在 Amazon Glue Studio 中使用 Hudi 框架
创建或编辑作业时,Amazon Glue Studio 会根据您使用的 Amazon Glue 版本自动为您添加相应的 Hudi 库。有关更多信息,请参阅在 Amazon Glue 中使用 Hudi 框架。
在 Data Catalog 数据来源中使用 Apache Hudi 框架
要为作业添加 Hudi 数据来源格式,请执行以下操作:
-
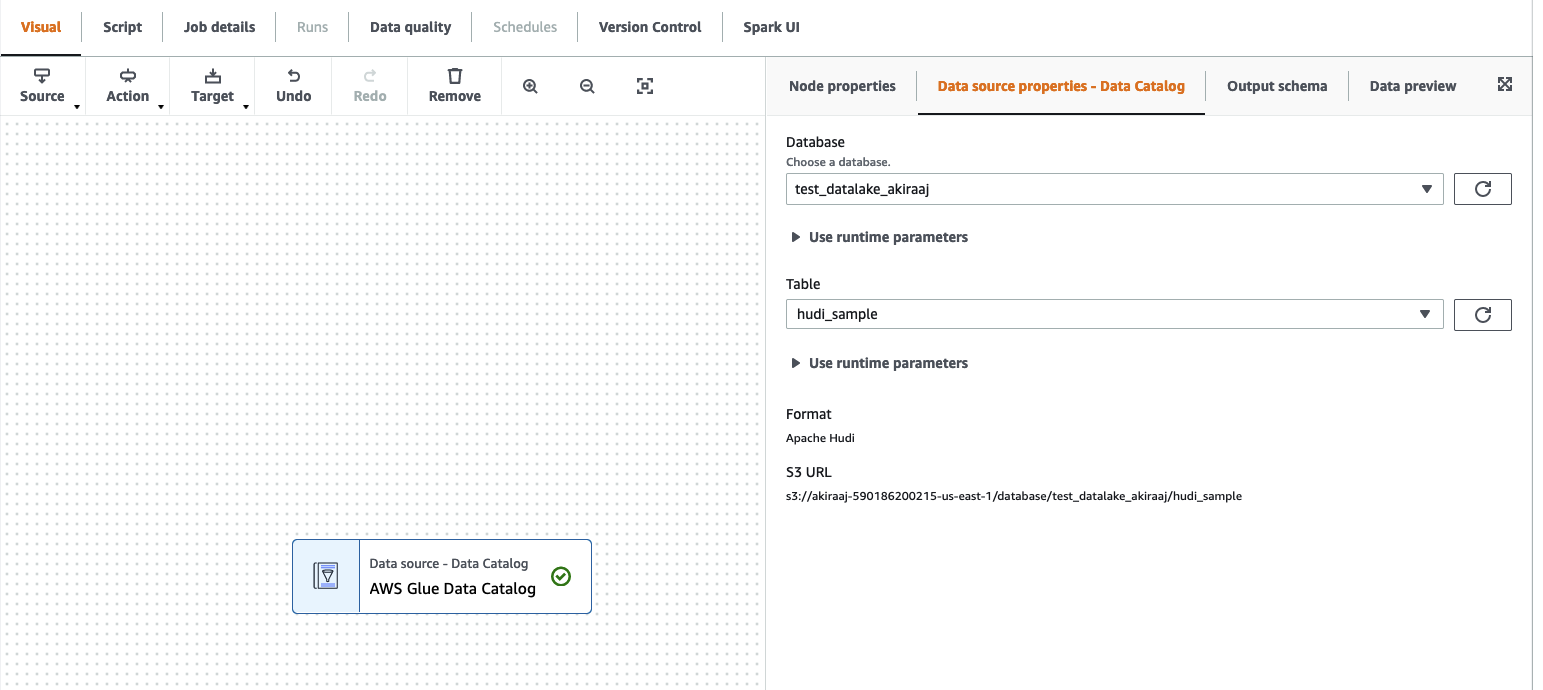
从“来源”菜单中选择“Amazon Glue Studio Data Catalog”。
-
在数据来源属性选项卡中,选择数据库和表。
-
Amazon Glue Studio 将格式类型显示为 Apache Hudi 和 Amazon S3 URL。
在 Amazon S3 数据来源中使用 Hudi 框架
-
从“来源”菜单中选择 Amazon S3。
-
如果您选择 Data Catalog 表作为 Amazon S3 来源类型,请选择数据库和表。
-
Amazon Glue Studio 显示格式为 Apache Hudi 和 Amazon S3 URL。
-
如果您选择 Amazon S3 位置作为 Amazon S3 来源类型,请通过单击浏览 Amazon S3 选择 Amazon S3 URL。
-
在数据格式中,选择“Apache Hudi”。
注意
如果 Amazon Glue Studio 无法从您选择的 Amazon S3 文件夹或文件推断出架构,请选择其他选项来选择新的文件夹或文件。
在其他选项中,从架构推断下的以下选项中进行选择:
-
让 Amazon Glue Studio 自动选择示例文件:Amazon Glue Studio 将在 Amazon S3 位置选择一个示例文件,以便推断出架构。在自动取样文件字段中,您可以查看自动选择的文件。
-
从 Amazon S3 中选择示例文件:单击浏览 Amazon S3,选择要使用的 Amazon S3 文件。
-
-
单击推断架构。然后可以通过单击输出架构选项卡来查看输出架构。
-
选择其他选项以输入键值对。

在数据目标中使用 Apache Hudi 框架
在 Data Catalog 数据目标中使用 Apache Hudi 框架
-
