 Amazon S3 URI(在账户 role-account-id 中)。
示例:写入 Amazon Redshift 表
您可以写入 Amazon Redshift 集群和 Amazon Redshift Serverless 环境。
先决条件:一个 Amazon Redshift 集群,以及按照上一节 配置 Redshift 连接 中的步骤进行操作,之后您应该拥有临时目录 temp-s3-dir 和 IAM 角色 rs-role-name 的 Amazon S3 URI(在账户 role-account-id 中)。您还需要想写入数据库的内容的 DynamicFrame。
Amazon Redshift 连接选项参考
用于所有 Amazon Glue JDBC 连接的基本连接选项在所有 JDBC 类型中都是一致的,用于设置 url、user 和 password 之类的信息。有关标准 JDBC 参数的更多信息,请参阅 JDBC 连接选项参考。
Amazon Redshift 连接类型需要一些额外的连接选项:
-
"redshiftTmpDir":(必需)从数据库中复制时,可以用于暂存临时数据的 Amazon S3 路径。 -
"aws_iam_role":(可选)IAM 角色的 ARN。Amazon Glue 作业会将此角色传递给 Amazon Redshift 集群,以授予完成作业指令所需的集群权限。
Amazon Glue 4.0+ 版本中提供了其他连接选项
您也可以通过 Amazon Glue 连接选项传递新的 Amazon Redshift 连接器的选项。有关支持的连接器选项的完整列表,请参阅适用于 Apache Spark 的 Amazon Redshift 集成中的 Spark SQL 参数部分。
为方便起见,我们在此重申某些新选项:
| 名称 | 必需 | 默认值 | 说明 |
|---|---|---|---|
| autopushdown |
否 | TRUE | 通过捕获和分析 SQL 操作的 Spark 逻辑计划,应用谓词和查询下推。这些操作转换为 SQL 查询,然后在 Amazon Redshift 中运行以提高性能。 |
| autopushdown.s3_result_cache |
否 | FALSE | 缓存 SQL 查询以将 Amazon S3 路径映射的数据卸载到内存中,以便同一查询不需要在同一 Spark 会话中再次运行。仅在启用 |
| unload_s3_format |
否 | PARQUET | PARQUET — 以 Parquet 格式卸载查询结果。 TEXT — 以竖线分隔的文本格式卸载查询结果。 |
| sse_kms_key |
否 | 不适用 | 在 |
| extracopyoptions |
否 | 不适用 | 加载数据时附加到 Amazon Redshift 请注意,由于这些选项附加到 |
| cvsnullstring(实验) |
否 | NULL | 使用 CSV |
这些新参数可以通过以下方式使用。
提高性能的新选项
新的连接器推出了一些新的性能改进选项:
-
autopushdown:默认情况下启用。 -
autopushdown.s3_result_cache:默认情况下禁用。 -
unload_s3_format:默认为PARQUET。
有关使用这些选项的信息,请参阅适用于 Apache Spark 的 Amazon Redshift 集成。我们建议您在进行混合读取和写入操作时不要开启
autopushdown.s3_result_cache,因为缓存的结果可能包含过时的信息。UNLOAD 命令的默认选项 unload_s3_format 设置为 PARQUET,以提高性能并降低存储成本。要使用 UNLOAD 命令的默认行为,请将该选项重置为 TEXT。
新的读取加密选项
默认情况下,从 Amazon Redshift 表读取数据时,Amazon Glue 使用的临时文件夹中的数据使用 SSE-S3 加密进行加密。要使用来自 Amazon Key Management Service(Amazon KMS)的客户自主管理型密钥来加密您的数据,您可以设置 ("sse_kms_key"
→ kmsKey),其中 ksmKey 是来自 Amazon KMS 的密钥 ID,而不是 Amazon Glue 版本 3.0 中的传统设置选项 ("extraunloadoptions" →
s"ENCRYPTED KMS_KEY_ID '$kmsKey'")。
datasource0 = glueContext.create_dynamic_frame.from_catalog( database = "database-name", table_name = "table-name", redshift_tmp_dir = args["TempDir"], additional_options = {"sse_kms_key":"<KMS_KEY_ID>"}, transformation_ctx = "datasource0" )
支持基于 IAM 的 JDBC URL
新的连接器支持基于 IAM 的 JDBC URL,因此您无需传递用户/密码或密钥。通过基于 IAM 的 JDBC URL,连接器可使用作业运行时角色访问 Amazon Redshift 数据源。
