将 Apache Spark 程序迁移到 Amazon Glue
Apache Spark 是一个开源平台,用于在大型数据集上执行分布式计算工作负载。Amazon Glue 利用 Spark 的功能为 ETL 提供优化的体验。可以将 Spark 程序迁移到 Amazon Glue 以利用我们的功能。Amazon Glue 提供了与 Amazon EMR 上的 Apache Spark 相同的性能增强。
运行 Spark 代码
原生 Spark 代码可以在开箱即用的 Amazon Glue 环境中运行。脚本通常是通过迭代更改一段代码来开发的,这是一种适合交互式会话的工作流。但是,现有的代码更适合在 Amazon Glue 作业中运行,它允许您计划并持续获取每个脚本运行的日志和指标。可以通过控制台上传和编辑现有脚本。
-
获取脚本的源。在此示例中,您将使用来自 Apache Spark 存储库的示例脚本。二值化程序示例
-
在 Amazon Glue 控制台中,展开左侧导航窗格并选择 ETL > Jobs(作业)
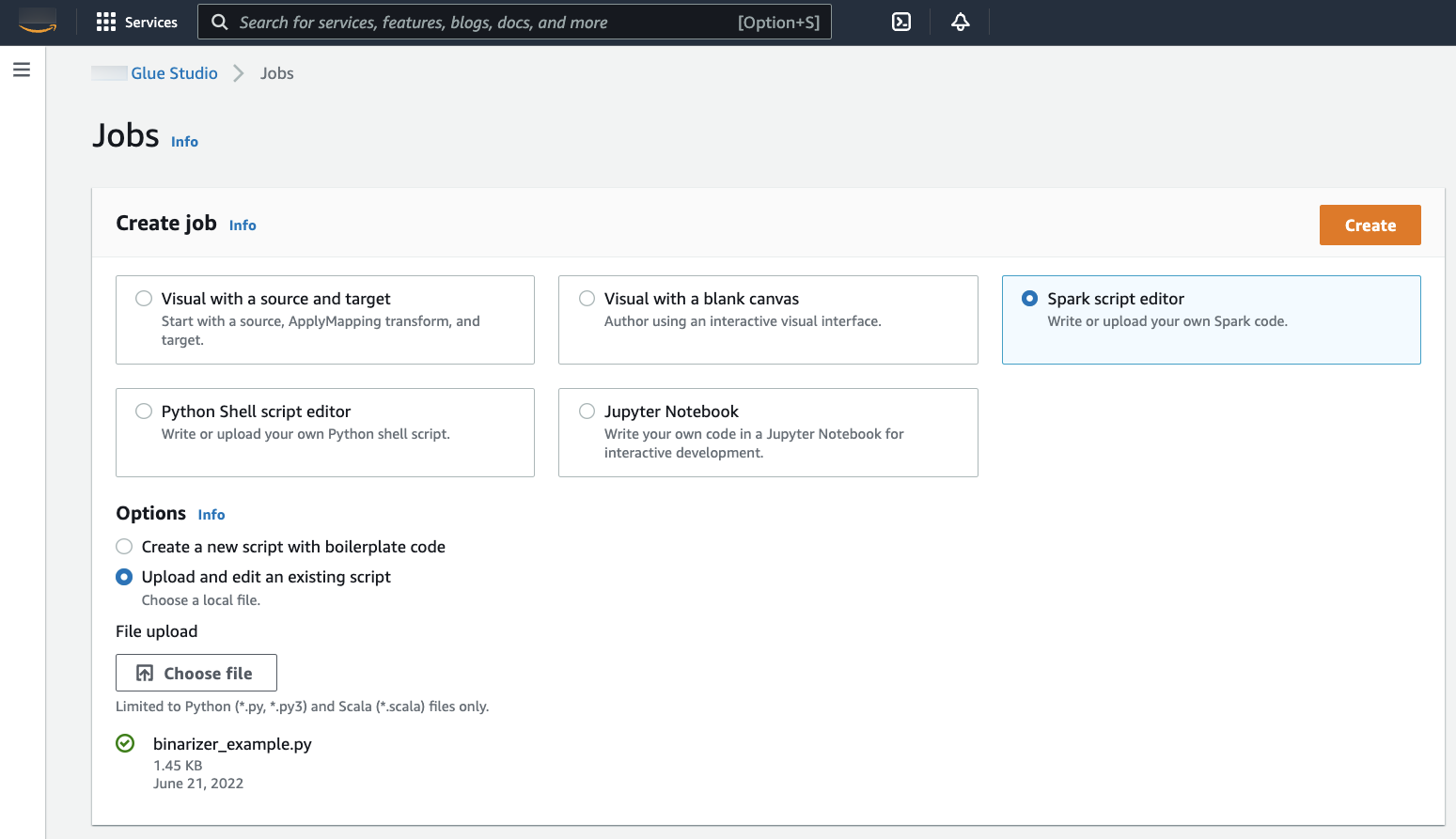
在 Create job(创建作业)面板中,选择 Spark script editor(Spark 脚本编辑器)。Options(选项)部分将显示。在 Options(选项)下,选择 Upload and edit an existing script(上传和编辑现有脚本)。
File upload(文件上传)部分将显示。在 File upload(文件上传)下,单击 Choose file(选择文件)。系统文件选择器将会出现。导航到保存
binarizer_example.py的位置,将其选中,然后确认您的选择。Create(创建)按钮将出现在 Create job(创建作业)面板的标题上。单击它。
-
