Amazon Glue 数据质量自动监测功能中的异常检测
工程师会同时管理数百个数据管道。每个管道都可以从不同的来源提取数据,并将数据加载到数据湖或其他数据存储库中。为了确保提供高质量的数据来做出决策,工程师制定了数据质量规则。这些规则会根据反映当前业务状态的固定标准来评估数据。但是,当业务环境发生变化时,数据属性也会发生改变,从而导致这些固定标准过时,造成数据质量不佳。
例如,一家零售公司的数据工程师制定了一条规则,其中规定日销售额必须超过 100 万美元的阈值。几个月后,日销售额突破了 200 万美元,这就导致阈值过时了。由于缺少通知,并且手动分析和更新规则需要花费大量精力,数据工程师无法更新规则来反映最新的阈值。当月晚些时候,企业用户注意到他们的销售额下降了 25%。经过数小时的调查,数据工程师发现负责从某些门店提取数据的 ETL 管道出现了故障,但并未生成错误。阈值过时的规则仍能继续成功运行,但未检测到此问题。
从另一方面来说,在这个例子中,可检测这些异常的主动警报可以让用户能够检测到这个问题。此外,跟踪业务的季节性可以突显出重大的数据质量问题。例如,周末和假日季期间的零售额可能最高,而工作日的零售额可能相对较低。与这种模式存在偏差可能表明数据质量问题或业务环境发生了变化。数据质量规则无法检测季节性模式,因为这需要高级算法,此类高级算法可以从过去的模式中学习,从而捕获季节性数据来检测偏差。
