Amazon Glue概念
Amazon Glue 是一项完全托管式的 ETL(提取、转换、加载)服务,让您能够在不同的数据来源和目标之间轻松移动数据。关键组件包括:
-
Data Catalog:一种元数据存储,其中包含 ETL 工作流的表定义、作业定义和其他控制信息。
-
爬网程序:连接到数据来源、推断数据架构以及在 Data Catalog 中创建元数据表定义的程序。
-
ETL 作业:从源中提取数据、使用 Apache Spark 脚本进行转换并将其加载到目标中的业务逻辑。
-
触发器:基于计划或事件启动作业运行的机制。
典型的工作流涉及:
-
在 Data Catalog 中定义数据来源和目标。
-
通过爬网程序以使用来自数据来源的表元数据填充 Data Catalog。
-
使用转换脚本定义 ETL 作业,以移动和处理数据。
-
按需运行作业或基于触发器运行作业。
-
使用控制面板监控作业性能。
下图表明了 Amazon Glue 环境的架构。
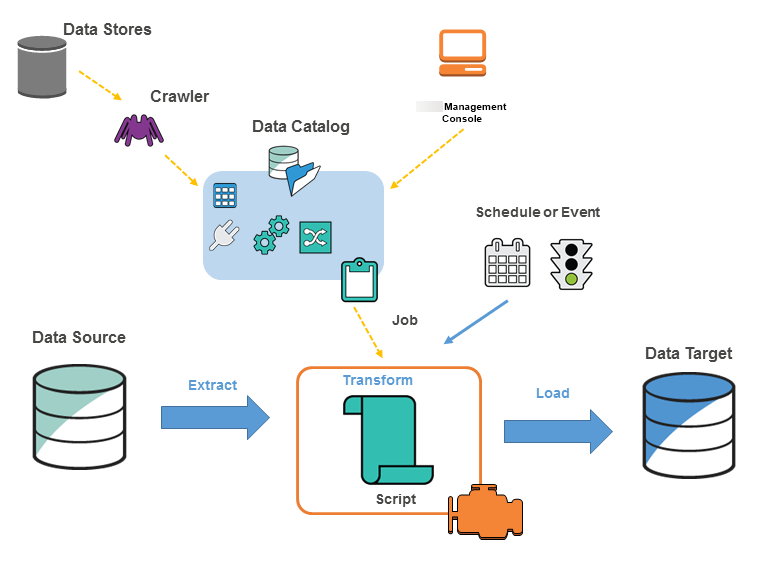
您可以在 中定义作业Amazon Glue来完成从数据源提取、转换和加载 (ETL) 数据到数据目标所需的工作。您通常会执行以下操作:
-
对于数据存储源,您定义爬网程序 以使用元数据表定义填充 Amazon Glue Data Catalog。您将爬网程序指向数据存储,并且爬网程序在数据目录中创建表定义。对于流式处理源,您可以手动定义数据目录表并指定数据流属性。
除了表定义,Amazon Glue Data Catalog 还包含定义其他 ETL 作业所需的其他元数据。在定义作业以转换数据时,您可以使用此元数据。
Amazon Glue 可以生成用于转换数据的脚本。或者,您可以在 Amazon Glue 控制台或 API 中提供脚本。
-
您可以按需运行任务,也可以将其设置为在指定的触发器发生时启动。触发器可以是基于时间的计划或事件。
当您的任务运行时,脚本从数据源中提取数据,转换数据,并将其加载到数据目标。该脚本在 Amazon Glue 中的 Apache Spark 环境内运行。
重要
Amazon Glue 中的表和数据库是 Amazon Glue Data Catalog 中的对象。它们包含元数据;它们不包含数据存储中的数据。
|
基于文本的数据(如 CSV)必须采用 |
Amazon Glue 术语
Amazon Glue 依赖于多个组件之间的交互来创建和管理您的提取、转换、加载(ETL)工作流程。
Amazon Glue Data Catalog
Amazon Glue 中的持久元数据存储。它包含表定义、作业定义以及其他用于管理您的 Amazon Glue 环境的控制信息。每个 Amazon 账户在每个区域有一个 Amazon Glue Data Catalog。
分类器
确定您的数据的架构。Amazon Glue 提供常见文件类型的分类器,如 CSV、JSON、Avro、XML 等。此外,它还使用 JDBC 连接为常用关系数据库管理系统提供分类器。您可以使用 grok 模式或在 XML 文档中指定行标记来编写自己的分类器。
Connection
数据目录对象,其中包含了连接到特定数据存储所需的属性。
爬网程序
该程序连接到数据存储(源或目标),通过分类器的优先级列表不断更新以确定您的数据架构,然后在 Amazon Glue Data Catalog 中创建元数据表。
数据库
