Amazon Web Services 文档中描述的 Amazon Web Services 服务或功能可能因区域而异。要查看适用于中国区域的差异,请参阅
中国的 Amazon Web Services 服务入门
(PDF)。
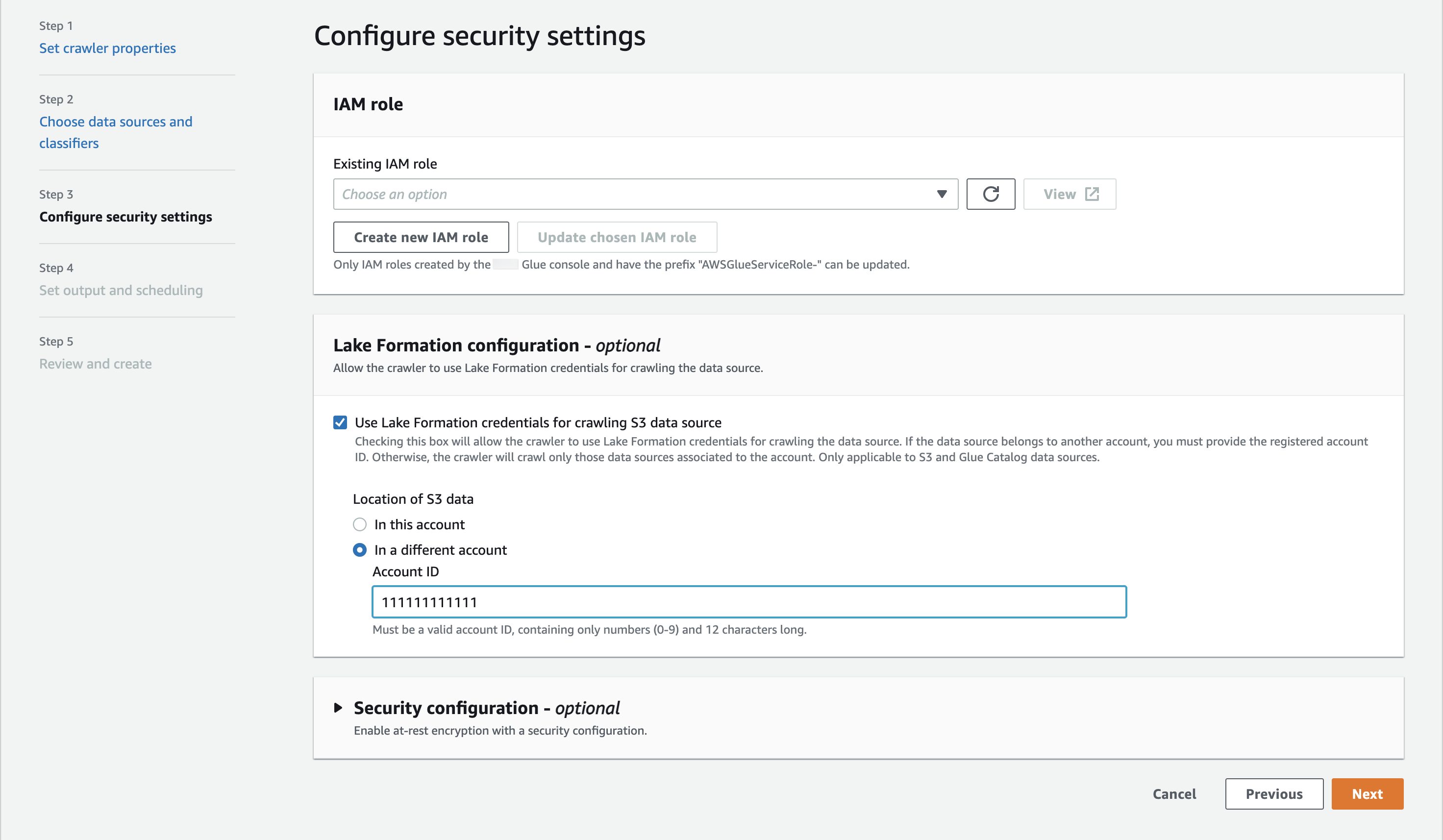
爬网程序与注册的 Amazon S3 位置位于不同账户(跨账户爬取)时所需的设置
要允许爬网程序使用 Lake Formation 凭证访问不同账户中的数据存储,您必须先向 Lake Formation 注册 Amazon S3 数据位置。然后,通过执行以下步骤向爬网程序的账户授予数据位置权限。
您可以使用 Amazon Web Services 管理控制台 或 Amazon CLI 完成以下步骤。
- Amazon Web Services 管理控制台
-
在注册 Amazon S3 位置的账户(账户 B)中:
-
向 Lake Formation 注册 Amazon S3 路径。有关更多信息,请参阅注册 Amazon S3 位置。
-
向将运行爬网程序的账户(账户 A)授予 Data location(数据位置)权限。有关更多信息,请参阅授予数据位置权限。
-
在 Lake Formation 中创建一个空数据库,将基础位置作为目标 Amazon S3 位置。有关更多信息,请参阅创建数据库。
-
授予账户 A(将运行爬网程序的账户)访问您在上一步中创建的数据库的权限。有关更多信息,请参阅授予数据库权限。
-
在创建并将运行爬网程序的账户(账户 A)中:
- Amazon CLI
-
aws glue --profile demo create-crawler --debug --cli-input-json '{
"Name": "prod-test-crawler",
"Role": "arn:aws:iam::111122223333:role/service-role/AWSGlueServiceRole-prod-test-run-role",
"DatabaseName": "prod-run-db",
"Description": "",
"Targets": {
"S3Targets":[
{
"Path": "s3://amzn-s3-demo-bucket"
}
]
},
"SchemaChangePolicy": {
"UpdateBehavior": "LOG",
"DeleteBehavior": "LOG"
},
"RecrawlPolicy": {
"RecrawlBehavior": "CRAWL_EVERYTHING"
},
"LineageConfiguration": {
"CrawlerLineageSettings": "DISABLE"
},
"LakeFormationConfiguration": {
"UseLakeFormationCredentials": true,
"AccountId": "111111111111"
},
"Configuration": {
"Version": 1.0,
"CrawlerOutput": {
"Partitions": { "AddOrUpdateBehavior": "InheritFromTable" },
"Tables": {"AddOrUpdateBehavior": "MergeNewColumns" }
},
"Grouping": { "TableGroupingPolicy": "CombineCompatibleSchemas" }
},
"CrawlerSecurityConfiguration": "",
"Tags": {
"KeyName": ""
}
}'
只有 Amazon S3 和 Data Catalog 目标支持使用 Lake Formation 凭证的爬网程序。
对于使用 Lake Formation 凭证售卖的目标,基础 Amazon S3 位置必须属于同一个桶。例如,只要所有目标位置都在同一个存储桶 (amzn-s3-demo-bucket1) 下,客户就可以使用多个目标(s3://amzn-s3-demo-bucket1/folder1、s3://amzn-s3-demo-bucket1/folder2)。不允许指定不同的存储桶(s3://amzn-s3-demo-bucket1/folder1、s3://amzn-s3-demo-bucket2/folder2)。
目前,对于 Data Catalog 目标爬网程序,只允许具有单个目录表的单个目录目标。