最后,由于规则创建过程需要高超的技术且编写规则需要花费大量时间,所以创建和维护规则对用户而言是非常棘手的难题。因此,他们更喜欢先探索数据洞察,再定义规则。客户需要能够轻松地发现异常,让他们能够主动检测数据质量问题,从而做出自信的业务决策。
工作方式
注意
仅在 Amazon Glue ETL 中支持异常检测。基于 Data Catalog 的数据质量不支持此功能。
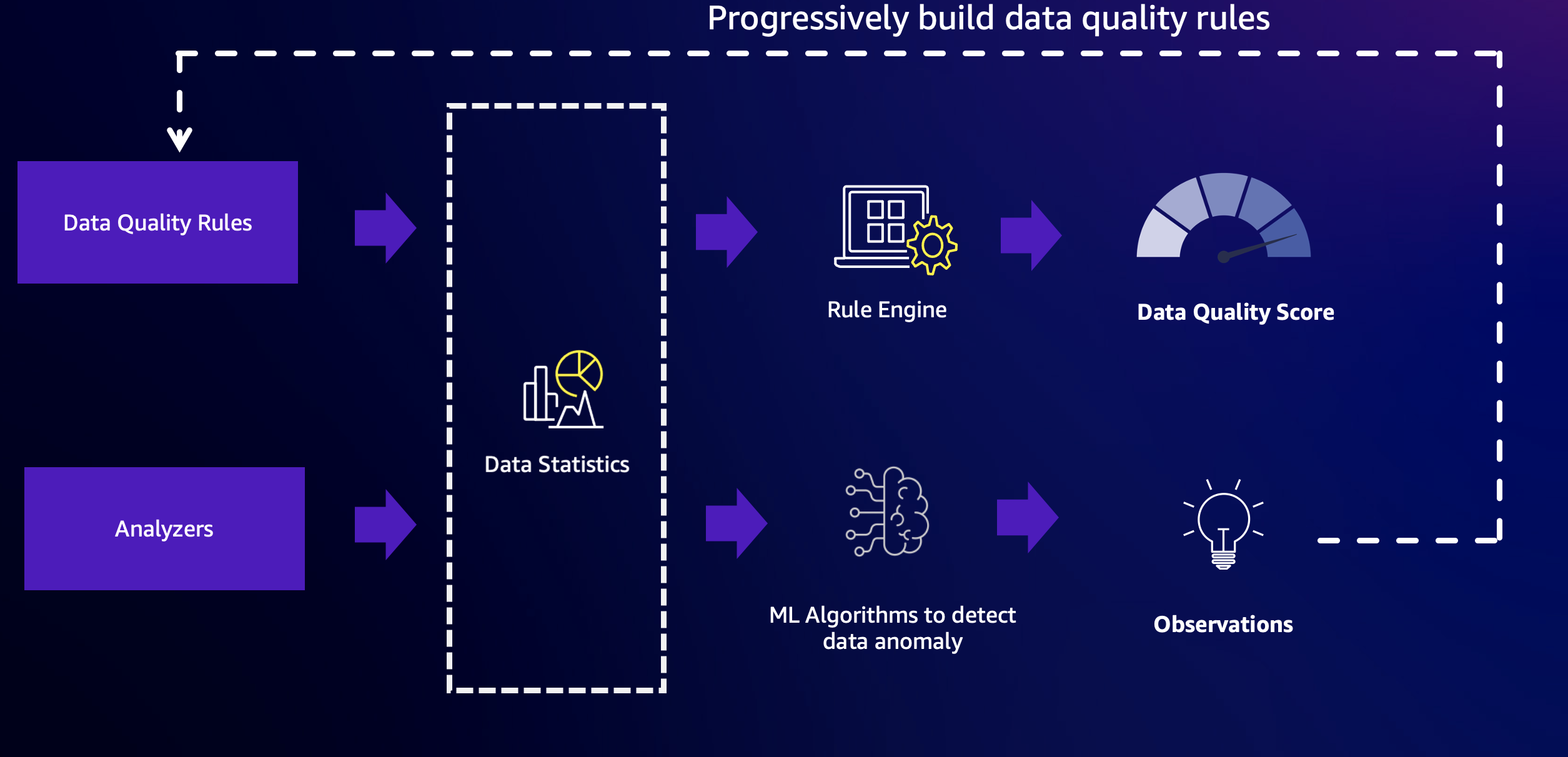
Amazon Glue 数据质量自动监测功能结合了基于规则的数据质量和异常检测功能,可提供高质量的数据。要使用此功能,您必须首先配置规则和分析器,然后启用异常检测。
规则
规则 – 规则以一种名为数据质量定义语言(DQDL)的开放性语言来表达对数据的期望。下面显示了一个规则示例。当“passenger_count”列中没有空值或 NULL 值时,此规则将成功:
Rules = [ IsComplete "passenger_count" ]
分析器
如果您知道关键列,但对数据的了解可能不足以编写特定规则,就可以使用分析器来监控这些列。分析器是一种无需定义明确的规则即可收集数据统计信息的方法。下面显示了一个配置分析器的示例:
Analyzers = [ AllStatistics "fare_amount", DistinctValuesCount "pulocationid", RowCount ]
在此示例中,对三个分析器进行了配置:
-
第一个分析器“AllStatistics "fare_amount"”,将捕获“fare_amount”字段的所有可用统计信息。
-
