教程:使用 Amazon Glue 创建机器学习转换
本教程指导您完成使用 Amazon Glue 创建和管理机器学习 (ML) 转换的操作。在使用本教程之前,您应熟悉如何使用 Amazon Glue 控制台添加爬网程序和作业以及编辑脚本。您还应熟悉如何在 Amazon Simple Storage Service(Amazon S3)控制台上查找和下载文件。
在本示例中,您将创建一个 FindMatches 转换以查找匹配的记录,指导它如何标识匹配和不匹配的记录,并在 Amazon Glue 作业中使用它。Amazon Glue 任务会编写一个带有名为 match_id 的附加列的新 Amazon S3 文件。
本教程使用的源数据是一个名为 dblp_acm_records.csv 的文件。此文件是可从原始 DBLP ACM 数据集dblp_acm_records.csv 文件是一个 UTF-8 格式的逗号分隔值 (CSV) 文件,不带字节顺序标记 (BOM)。
另一个文件 dblp_acm_labels.csv 是示例标签文件,它包含在教程中用于指导转换的匹配记录和不匹配记录。
主题
步骤 1:爬取源数据
首先,对源 Amazon S3 CSV 文件进行爬网以在数据目录中创建相应的元数据表。
重要
要指示爬网程序仅为 CSV 文件创建表,请将 CSV 元数据存储在与其他文件不同的 Amazon S3 文件夹中。
登录 Amazon Web Services 管理控制台,然后打开 Amazon Glue 控制台,网址为:https://console.aws.amazon.com/glue/
。 -
在导航窗格中,选择 Crawlers (爬网程序)、Add crawler (添加爬网程序)。
-
按照向导使用数据库
demo-db-dblp-acm的输出创建并运行名为demo-crawl-dblp-acm的爬网程序。在运行向导时,将创建数据库demo-db-dblp-acm(如果该数据库不存在)。选择 Amazon S3 包含路径以在当前 Amazon 区域中对数据进行采样。例如,对于us-east-1,源文件的 Amazon S3 包含路径为s3://ml-transforms-public-datasets-us-east-1/dblp-acm/records/dblp_acm_records.csv。如果成功,爬网程序会创建具有以下列的
dblp_acm_records_csv表:ID、标题、作者、地点、年份和源。
步骤 2:添加机器学习转换
接下来,添加基于由名为 demo-crawl-dblp-acm 的爬网程序创建的数据源表的架构的机器学习转换。
-
在 Amazon Glue 控制台上,在导航窗格的数据集成和 ETL下,选择数据分类工具 > 记录匹配,再选择添加转换。按照向导使用以下属性创建
Find matches转换。-
对于 Transform name (转换名称),输入
demo-xform-dblp-acm。这是用于在源数据中查找匹配项的转换的名称。 -
对于 IAM role (IAM 角色),选择对 Amazon S3 源数据、标签文件和 Amazon Glue API 操作具有权限的 IAM 角色。有关更多信息,请参阅 Amazon Glue 开发人员指南中的为 Amazon Glue 创建 IAM 角色。
-
对于 Data source (数据源),请在数据库 demo-db-dblp-acm 中选择名为 dblp_acm_records_csv 的表。
-
对于 Primary key (主键),选择表的主键列 id。
-
在向导中,选择 Finish (完成) 并返回 ML transforms (ML 转换) 列表。
步骤 3:指导您的机器学习转换
接下来,您使用教程示例标签文件来指导您的机器学习转换。
您不能在提取、转换和加载 (ETL) 任务中使用机器语言转换,直到其状态为 Ready for use (可供使用)。要准备好转换,您必须通过提供匹配记录和不匹配记录的示例来指导它如何识别匹配记录和不匹配记录。要指导您的转换,您可以 Generate a label file (生成标签文件),添加标签,然后 Upload label file (上传标签文件)。在本教程中,您可以使用名为 dblp_acm_labels.csv 的示例标签文件。有关标记过程的更多信息,请参阅 标签。
-
在 Amazon Glue 控制台的导航窗格中,选择记录匹配。
-
选择
demo-xform-dblp-acm转换,然后选择 Action (操作)、Teach (指导)。按照向导指导您的Find matches转换。 在转换属性页面上,选择 I have labels (我有标签)。选择当前 Amazon 区域中的示例标签文件的 Amazon S3 路径。例如,对于
us-east-1,请从 Amazon S3 路径s3://ml-transforms-public-datasets-us-east-1/dblp-acm/labels/dblp_acm_labels.csv上传提供的标签文件,并选择 overwrite (覆盖) 现有标签。标签文件必须位于与 Amazon Glue 控制台相同的区域中的 Amazon S3 中。上传标签文件时,会在 Amazon Glue 中启动任务以添加或覆盖用于指导转换过程如何处理数据源的标签。
