Amazon Glue 流式处理自动扩缩
Amazon Glue 流式传输 ETL 作业会持续消耗来自流式处理源的数据、清理和转换动态数据,并在使其可用于分析。通过监控作业运行的每个阶段,Amazon Glue 自动扩缩可以在工作线程空闲时将其关闭,或者在有可能进行额外并行处理时添加工作线程。
以下部分介绍了有关 Amazon Glue 流式处理自动扩缩的信息
在 Amazon Glue Studio 中启用自动扩缩
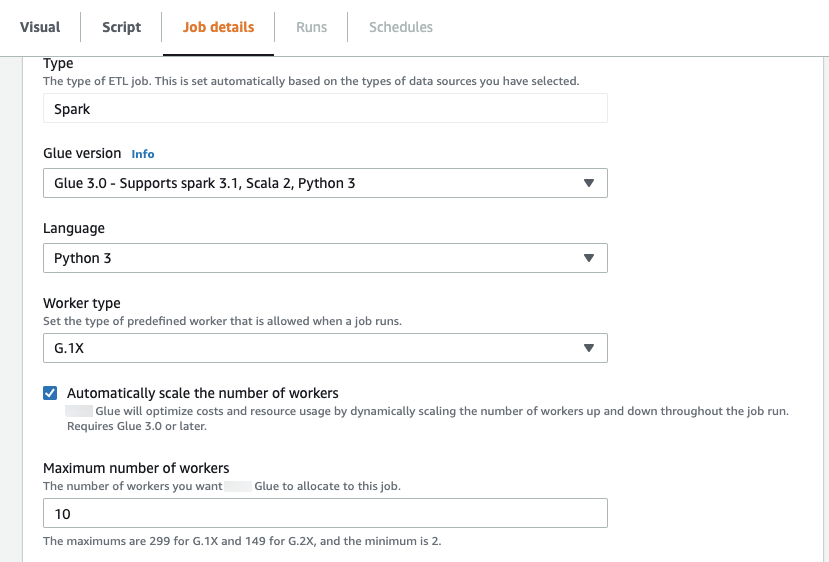
在 Amazon Glue Studio 中的 Job details(任务详细信息)选项卡上,将类型选择为 Spark 或 Spark Streaming,并将 Glue version(Glue 版本)选择为 Glue 3.0 或 Glue 4.0。随后将在 Worker type(工件类型)下方出现一个复选框。
-
选择 Automatically scale the number of workers(自动扩展工件数量)选项。
-
设置 Maximum number of workers(最大工件数量)以定义可提供给任务运行的最大工件数量。
使用 Amazon CLI 或开发工具包启用自动扩缩
要通过 Amazon CLI 为任务运行启用自动扩缩,使用以下配置运行 start-job-run:
{ "JobName": "<your job name>", "Arguments": { "--enable-auto-scaling": "true" }, "WorkerType": "G.2X", // G.1X, G.2X, G.4X, G.8X, G.12X, G.16X, R.1X, R.2X, R.4X, and R.8X are supported for Auto Scaling Jobs "NumberOfWorkers": 20, // represents Maximum number of workers ...other job run configurations... }
在 ETL 任务运行完成后,您还可以调用 get-job-run 以检查 DPU-seconds 内任务运行的实际资源使用情况。请注意:为 Amazon Glue 3.0 或更高版本上运行的批处理任务启用自动扩缩时,才会显示新字段 DPUSeconds。流式处理任务不支持此字段。
$ aws glue get-job-run --job-name your-job-name --run-id jr_xx --endpoint https://glue.us-east-1.amazonaws.com --region us-east-1 { "JobRun": { ... "GlueVersion": "3.0", "DPUSeconds": 386.0 } }
您还可以使用具有相同配置的 Amazon Glue 开发工具包配置启用自动扩缩的任务运行。
工作原理
跨微批次扩缩
以下示例描述了自动扩缩的工作原理。
-
您有一个 Amazon Glue 作业,该作业起初为 50 个 DPU。
-
自动扩缩已启用。
在本示例中,Amazon Glue 将查看几个微批次的“batchProcessingTimeInMs”指标,并确定您的作业是否会在设定的窗口大小内完成。如果您的作业完成得较早,根据完成的速度,Amazon Glue 可能会缩减。此指标使用“numberAllExecutors”进行绘制,并可在 Amazon CloudWatch 中进行监控,以了解自动扩缩是如何工作的。
只有在每个微批次完成后,执行程序的数量才会呈指数级扩缩。从 Amazon CloudWatch 监控日志中可以看到,Amazon Glue 查看了所需的执行程序数量(橙色线),并自动根据该数量扩缩了执行程序(蓝色线)。
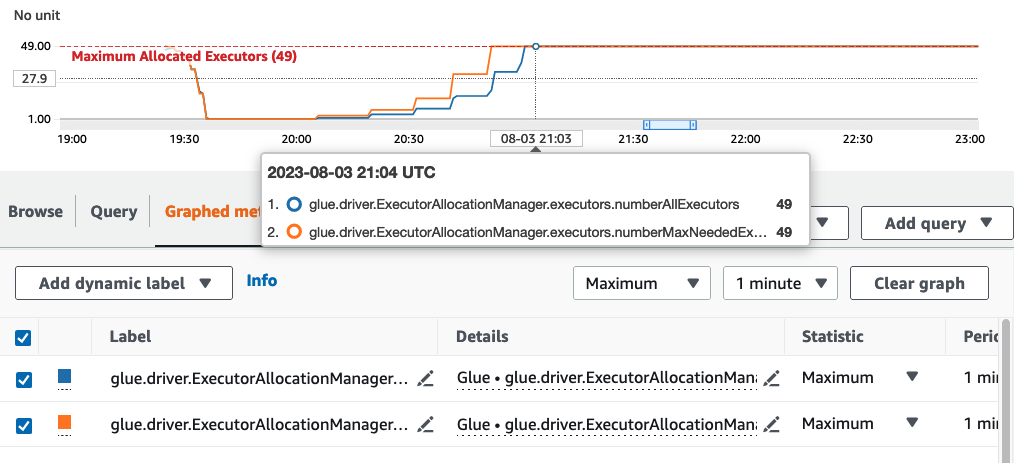
一旦 Amazon Glue 缩减了执行程序的数量并观察到数据量增加,从而增加了微批次处理时间,Amazon Glue 就会扩展到 50 个 DPU,即指定的上限。
微批次内扩缩
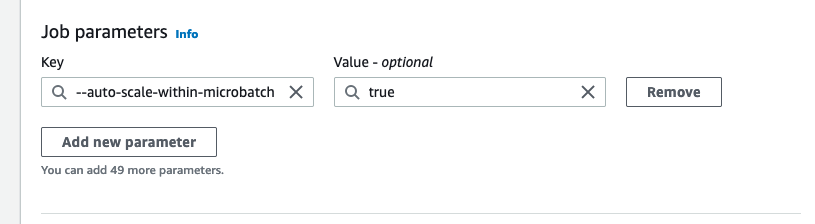
在上面的示例中,系统会监控几个已完成的微批次,以决定是扩大还是缩小规模。如果窗口较长,则需要在微批次内更快地响应,而不是等待几个微批次。对于此类情况,您可以使用一个额外配置 --auto-scaIe-within-microbatch 并将其设置为 true。您可以将其添加到 Amazon Glue Studio 的 Amazon Glue 作业属性中,如下所示。