针对 Amazon S3 目标设置 Amazon S3 事件通知的爬网程序
按照以下步骤使用 Amazon Web Services 管理控制台或 Amazon CLI 为 Amazon S3 目标设置 Amazon S3 事件通知的爬网程序。
- Amazon Web Services 管理控制台
-
-
登录 Amazon Web Services 管理控制台,打开 GuardDuty 控制台:https://console.aws.amazon.com/guardduty/
。 -
设置爬网程序属性。有关更多信息,请参阅在 Amazon Glue 控制台上设置爬网程序配置选项。
-
在数据来源配置部分中,系统将询问您的数据是否已映射到 Amazon Glue 表?
默认情况下已选择 Not yet(尚未)。请将其保留为默认值,这是因为您使用的是 Amazon S3 数据来源,而该数据尚未映射到 Amazon Glue 表。
-
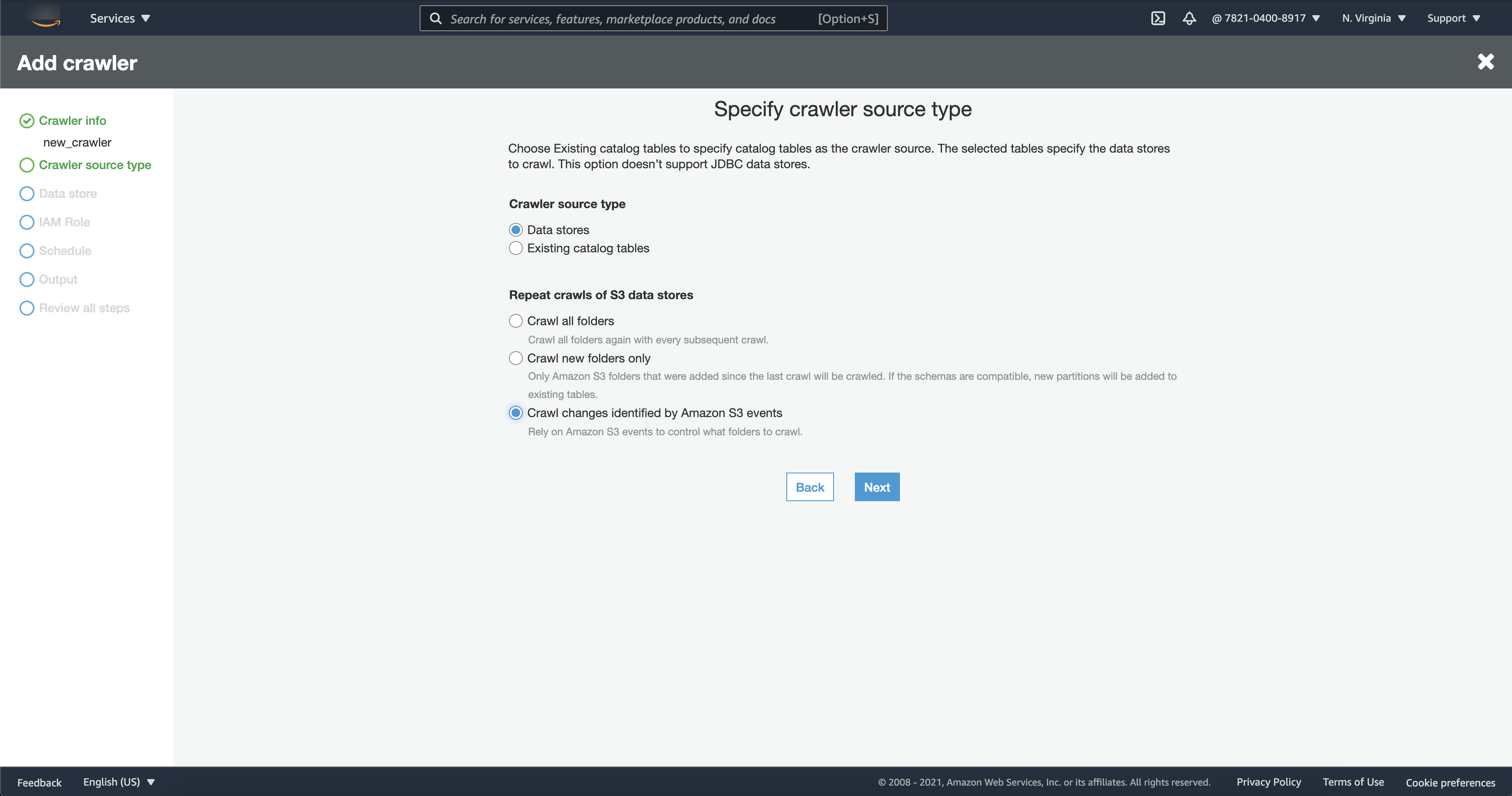
在 Data sources(数据来源)部分中,选择 Add a data source(添加数据来源)。
-
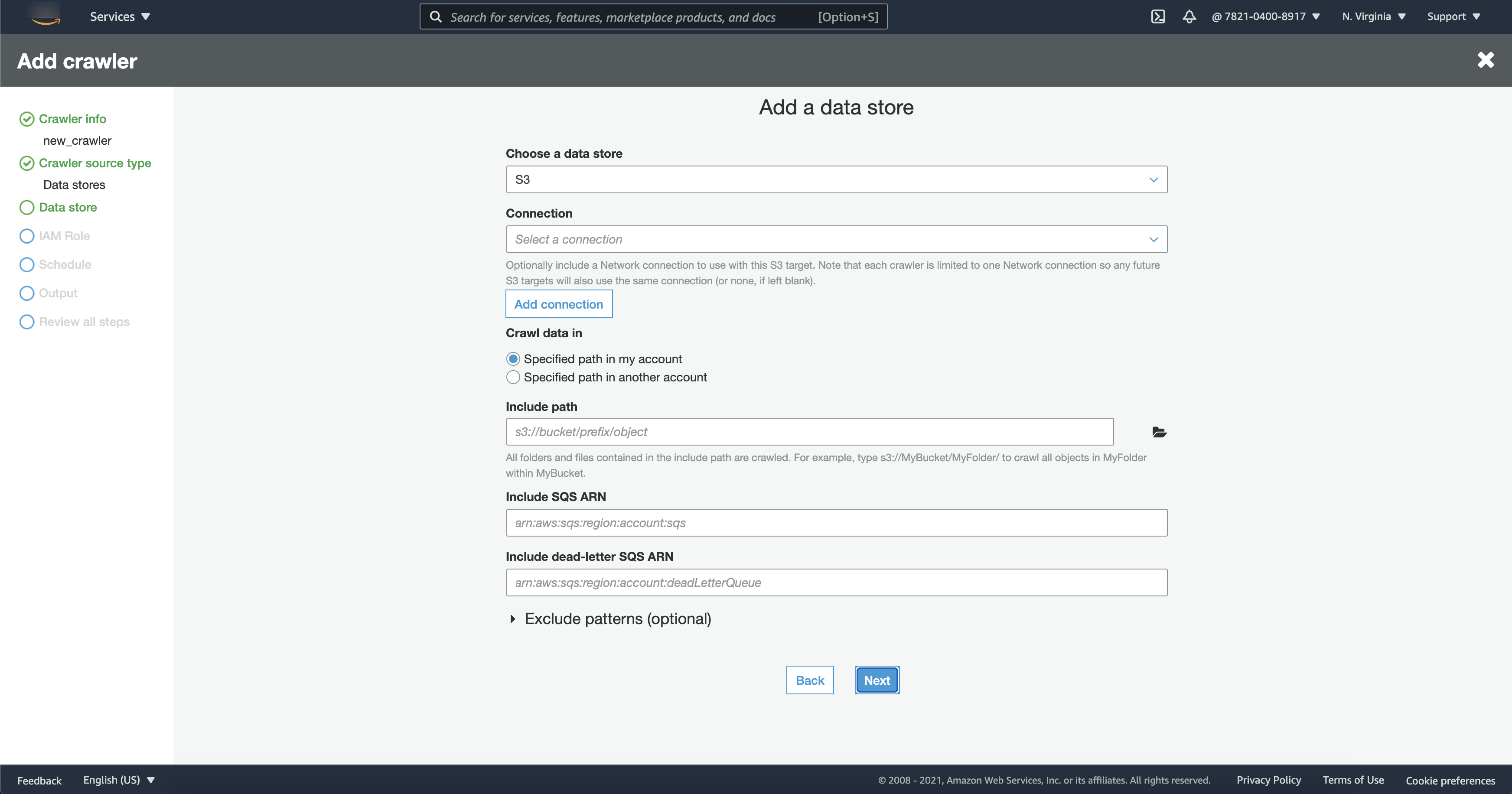
在 Add data source(添加数据来源)模态中,配置 Amazon S3 数据来源:
-
Data source(数据来源):默认选择 Amazon S3。
-
Network connection(网络连接)(可选):选择 Add new connection(添加新连接)。
-
Location of Amazon S3 data(Amazon S3 数据位置):默认选择 In this account(此账户中)。
-