一组关联的数据目录表定义,这些定义组织到一个逻辑组内。
数据存储、数据源、数据目标
数据存储是持久存储数据的存储库。示例包括 Amazon S3 存储桶和关系数据库。数据源是用作进程或转换输入的数据存储。数据目标是进程或转换写入的数据存储。
开发终端节点
一种可以用来开发和测试 Amazon Glue ETL 脚本的环境。
动态帧
支持嵌套数据(如结构和数组)的分布式表。每条记录都是自我描述,旨在使用半结构化数据实现架构灵活性。每条记录都包含数据和描述该数据的架构。您可以在 ETL 脚本中同时使用动态帧和 Apache Spark DataFrames,并在它们之间进行转换。动态帧为数据清理和 ETL 提供了一系列转换。
作业
执行 ETL 工作所需的业务逻辑。它由转换脚本、数据源和数据目标组成。作业运行通过可由事件计划或触发的触发器启动。
任务性能控制面板
Amazon Glue 为您的 ETL 任务提供一个全面的运行控制面板。控制面板显示特定时间范围内运行的任务的相关信息。
笔记本界面
通过一键式设置增强了笔记本体验,便于作业创作和数据探索。笔记本和连接都将自动为您配置。您可以使用基于 Jupyter Notebook 的笔记本界面,使用 Amazon Glue 无服务器 Apache Spark ETL 基础设施以交互方式开发、调试和部署脚本和工作流。您还可以在笔记本环境中执行临时查询、数据分析和可视化(例如,表格和图表)。
Script
从源中提取数据、转换并将其加载到目标中的代码。Amazon Glue 会生成 PySpark 或 Scala 脚本。
表
表示您的数据的元数据定义。无论您的数据是位于 Amazon Simple Storage Service(Amazon S3)文件、Amazon Relational Database Service(Amazon RDS)表还是其他数据集中,表都定义了数据的架构。Amazon Glue Data Catalog 中的表包含列的名称、数据类型定义、分区信息以及有关基本数据集的其他元数据。数据的架构在您的 Amazon Glue 表定义中表示。实际数据留存在原始数据存储中,无论是在文件中还是关系数据库表中。Amazon Glue 在 Amazon Glue Data Catalog 中编录您的文件和关系数据库表。在您创建 ETL 任务时,它们用作源和目标。
转换
用于将数据处理为其他格式的代码逻辑。
触发器
启动 ETL 任务。可以根据计划时间或事件来定义触发器。
可视化任务编辑器
可视化作业编辑器是一个图形界面,可以方便地在 Amazon Glue 中创建、运行和监控提取、转换和加载(ETL)任务。您可以直观地编写数据转换工作流,并在 Amazon Glue 的基于 Apache Spark 的无服务器 ETL 引擎上顺畅运行,检查作业的每个步骤中的模式和数据结果。
工作线程
借助 Amazon Glue,您只需按 ETL 任务运行所需时间付费。没有要管理的资源,无预付费用,您无需为启动或关闭时间付费。您将根据用于运行 ETL 任务的数据处理单元(缩写为 DPU)的数量按小时费率支付费用。单个数据处理单元(DPU)也称为一个 Worker。Amazon Glue 附带多种 Worker 类型,可帮助您选择符合作业延迟和成本要求的配置。Worker 提供标准、G.1X、G.2X、G.4X、G.8X、G.12X、G.16X、G.025XX 以及内存优化型 R.1X、R.2X、R.4X、R.8X 配置。