第二个分析器“DistinctValuesCount "pulocationid"”,将捕获“pulocationid”列中不同值的数量。
-
第三个分析器“RowCount”,将捕获数据集中的记录总数。
分析器是一种收集相关数据统计信息的简单方法,无需指定复杂规则即可进行收集。通过监控这些统计信息,您可以深入了解数据质量,并识别可能需要进一步调查或制定特定规则的潜在问题或异常。
数据统计信息
Amazon Glue 数据质量自动监测功能中的分析器和规则都会收集数据统计信息,也称为数据配置文件。这些统计信息可让您深入了解数据的特征和质量。收集的统计信息会在 Amazon Glue 服务中存储一段时间,因此您可以跟踪和分析数据配置文件中的变化。
通过调用合适的 API,您可以轻松检索这些统计信息并将其写入 Amazon S3,以便进行进一步分析或长期存储。此功能让您能够将数据分析集成到数据处理工作流程中,并将收集到的统计信息用于各种目的,例如数据质量监控、异常检测等。
通过将数据配置文件存储在 Amazon S3 中,您就可以充分利用 Amazon 对象存储服务的可扩展性、持久性以及成本效益。此外,您还可以利用其他 Amazon 服务或第三方工具来分析和可视化数据配置文件,从而更深入地了解数据质量,并就数据管理和治理做出明智的决策。
以下是一段时间内存储的数据统计信息的示例。
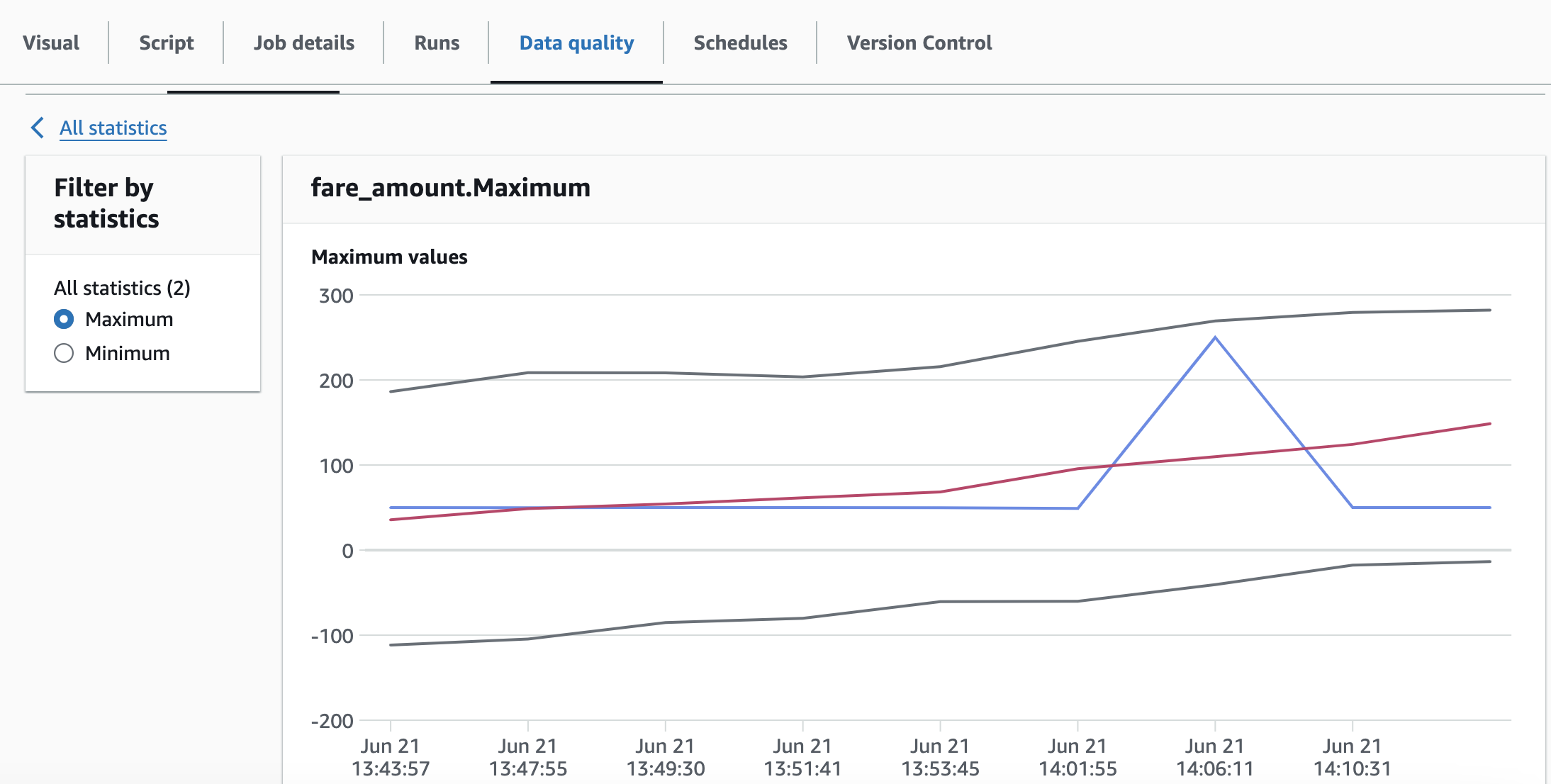
注意