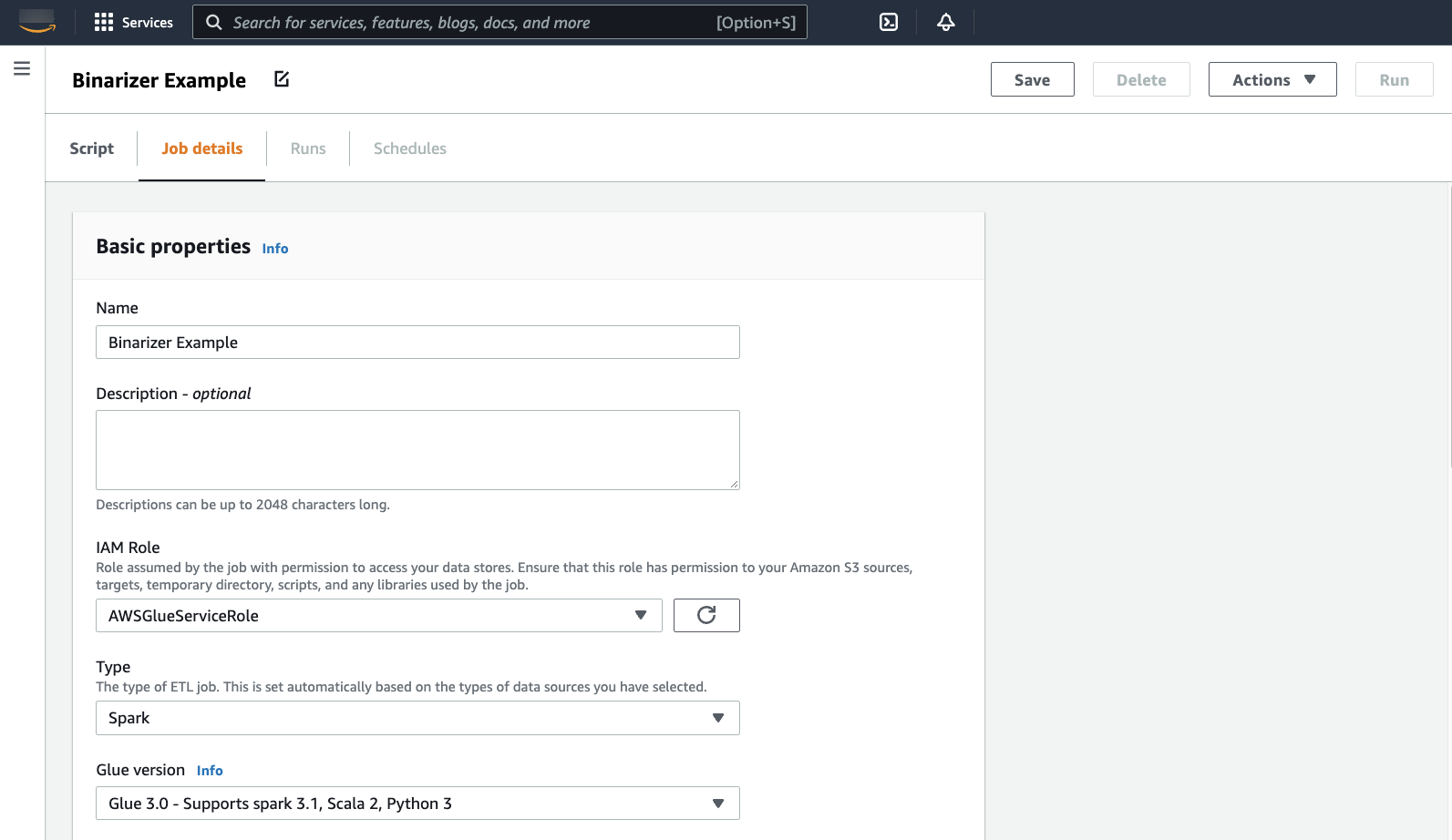
您的浏览器将导航到脚本编辑器。在标题上,单击 Job details(作业详细信息)选项卡。设置名称和 IAM 角色。有关 Amazon Glue IAM 角色的指导,请参阅 为 Amazon Glue 设置 IAM 权限。
可选 - 将 Requested number of workers(请求的工作线程数)设置为
2,Number of retries(重试次数)设置为1。这些选项在运行生产作业时很有价值,但关闭这些选项将简化您在测试功能时的体验。在标题栏中,单击 Save(保存),然后单击 Run(运行)
-
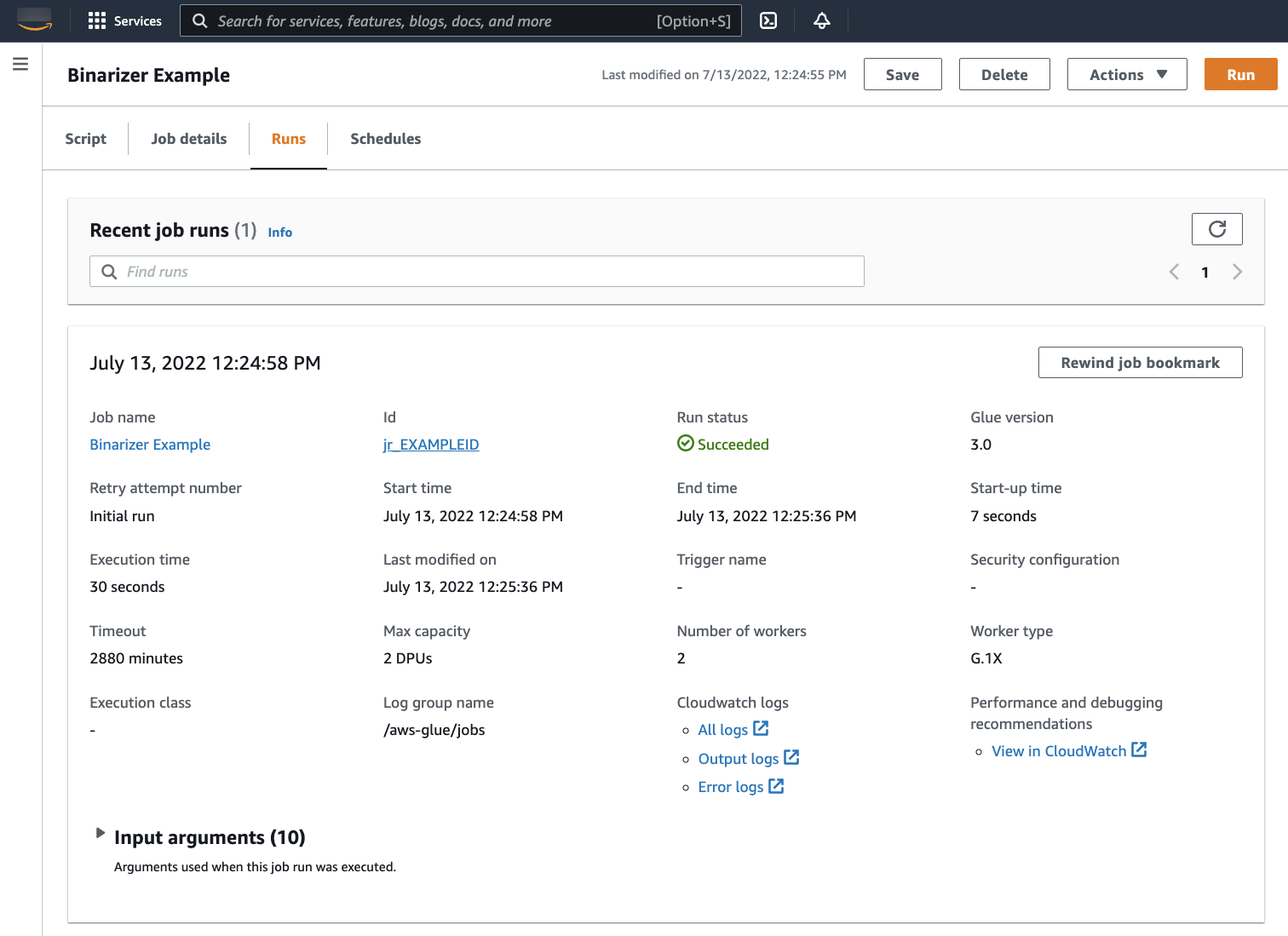
导航到 Runs(运行)选项卡。您将看到一个与您的作业运行相对应的面板。等待几分钟,页面将自动刷新以在 Run status(运行状态)下显示 Succeeded(成功)。
-
您需要检查输出,以确保 Spark 脚本按预期运行。此 Apache Spark 示例脚本应该会向输出流写入一个字符串。可以通过导航到面板中 Cloudwatch Logs 下的 Output logs(输出日志)找到成功的作业运行。请记下作业运行 ID,它是在 Id 标签下生成的以
jr_开头的 ID。这将打开 CloudWatch 控制台,设置为可视化默认 Amazon Glue 日志组
/aws-glue/jobs/output的内容,筛选为作业运行 ID 的日志流的内容。每个工作线程都将生成一个日志流,显示在 Log streams(日志流)。应该有一个工作线程运行了请求的代码。您需要打开所有日志流来找到正确的工作线程。找到合适的工作线程后,您应该会看到脚本的输出,如下图所示: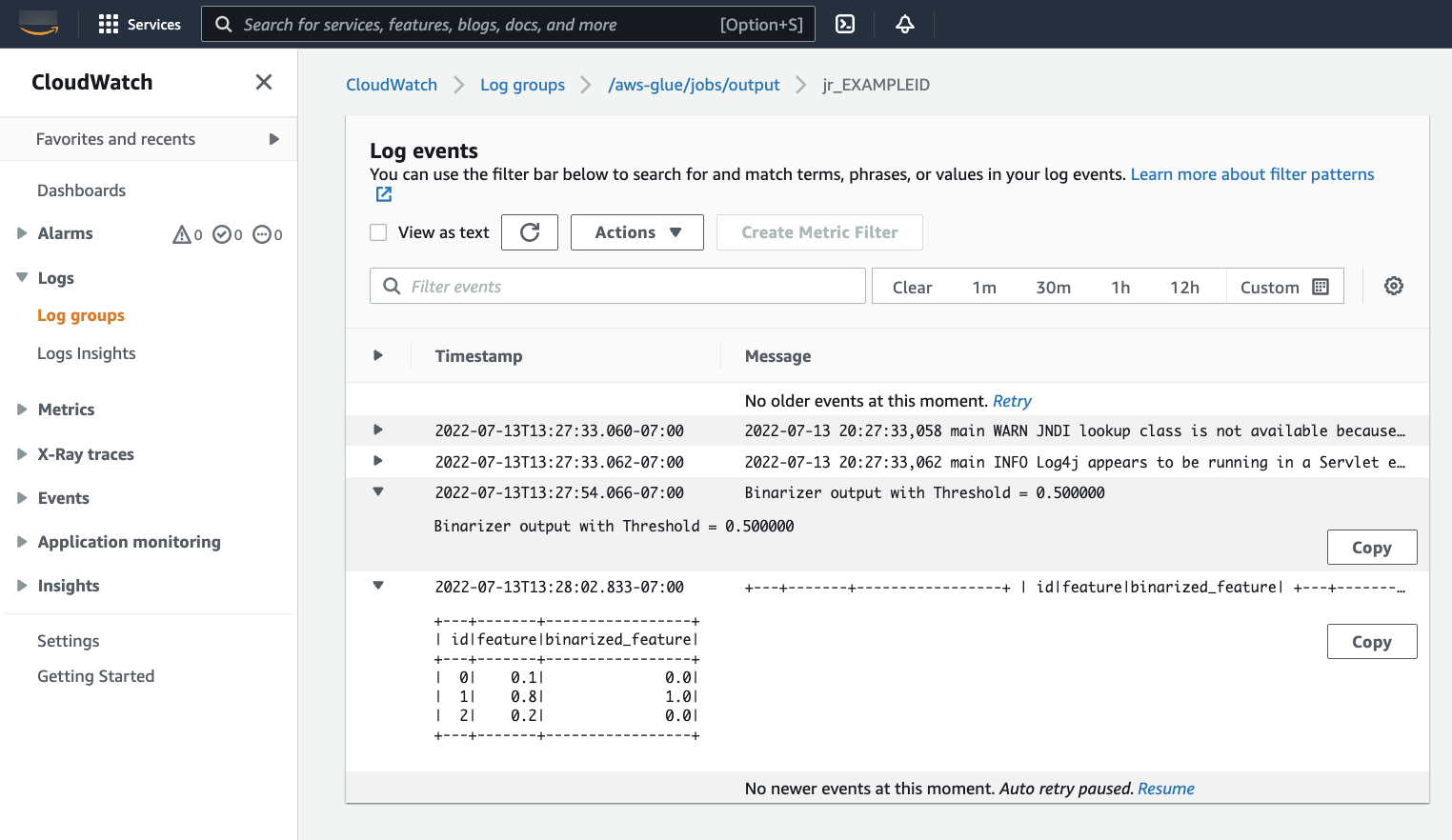