从目标菜单中选择“Amazon Glue Studio Data Catalog”。
-
在数据来源属性选项卡中,选择数据库和表。
-
Amazon Glue Studio 将格式类型显示为 Apache Hudi 和 Amazon S3 URL。
在 Amazon S3 数据目标中使用 Apache Hudi 框架
输入值或从可用选项中进行选择以配置 Apache Hudi 格式。有关 Apache Hudi 的更多信息,请参阅 Apache Hudi 文档
-
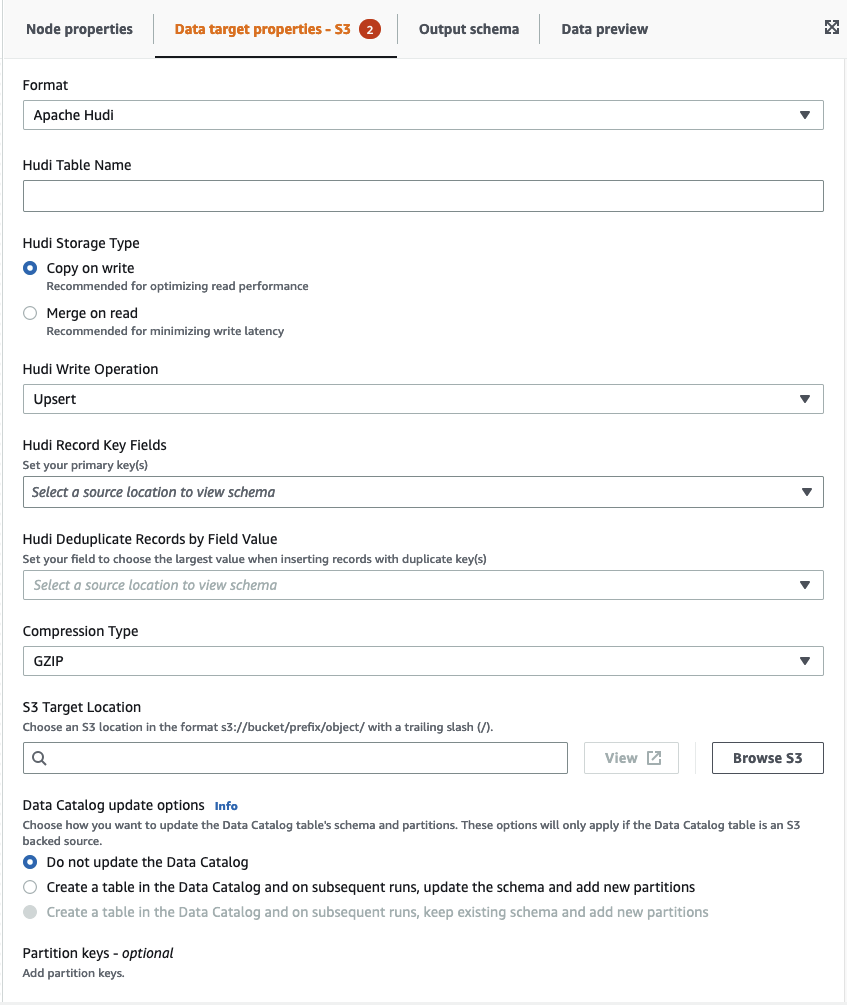
Hudi 表名:Hudi 表的名字。
-
Hudi 存储类型:从两个选项中选择:
-
写入时复制:可优化读取性能的推荐选项。这是默认 Hudi 存储类型。每次更新都会在写入时创建文件的新版本。
-
读取时合并:可将写入延迟降至最低的推荐选项。更新记录到基于行的增量文件中,并根据需要进行压缩以创建新版本的列式文件。
-
-
Hudi 写入操作:从以下选项中进行选择:
-
更新插入:默认操作,操作时首先通过查找索引将输入记录标记为插入或更新。在您更新现有数据时推荐选择。
-
插入:插入记录,但不检查现有记录,并可能导致重复。
-
批量插入:插入记录,建议用于大量数据。
-
-
Hudi 记录键字段:使用搜索栏搜索并选择主记录键。Hudi 中的记录由主键标识,主键由记录键和记录所属的分区路径组成。
-
Hudi 预合并字段:实际写入之前在预合并中使用的字段。如果两个记录具有相同的键值,Amazon Glue Studio 会为预合并字段选择值最大的记录。设置增量值(例如 updated_at)所属的字段。
-
压缩类型:选择一种压缩类型选项:未压缩、GZIP、LZO 或 Snappy。
-
Amazon S3 目标位置:通过单击浏览 S3 来选择 Amazon S3 目标位置。
-
Data Catalog 更新选项:从以下选项中进行选择:
-
Do not update the Data Catalog (请勿更新数据目录):(默认)如果您不希望任务更新数据目录(即使架构更改或添加了新分区),请选择此选项。
-
在 Data Catalog 中创建表并在后续运行时更新架构并添加新分区:如果选择此选项,作业将在第一次作业运行时在 Data Catalog 中创建表。在后续任务运行时,如果架构发生更改或添加了新分区,任务将更新数据目录表。