即使您对相同的列同时使用规则和分析器,Amazon Glue 数据质量自动监测功能也只会收集一次统计信息,以此确保统计信息生成过程高效完成。
异常检测
Amazon Glue 数据质量自动监测功能至少需要三个数据点才能检测异常。该功能利用机器学习算法,从过去的趋势中学习,然后预测未来值。当实际值不在预测范围之内时,Amazon Glue 数据质量自动监测功能会创建异常观测值。该功能会提供实际值和趋势的可视化表示形式。下图中显示了四个值。
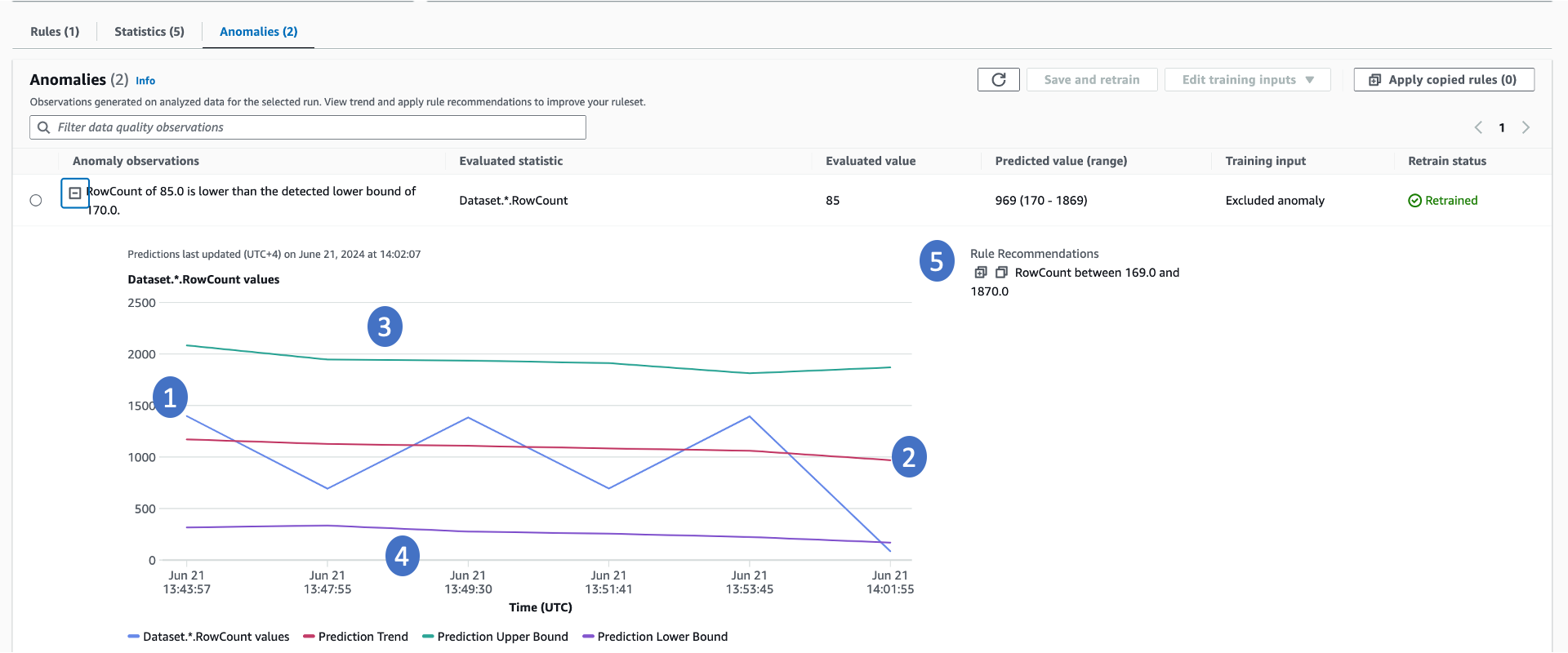
-
一段时间内的实际统计信息及其趋势。
-
从实际趋势中学习得出的预测趋势。这对于了解趋势走向很有用。
-
统计信息可能的上限。
-
统计信息可能的下限。
-
推荐的数据质量规则,这些规则可在未来检测到这些问题。
关于异常,有一些重要事项需要注意:
-
产生异常时,数据质量分数不会受到影响。
-
检测到异常时,后续运行会将其视为正常。除非明确排除该异常值,否则机器学习算法会将其视为输入。
重新训练
重新训练异常检测模型对于正确检测异常至关重要。检测到异常时,Amazon Glue 质量控制自动监测功能会将异常作为正常值包含在模型中。为确保异常检测能准确进行,通过确认或拒绝异常来提供反馈非常重要。AmazonGlue 数据质量自动监测功能在 Amazon Glue Studio 和 API 中都提供了向模型提供反馈的机制。要了解更多信息,请参阅有关设置 Amazon Glue ETL 管道中的异常检测的文档。
异常检测算法详细信息
-