Amazon S3 path(Amazon S3 路径):指定在其中爬取文件夹和文件的 Amazon S3 路径。
-
Subsequent crawler runs(后续爬网程序运行):选择 Crawl based on events(基于事件爬取)以对爬网程序使用 Amazon S3 事件通知。
-
Include SQS ARN(包含 SQS ARN):指定数据存储参数,包括有效的 SQS ARN。(例如,
arn:aws:sqs:region:account:sqs)。 -
Include dead-letter SQS ARN(包含死信 SQS ARN)(可选):指定有效的 Amazon 死信 SQS ARN。(例如,
arn:aws:sqs:region:account:deadLetterQueue)。 -
选择 Add an Amazon S3 data source(添加 Amazon S3 数据来源)。
-
-
- Amazon CLI
-
以下是 Amazon S3 Amazon CLI 调用示例,用于配置爬网程序以使用事件通知来爬取 Amazon S3 目标存储桶。
Create Crawler: aws glue update-crawler \ --name myCrawler \ --recrawl-policy RecrawlBehavior=CRAWL_EVENT_MODE \ --schema-change-policy UpdateBehavior=UPDATE_IN_DATABASE,DeleteBehavior=LOG --targets '{"S3Targets":[{"Path":"s3://amzn-s3-demo-bucket/", "EventQueueArn": "arn:aws:sqs:us-east-1:012345678910:MyQueue"}]}'