您还必须从数据目录中选择数据库并输入表名。
-
Create a table in the Data Catalog and on subsequent runs, keep existing schema and add new partitions (在数据目录中创建表,并在后续运行时保持现有架构并添加新分区):如果选择此选项,任务将在第一次任务运行时创建数据目录中的表。在后续任务运行时,任务只更新数据目录表以添加新分区。
您还必须从数据目录中选择数据库并输入表名。
-
-
Partition keys (分区键):选择要在输出中用作分区键的列。要添加更多分区键,请选择 Add a partition key (添加分区键)。
-
其他选项:根据需要输入键值对。
通过 Amazon Glue Studio 生成代码
保存作业时,如果检测到 Hudi 来源或目标,则会将以下作业参数添加到作业中:
-
--datalake-formats:在可视化作业中检测到的数据湖格式的不同列表(可以直接选择“格式”,或间接选择由数据湖支持的目录表)。 -
--conf:根据--datalake-formats的值生成。例如,如果--datalake-formats的值为 'hudi',则 Amazon Glue 为此参数生成的值为spark.serializer=org.apache.spark.serializer.KryoSerializer —conf spark.sql.hive.convertMetastoreParquet=false。
覆盖 Amazon Glue 提供的库
要使用 Amazon Glue 不支持的 Hudi 版本,可以指定自己的 Hudi 库 JAR 文件。要使用自己的 JAR 文件,请执行以下操作:
-
使用
--extra-jars作业参数。例如'--extra-jars': 's3pathtojarfile.jar'。有关更多信息,请参阅 Amazon Glue 作业参数。 -
请勿包含
hudi作为--datalake-formats作业参数的值。输入空白字符串作为值可确保 Amazon Glue 不会自动为您提供任何数据湖库。有关更多信息,请参阅在 Amazon Glue 中使用 Hudi 框架。