异常检测算法会检查一段时间内的数据统计信息。该算法会考虑所有可用的数据点,同时忽略掉任何明确排除的统计信息。
-
这些数据统计信息存储在 Amazon Glue 服务中,您可以提供 Amazon KMS 密钥对其进行加密。有关如何提供 Amazon KMS 密钥来加密 Amazon Glue 数据质量自动监测功能的统计信息,请参阅“安全性”指南。
-
时间因素对于异常检测算法至关重要。Amazon Glue 数据质量自动监测功能会根据过去的值来确定上限和下限。在确定过程中,系统会充分考虑时间因素。对于相同的值,在一分钟间隔、一小时间隔或一日间隔内,限制将会有所不同。
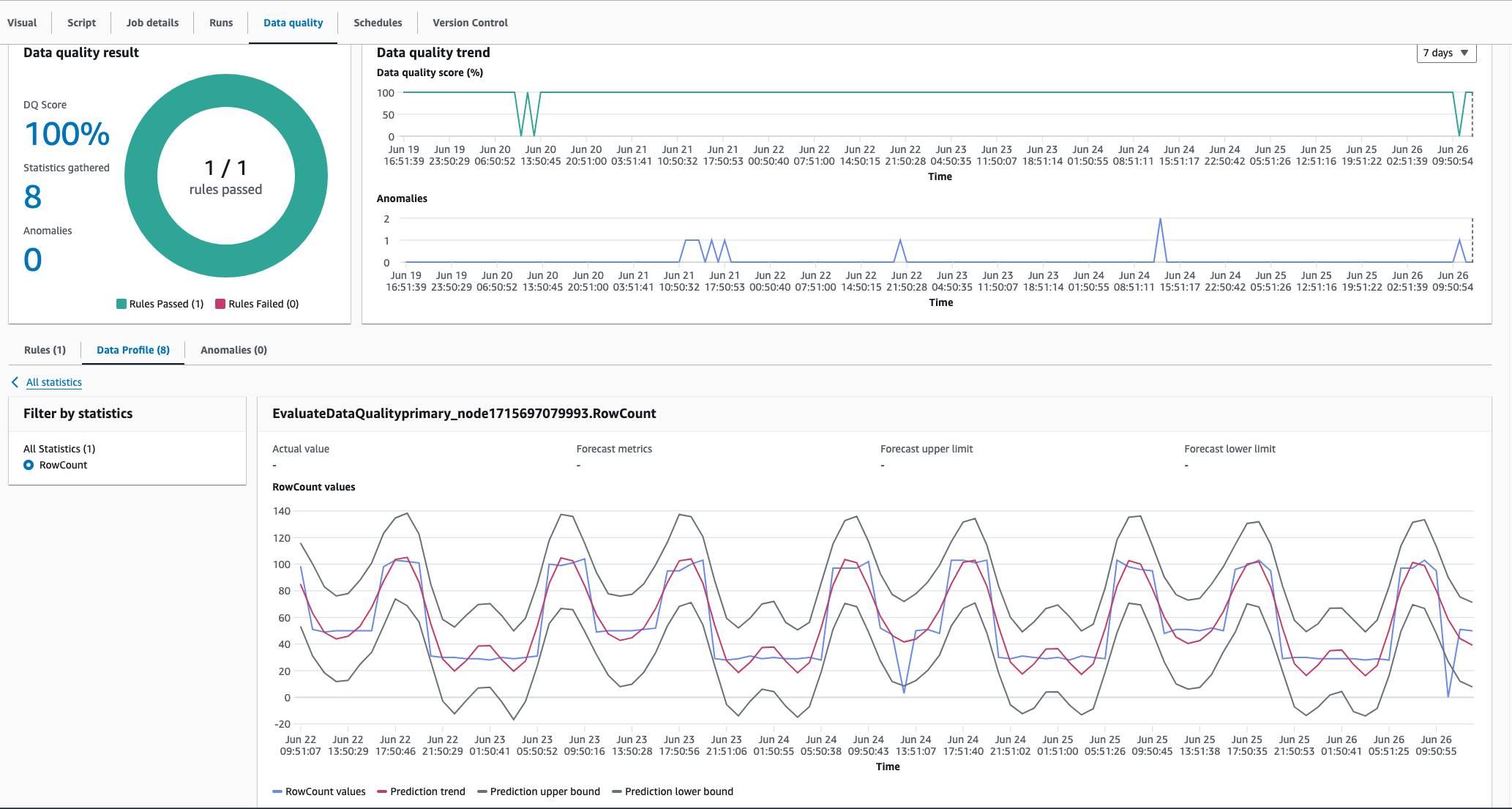
捕获季节性数据
Amazon Glue 数据质量自动监测功能的异常检测算法可以捕捉季节性模式。例如,该算法可以理解工作日模式与周末模式的不同。从以下示例就可以看出,在此示例中,Amazon Glue 数据质量自动监测功能可以检测出数据值中的季节性趋势。您无需执行任何特定操作即可启用此功能。随着时间的推移,Amazon Glue 数据质量自动监测功能会学习季节性趋势,并在这些模式中断时检测到异常。
成本
我们将根据检测异常所需的时间来向您收取费用。按照检测异常所需的时间,每个统计信息按 1 DPU 计费。有关详细示例,请参阅 Amazon Glue 定价
重要注意事项
存储统计信息不会产生任何费用。但是,每个账户的统计信息上限为 10 万条。这些统计信息最多可存储两年。