Amazon Glue 流式传输的维护时段
Amazon Glue 定期执行维护活动。在这些维护时段内,Amazon Glue 需要重新启动您的流式传输任务。您可以通过指定维护时段来控制何时重启作业。在本节中,我们将概述可以在何处设置维护时段以及您应考虑的特定行为。
设置维护时段
您可以使用 Amazon Glue Studio 或 API 设置维护时段。
在 Amazon Glue Studio 中设置维护时段
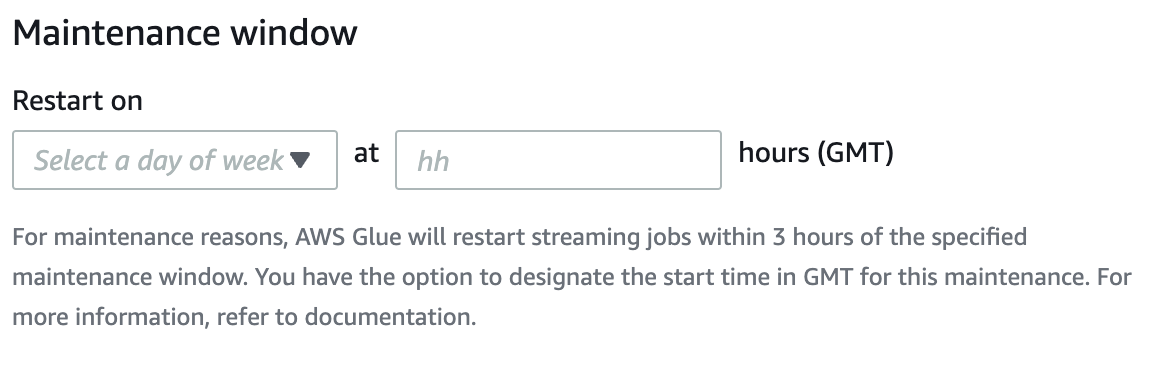
您可以在 Amazon Glue 流式传输作业的作业详细信息页面中指定维护时段。您可以指定以 GMT 计的日期和时间。Amazon Glue 将在指定的时间窗口内重启您的作业。
在 API 中设置维护时段
您还可以在“创建作业 API”中设置维护时段。以下是通过 API 配置维护时段的示例。
aws glue create-job —name jobName —role roleArnForTheJob —command Name=gluestreaming,ScriptLocation=s3-path-to-the-script --maintenance-window="Sun:10"
示例命令如下:
aws glue create-job —name testMaintenance —role arn:aws:iam::012345678901:role/Glue_DefaultRole —command Name=gluestreaming,ScriptLocation=s3://glue-example-test/example.py —maintenance-window="Sun:10
维护时段行为
Amazon Glue 会依次执行一系列步骤来决定何时重启作业:
启动新的流式传输作业时,Amazon Glue 会先检查是否存在与该作业运行相关联的超时设置。超时设置允许您配置作业的结束时间。如果超时时间少于 7 天,则作业将不会重启。
如果超时时间超过 7 天,则 Amazon Glue 会检查是否为作业配置了维护时段。如果是,则会选择该时段,并将该时段分配给作业运行。Amazon Glue 将在指定维护时段开始后的 3 小时内重启作业。例如,如果您将维护时段设置为 GMT 时间星期一上午 10:00,则您的任务将在 GMT 时间上午 10:00 至下午 1:00 之间重新启动。
如果未配置维护时段,则 Amazon Glue 会自动将重启时间设置为作业运行启动时间后 7 天。例如,如果您在 GMT 时间 2024 年 7 月 1 日午夜 12:00 启动作业,但未指定维护时段,则您的作业将设置为在 GMT 时间 2024 年 7 月 8 日午夜 12:00 重启。
注意
如果您已在运行流式传输作业,那么从 2024 年 7 月 1 日起,此更改将对您产生影响。在 6 月 30 日之前,您可以配置维护时段。7 月 1 日之后,根据本文档,您启动的所有流式传输作业都将重启。如果您需要任何其他支持,可以联系 Amazon 支持人员。