迁移 Spark 程序所需的常用过程
评估 Spark 版本支持
Amazon Glue 版本定义可用于 Amazon Glue 作业的 Apache Spark 和 Python 版本。您可以在 Amazon Glue 版本 找到我们的 Amazon Glue 版本及其支持的内容。您可能需要更新您的 Spark 程序,使其与较新版本的 Spark 兼容,才能访问某些 Amazon Glue 功能。
包括第三方库
许多现有的 Spark 程序在私有和公共构件上都有依赖关系。Amazon Glue 支持 Scala 作业的 JAR 样式依赖关系以及 Python 作业的 Wheel 和源纯 Python 依赖关系。
Python - 有关 Python 依赖关系的信息,请参阅 将 Python 库与 Amazon Glue 结合使用
常见的 Python 依赖项在 Amazon Glue 环境中提供,包括通常请求的 Pandas--additional-python-modules。有关作业参数的信息,请参阅 在 Amazon Glue 作业中使用作业参数。
您可以为其他 Python 依赖关系提供 --extra-py-files 作业参数。如果要从 Spark 程序迁移作业,则此参数是一个不错的选择,因为它在功能上等同于 PySpark 中的 --py-files 标志,并且受到相同的限制。有关 --extra-py-files 参数的更多信息,请参阅 包含具有 PySpark 原生功能的 Python 文件
对于新作业,您可以管理带 --additional-python-modules 作业参数的 Python 依赖关系。使用此参数可以获得更全面的依赖关系管理体验。此参数支持 Wheel 样式依赖项,包括具有与 Amazon Linux 2 兼容的原生代码绑定的依赖项。
Scala