步骤 1:将以下最低要求策略附加到您的 Amazon Glue 作业运行时角色。
步骤 2:使用基于 IAM 的 JDBC URL,如下所示。使用您连接的 Amazon Redshift 用户名指定一个新选项 DbUser。
conn_options = { // IAM-based JDBC URL "url": "jdbc:redshift:iam://<cluster name>:<region>/<database name>", "dbtable": dbtable, "redshiftTmpDir": redshiftTmpDir, "aws_iam_role": aws_iam_role, "DbUser": "<Redshift User name>" // required for IAM-based JDBC URL } redshift_write = glueContext.write_dynamic_frame.from_options( frame=dyf, connection_type="redshift", connection_options=conn_options ) redshift_read = glueContext.create_dynamic_frame.from_options( connection_type="redshift", connection_options=conn_options )
注意
DynamicFrame 目前在 GlueContext.create_dynamic_frame.from_options 工作流程中仅支持对
DbUser 使用基于 IAM 的 JDBC URL。
从 Amazon Glue 版本 3.0 迁移到版本 4.0
在 Amazon Glue 版本 4.0 中,ETL 作业可以访问新 Amazon Redshift Spark 连接器和新 JDBC 驱动程序,但选项和配置不同。全新 Amazon Redshift 连接器和驱动程序在编写时充分考虑了性能,可保持数据的交易一致性。这些产品记录在 Amazon Redshift 文档中。有关更多信息,请参阅:
表/列名和标识符限制
新的 Amazon Redshift Spark 连接器和驱动程序对 Redshift 表名称的要求更为严格。有关更多信息,请参阅名称和标识符以定义您的 Amazon Redshift 表名称。作业书签工作流程可能不适用于不符合规则的表名和某些字符(例如空格)。
如果您的旧表的名称不符合名称和标识符规则,并且发现书签存在问题(作业正在重新处理旧的 Amazon Redshift 表数据),我们建议您重命名表名。有关更多信息,请参阅修改表示例。
数据帧中的默认临时格式更改
在写入到 Amazon Redshift 时,Amazon Glue 版本 3.0 Spark 连接器会将 tempformat 的默认值设置为 CSV。为了保持一致,在 Amazon Glue 3.0 版中,
DynamicFrame 仍会将 tempformat 的默认值设置为使用 CSV。如果您之前曾在 Amazon Redshift Spark 连接器上直接使用过 Spark Dataframe API,则可以在 DataframeReader/Writer 选项中将 tempformat 明确设置为 CSV。否则,tempformat 在新 Spark 连接器中默认为 AVRO。
行为更改:将 Amazon Redshift 数据类型 REAL 映射到 Spark 数据类型 FLOAT,而不是 DOUBLE
在 Amazon Glue 3.0 版本中,Amazon Redshift REAL 被转换为 Spark
DOUBLE 类型。新的 Amazon Redshift Spark 连接器更新了行为,因此 Amazon Redshift
REAL 类型可以转换为 Spark FLOAT 类型,然后从这一类型转换回来。如果您的旧用例仍希望将 Amazon Redshift REAL 类型映射到 Spark DOUBLE 类型,则可以使用以下解决方法:
-
对于
DynamicFrame,使用DynamicFrame.ApplyMapping将Float类型映射到Double类型。对于Dataframe,需要使用cast。
代码示例:
dyf_cast = dyf.apply_mapping([('a', 'long', 'a', 'long'), ('b', 'float', 'b', 'double')])
处理 VARBYTE 数据类型
在处理 Amazon Glue 3.0 和 Amazon Redshift 数据类型时,Amazon Glue 3.0 会将 Amazon Redshift VARBYTE 转换为 Spark STRING 类型。但是,最新的 Amazon Redshift Spark 连接器不支持 VARBYTE 数据类型。要解决此限制,您可以创建一个 Redshift 视图,将 VARBYTE 列转换为支持的数据类型。然后,使用新的连接器从此视图(而不是原始表)加载数据,这样既能确保兼容性,又能保持对 VARBYTE 数据的访问。
Redshift 查询示例:
CREATE VIEWview_nameAS SELECT FROM_VARBYTE(varbyte_column, 'hex') FROMtable_name