在向导的最后一页上,选择 Finish (完成),然后返回到 ML transforms (ML 转换) 列表。
步骤 4:估计您的机器学习转换的质量
接下来,您可以估计您的机器学习转换的质量。质量取决于您的标签数。有关估计质量的更多信息,请参阅 估计质量。
-
在 Amazon Glue 控制台上,在导航窗格的数据集成和 ETL下,选择数据分类工具 > 记录匹配。
-
选择
demo-xform-dblp-acm转换,然后选择 Estimate quality (估计质量) 选项卡。此选项卡显示转换的当前质量估计(如果有)。 选择 Estimate quality (估计质量) 以开始一项任务来估计转换的质量。质量估计的准确性基于源数据的标记。
导航到 History (历史记录) 选项卡。在此窗格中,列出转换的任务运行,包括 Estimating quality (估计质量) 任务。有关运行的更多详细信息,请选择 Logs (日志)。在运行完成时,检查其状态是否为 Succeeded (成功)。
步骤 5:使用机器学习转换添加和运行作业
在此步骤中,您将使用您的机器学习转换在 Amazon Glue 中添加和运行作业。当转换 demo-xform-dblp-acm 为 Ready for use (可供使用) 时,您可以在 ETL 作业中使用它。
-
在 Amazon Glue 控制台的导航窗格中,选择 Jobs (任务)。
-
选择 Add job (添加任务),然后执行向导中的步骤以使用生成的脚本创建 ETL Spark 任务。为转换选择以下属性值:
-
对于 Name (名称),选择此教程中的示例任务 demo-etl-dblp-acm。
-
对于 IAM role (IAM 角色),选择对 Amazon S3 源数据、标签文件和 Amazon Glue API 操作具有权限的 IAM 角色。有关更多信息,请参阅 Amazon Glue 开发人员指南中的为 Amazon Glue 创建 IAM 角色。
-
对于 ETL language (ETL 语言),选择 Scala。这是 ETL 脚本中的编程语言。
-
对于 Script file name (脚本文件名称),选择 demo-etl-dblp-acm。这是 Scala 脚本的文件名称(与作业名称相同)。
-
对于 Data source (数据源),选择 dblp_acm_records_csv。您选择的数据源必须与机器学习转换数据源架构匹配。
-
对于 Transform type (转换类型),选择 Find matching records (查找匹配记录) 以使用机器学习转换来创建任务。
-
清除 Remove duplicate records (删除重复记录)。您不想删除重复记录,因为写入的输出记录添加了额外的
match_id字段。 -
对于 Transform (转换),选择 demo-xform-dblp-acm(作业所使用的机器学习转换)。
-
对于 Create tables in your data target (在数据目标中创建表),选择使用以下属性创建表:
-
Data store type (数据存储类型) –
Amazon S3 -
Format (格式) –
CSV -
Compression type (压缩类型) –
None -
Target path (目标路径) – 在其中写入任务的输出的 Amazon S3 路径(在当前控制台 Amazon 区域中)
-
-
-
选择 Save job and edit script (保存任务和编辑脚本) 以显示脚本编辑器页。
-
编辑脚本来添加语句,使 Target path (目标路径) 的任务输出写入单个分区文件中。在运行
FindMatches转换的语句后添加此语句。此语句类似于以下内容。val single_partition = findmatches1.repartition(1)您必须修改
.writeDynamicFrame(findmatches1)语句以将输出写入为.writeDynamicFrame(single_partion)。 -
在编辑脚本后,请选择 Save (保存)。修改后的脚本看上去类似于以下代码,但它已针对您的环境进行了自定义。
import com.amazonaws.services.glue.GlueContext import com.amazonaws.services.glue.errors.CallSite import com.amazonaws.services.glue.ml.FindMatches import com.amazonaws.services.glue.util.GlueArgParser import com.amazonaws.services.glue.util.Job import com.amazonaws.services.glue.util.JsonOptions import org.apache.spark.SparkContext import scala.collection.JavaConverters._ object GlueApp { def main(sysArgs: Array[String]) { val spark: SparkContext = new SparkContext() val glueContext: GlueContext = new GlueContext(spark) // @params: [JOB_NAME] val args = GlueArgParser.getResolvedOptions(sysArgs, Seq("JOB_NAME").toArray) Job.init(args("JOB_NAME"), glueContext, args.asJava) // @type: DataSource // @args: [database = "demo-db-dblp-acm", table_name = "dblp_acm_records_csv", transformation_ctx = "datasource0"] // @return: datasource0 // @inputs: [] val datasource0 = glueContext.getCatalogSource(database = "demo-db-dblp-acm", tableName = "dblp_acm_records_csv", redshiftTmpDir = "", transformationContext = "datasource0").getDynamicFrame() // @type: FindMatches // @args: [transformId = "tfm-123456789012", emitFusion = false, survivorComparisonField = "<primary_id>", transformation_ctx = "findmatches1"] // @return: findmatches1 // @inputs: [frame = datasource0] val findmatches1 = FindMatches.apply(frame = datasource0, transformId = "tfm-123456789012", transformationContext = "findmatches1", computeMatchConfidenceScores = true)// Repartition the previous DynamicFrame into a single partition. val single_partition = findmatches1.repartition(1)// @type: DataSink // @args: [connection_type = "s3", connection_options = {"path": "s3://aws-glue-ml-transforms-data/sal"}, format = "csv", transformation_ctx = "datasink2"] // @return: datasink2 // @inputs: [frame = findmatches1] val datasink2 = glueContext.getSinkWithFormat(connectionType = "s3", options = JsonOptions("""{"path": "s3://aws-glue-ml-transforms-data/sal"}"""), transformationContext = "datasink2", format = "csv").writeDynamicFrame(single_partition) Job.commit() } } 选择 Run job (运行任务) 以开始作业运行。检查任务列表中的作业的状态。任务完成后,在 ML transform (ML 转换)、History (历史记录) 选项卡上,会添加一个 ETL job (ETL 任务) 类型的新 Run ID (运行 ID)。
导航到 Jobs (任务)、History (历史记录) 选项卡。在此窗格中,将列出任务运行。有关运行的更多详细信息,请选择 Logs (日志)。在运行完成时,检查其状态是否为 Succeeded (成功)。
步骤 6:验证来自 Amazon S3 的输出数据
在这一步中,您将在添加任务时选择的 Amazon S3 存储桶中检查任务运行的输出。您可以将输出文件下载到本地计算机,并验证是否已标识匹配的记录。
通过以下网址打开 Amazon S3 控制台:https://console.aws.amazon.com/s3/
。 下载任务
demo-etl-dblp-acm的目标输出文件。在电子表格应用程序中打开文件(您可能需要为文件添加文件扩展名.csv以使其正常打开)。下图通过 Microsoft Excel 显示了输出摘录。
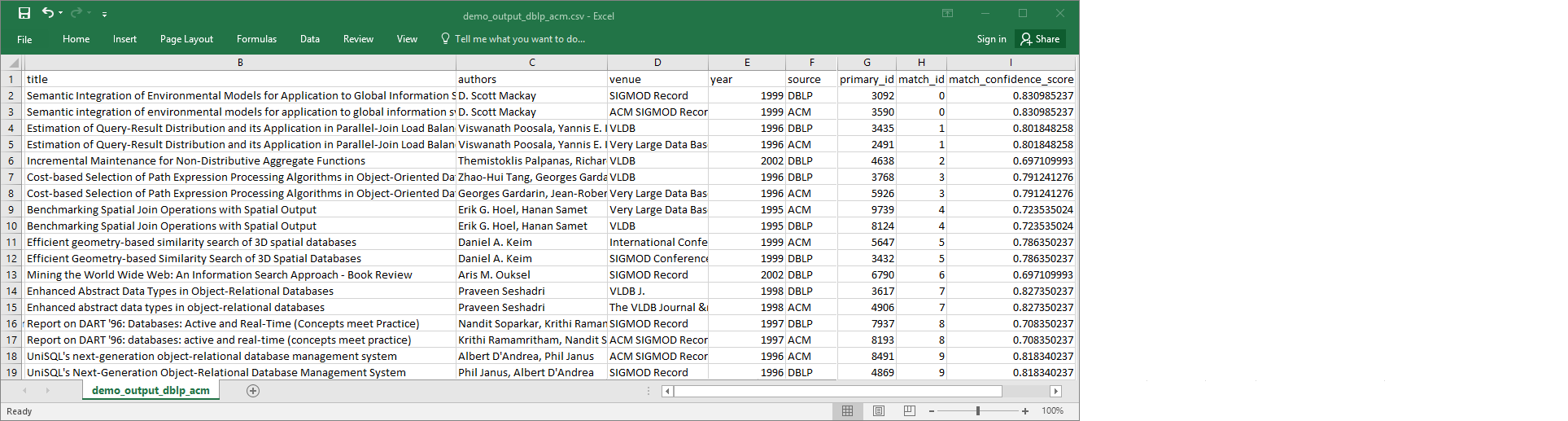
数据源和目标文件都有 4911 条记录。不过,
Find matches转换会添加另一个名为match_id的列以标识输出中的匹配记录。具有相同match_id的行被视为匹配记录。match_confidence_score是一个介于 0 与 1 之间的数字,它为Find matches找到的匹配项的质量提供一个估计值。-
按
match_id对输出文件进行排序可轻松查看匹配的记录。比较其他列中的值以查看您是否同意Find matches转换的结果。如果您不同意,则可通过添加更多标签来继续指导转换。您也可以按其他字段(例如
title)对文件进行排序,以查看具有相似标题的记录的match_id是否相同。