有时,Amazon Glue 可能无法重启作业,尤其是在正在进行的微批处理未被处理的情况下。在这些情况下,作业不会中断。在这些情况下,Amazon Glue 将在 14 天后重启作业,并且在这种情况下,不会遵守维护时段。
作业监控
您可以在 Amazon Glue Studio 监控页面中监控作业。
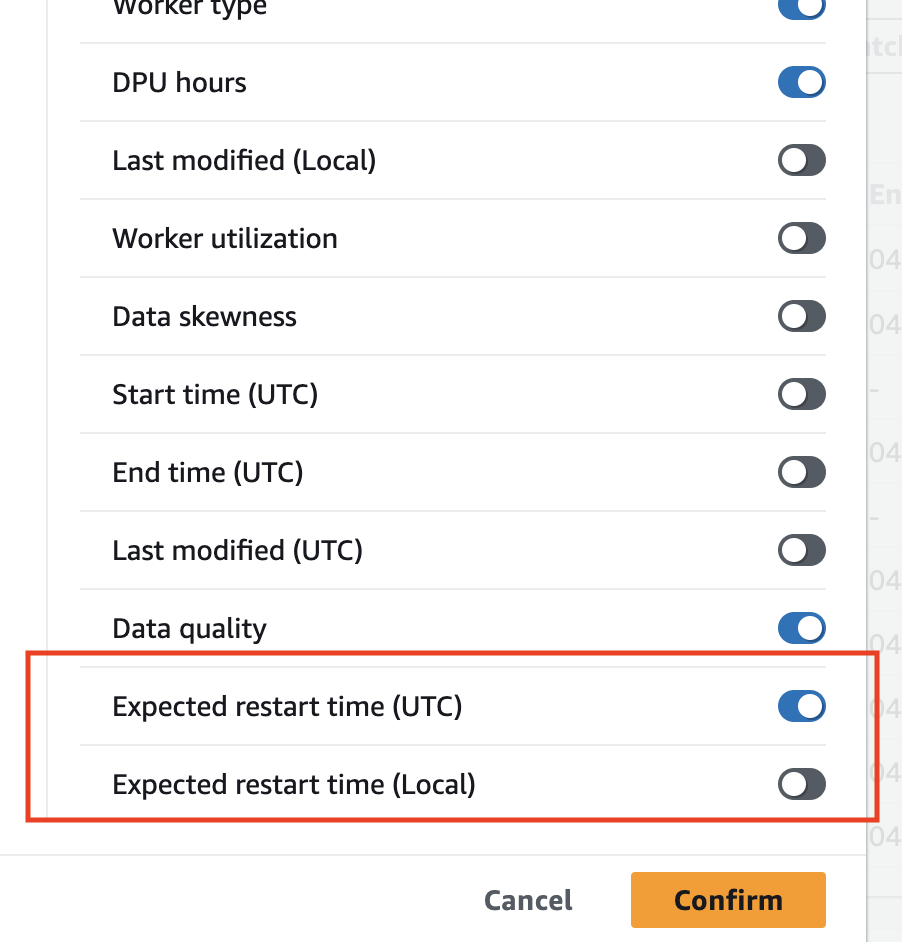
要查看流式传输作业的预计下次重启时间,请在监控页面的“作业运行”表中显示相应列。
单击该表右上角的齿轮图标。

向下滚动,然后启用预计重启时间列。您可以选择 UTC 或本地时间选项。
然后,您可以查看表中的列。

原始作业的状态将为“已过期”,而新作业实例的状态将为“正在运行”。重启的新作业运行将有一个作业运行 ID,由初始作业运行 ID 加上代表重启计数的前缀“restart_”串联而成。例如,如果初始作业运行 ID 为 jr_1234,则第一次重启后的作业运行的 ID 为 jr1234_restart_1。第二次重启的 ID 将为 jr1234_restart_2,依此类推。
您的重试尝试不会因为重启而受到影响。如果运行失败并且由于自动重试而开始了新的运行,则重启计数器将再次从 1 开始。例如,如果运行在 jr_1234_attempt_3_restart_5 时失败,则自动重试将开始新的运行,ID 为 jr_id1_attempt_4;当此尝试在 7 天后重启时,新的运行 ID 将为 jr_id1_attempt_4_restart_1。
数据丢失处理
在维护重启期间,Amazon Glue 流式传输会遵循一套流程,以确保数据完整性以及上一次作业运行与重启后作业运行之间的一致性。请注意,Amazon Glue 不能保证两次作业重启之间的数据完整性和一致性,我们建议在处理流式传输作业中的重复数据时考虑架构问题。
检测维护重启条件:Amazon Glue 流式传输可监控指示何时应触发维护重启的条件,例如 7 天后达到维护时段或 14 天后需要硬重启的情况。
调用优雅终止:当满足维护重启条件时,Amazon Glue 流式传输会为当前正在运行的作业启动一个优雅的终止流程。此流程涉及到以下步骤:
停止摄取新数据:流式传输作业停止使用来自输入源(例如 Kafka 主题、Kinesis 流或文件)的新数据。
处理待处理数据:作业继续处理其内部缓冲区或队列中已存在的任何数据。
提交偏移量和检查点:作业将最新的偏移量或检查点提交到外部系统(例如 Kafka、Kinesis 或 Amazon S3),以确保重启后的作业可以从上一个作业中断的地方继续运行。
重启作业:优雅终止流程完成后,Amazon Glue 流式传输将使用保留的状态和检查点重启作业。重启的作业从上次提交的偏移量或检查点开始处理,确保没有数据丢失或重复。
恢复数据处理:重启的作业将从上一个作业中断的地方恢复数据处理。它会继续从输入源提取新数据(从上次提交的偏移量或检查点开始),并根据定义的 ETL 逻辑处理数据。