Amazon Web Services 文档中描述的 Amazon Web Services 服务或功能可能因区域而异。要查看适用于中国区域的差异,请参阅
中国的 Amazon Web Services 服务入门
(PDF)。
指定表位置和分区级别
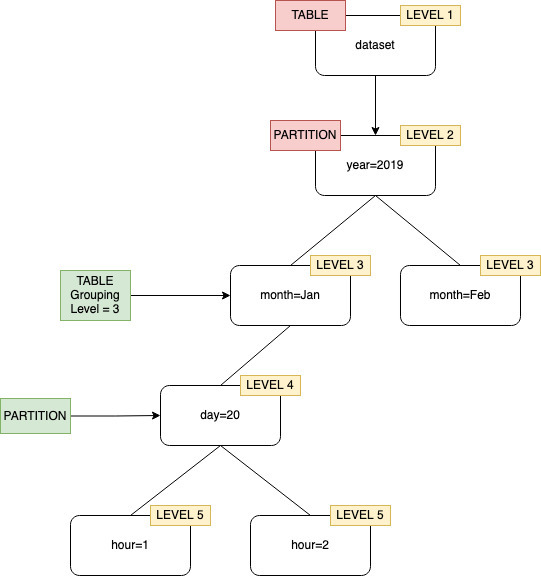
默认情况下,当爬网程序为 Amazon S3 中存储的数据定义表时,爬网程序会尝试将架构合并在一起并创建顶级表(year=2019)。在某些情况下,您可能希望爬网程序为文件夹 month=Jan 创建一个表,但由于同级文件夹(month=Mar)已合并到同一个表中,因此爬网程序会创建一个分区。
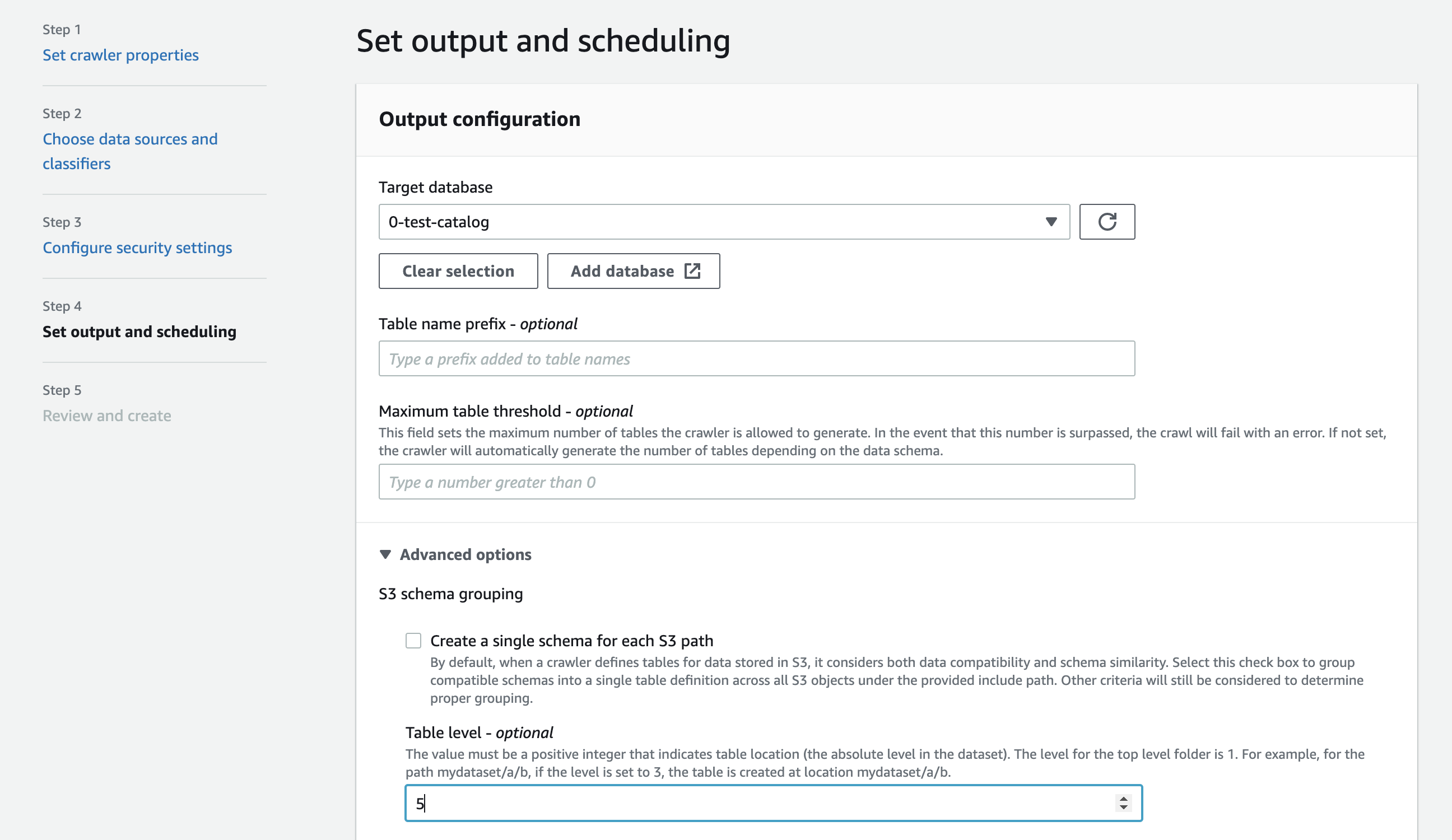
通过表级别爬网程序选项,您可以灵活地告诉爬网程序表的位置,以及您希望如何创建分区。当您指定 Table level (表级别) 时,则会从 Amazon S3 存储桶中以该绝对级别创建表。
当在控制台上配置爬网程序时,您可以为 Table level (表级别) 爬网程序选项指定一个值。该值必须是指示表位置(数据集中的绝对级别)的正整数。顶级文件夹的级别为 1。例如,对于路径 mydataset/year/month/day/hour,如果级别设置为 3,则在位置 mydataset/year/month 处创建表。
- Amazon Web Services 管理控制台
-
- Amazon CLI
-
使用 Amazon CLI 配置爬网程序时,请按示例代码所示设置 configuration 参数:
aws glue update-crawler \
--name myCrawler \
--configuration '{"Version": 1.0, "Grouping": { "TableLevelConfiguration": 2 }}'
- API
-
使用 API 配置爬网程序时,请使用以下 JSON 对象的字符串表示形式设置 Configuration 字段;例如:
configuration = jsonencode(
{
"Version": 1.0,
"Grouping": {
TableLevelConfiguration = 2
}
})
- CloudFormation
在本例中,您在 CloudFormation 模板的控制台中设置了可用的表级别选项:
"Configuration": "{
\"Version\":1.0,
\"Grouping\":{\"TableLevelConfiguration\":2}
}"