您可以为其他 Scala 依赖关系提供 --extra-jars 作业参数。依赖关系必须托管在 Amazon S3 中,参数值应为逗号分隔的 Amazon S3 路径列表,且不含空格。您可能会发现,在托管和配置依赖关系之前,通过重新绑定依赖关系,可以更轻松地管理您的配置。Amazon GlueJAR 依赖关系包含 Java 字节码,它可以从任何 JVM 语言生成。您可以使用其他 JVM 语言(如 Java)来编写自定义依赖关系。
管理数据源凭证
现有的 Spark 程序可能带有复杂或自定义配置,以便从其数据源中提取数据。Amazon Glue 连接支持常见的数据源身份验证流程。有关 Amazon Glue 连接的更多信息,请参阅 连接到数据。
Amazon Glue 连接可通过两种主要方式帮助您将作业连接到各种类型的数据存储:通过方法调用我们的库和设置 Amazon Web Services 控制台中的 Additional network connection(其他网络连接)。也可以从作业中调用 Amazon SDK,以从连接中检索信息。
方法调用 - Amazon Glue 连接与 Amazon Glue 数据目录紧密集成,后者是一项服务,允许您整理有关数据集的信息以及可用来与反映该信息的 Amazon Glue 连接交互的方法。如果您有想要重用的现有身份验证配置,对于 JDBC 连接,您可以通过 GlueContext 上的 extract_jdbc_conf 方法访问您的 Amazon Glue 连接配置。有关更多信息,请参阅 extract_jdbc_conf
控制台配置 - Amazon Glue 作业使用关联 Amazon Glue 连接来配置与 Amazon VPC 子网的连接。如果您直接管理自己的安全材料,则可能需要在 Amazon Web Services 控制台上提供 NETWORK 类型的其他网络连接来配置路由。有关 Amazon Glue 连接 API 的更多信息,请参阅 连接 API
如果您的 Spark 程序具有自定义或不常见的身份验证流程,则可能需要亲自操作管理安全材料。如果 Amazon Glue 连接似乎不太合适,您可以在 Secrets Manager 中安全地托管安全材料,然后通过作业中提供的 boto3 或 Amazon SDK 来访问。
配置 Apache Spark
复杂的迁移通常会改变 Spark 配置以适应其工作负载。现代版本的 Apache Spark 允许使用 SparkSession 设置运行时配置。Amazon Glue为 3.0+ 任务提供了 SparkSession,可以对其进行修改以设置运行时配置。Apache Spark 配置
设置自定义配置
迁移的 Spark 程序可能设计为采用自定义配置。Amazon Glue 允许通过作业参数在作业和作业运行级别设置配置。有关作业参数的信息,请参阅 在 Amazon Glue 作业中使用作业参数。您可以通过我们的库访问作业上下文中的作业参数。Amazon Glue 提供了一个实用程序函数,用于在作业上设置的参数和在作业运行上设置的参数之间提供一致的视图。请参阅 Python 中的 使用 getResolvedOptions 访问参数 和 Scala 中的 Amazon Glue Scala GlueArgParser API。
迁移 Java 代码
如 包括第三方库 中解释,您的依赖关系可以包含由 JVM 语言(如 Java 或 Scala)生成的类。您的依赖关系可以包含 main 方法。您可以在依赖关系中使用 main 方法作为 Amazon Glue Scala 作业的入口点。这允许您用 Java 编写 main 方法,或者重用您自己的库标准中打包的 main 方法。
要使用依赖关系中的 main 方法,请执行以下操作:清除提供默认 GlueApp 对象的编辑窗格的内容。在依赖关系中将类的完全限定名称作为带键 --class 的作业参数提供。然后您应该能够触发作业运行。
您无法配置参数 Amazon Glue 传递到 main 方法的顺序或结构。如果您的现有代码需要读取 Amazon Glue 中的配置集,这可能会导致与之前的代码不兼容。如果您使用 getResolvedOptions,也不会有调用此方法的好地方。请考虑直接利用 Amazon Glue 生成的主方法来调用依赖关系。下方的 Amazon Glue ETL 脚本显示了此操作的示例。
import com.amazonaws.services.glue.util.GlueArgParser object GlueApp { def main(sysArgs: Array[String]) { val args = GlueArgParser.getResolvedOptions(sysArgs, Seq("JOB_NAME").toArray) // Invoke static method from JAR. Pass some sample arguments as a String[], one defined inline and one taken from the job arguments, using getResolvedOptions com.mycompany.myproject.MyClass.myStaticPublicMethod(Array("string parameter1", args("JOB_NAME"))) // Alternatively, invoke a non-static public method. (new com.mycompany.myproject.MyClass).someMethod() } }