监控 DPU 容量规划
您可以使用 Amazon Glue 中的作业指标估算可用于扩展 Amazon Glue 作业的数据处理单元 (DPU) 的数量。
注意
此页面仅适用于 Amazon Glue 0.9 和 1.0 版。最新版本的 Amazon Glue 包含成本节省功能,介绍了在进行容量规划时的其他注意事项。
分析代码
以下脚本读取包含 428 个 gzip 类型 JSON 文件的 Amazon Simple Storage Service(Amazon S3)分区。该脚本应用映射来更改字段名称,以 Apache Parquet 格式转换这些名称并将其写入 Amazon S3。您可以按默认值预置 10 个 DPU 并运行此任务。
datasource0 = glueContext.create_dynamic_frame.from_options(connection_type="s3", connection_options = {"paths": [input_path], "useS3ListImplementation":True,"recurse":True}, format="json") applymapping1 = ApplyMapping.apply(frame = datasource0, mappings = [(map_spec]) datasink2 = glueContext.write_dynamic_frame.from_options(frame = applymapping1, connection_type = "s3", connection_options = {"path": output_path}, format = "parquet")
在 Amazon Glue 控制台上可视化分析指标
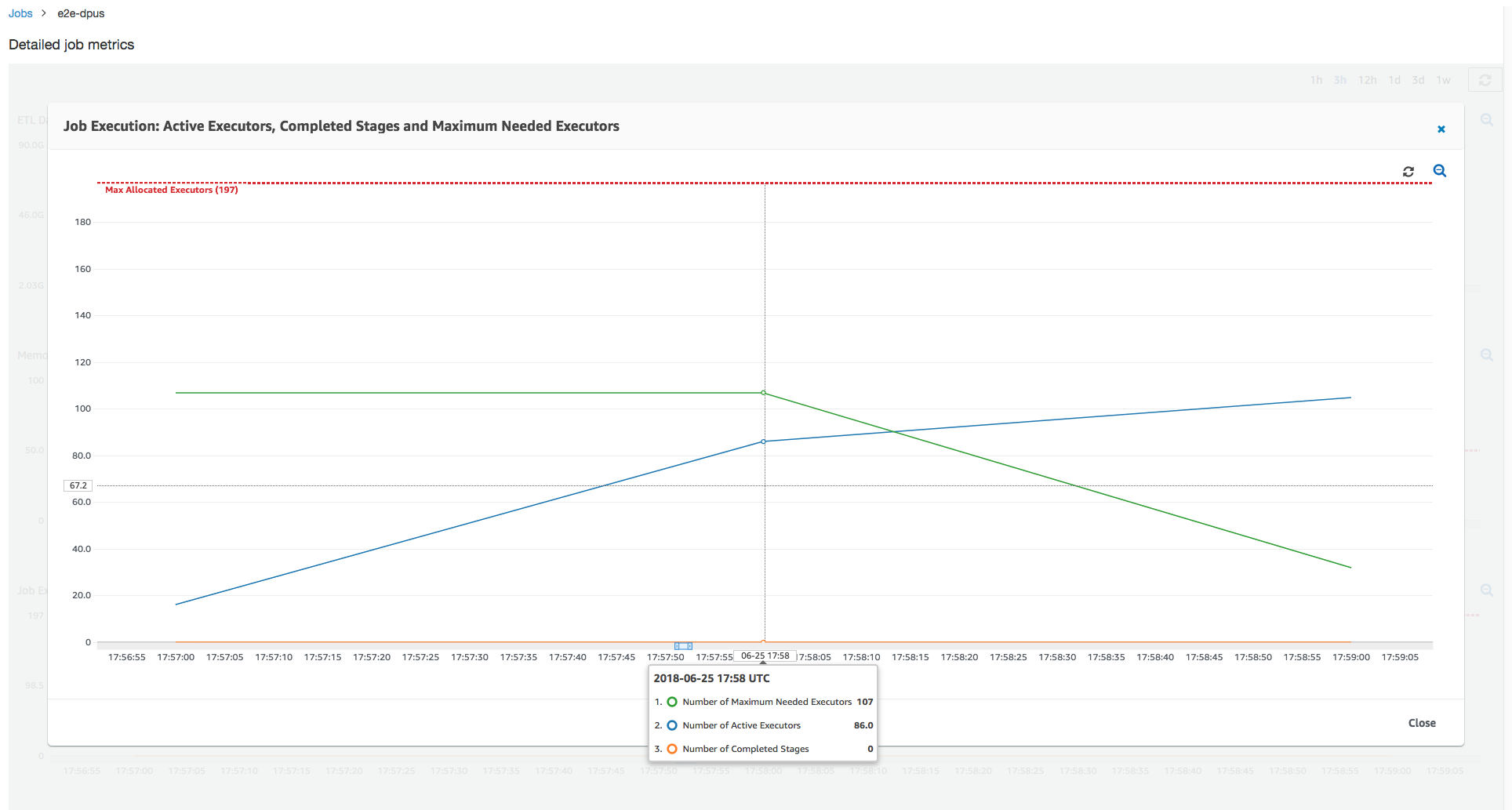
作业运行 1:在此作业运行中,我们将展示如何确定集群中是否存在预配置不足的 DPU。Amazon Glue 中的作业执行功能显示主动运行的执行程序的总数、已完成的阶段数和所需的最大执行程序数。
通过添加正在运行的任务和待处理任务的总数,并将其除以每个执行程序的任务数来计算所需的最大执行程序数。此结果衡量满足当前负载所需的执行程序总数。
相反,主动运行的执行程序的数量衡量运行活动 Apache Spark 任务的执行程序数量。随着作业的运行,所需的最大执行程序数可能发生变化,并且通常会在待处理任务队列减少时向下移动到作业的末尾。
下图中的水平红线显示了最大已分配执行程序数,这取决于您为作业分配的 DPU 数。在此案例中,您为作业运行分配 10 个 DPU。为管理预留一个 DPU。其他九个 DPU 各自运行两个执行程序,并为 Spark 驱动程序保留一个执行程序。Spark 驱动程序在主应用程序内部运行。因此,最大已分配执行程序数为 2*9 - 1 = 17 个执行程序。
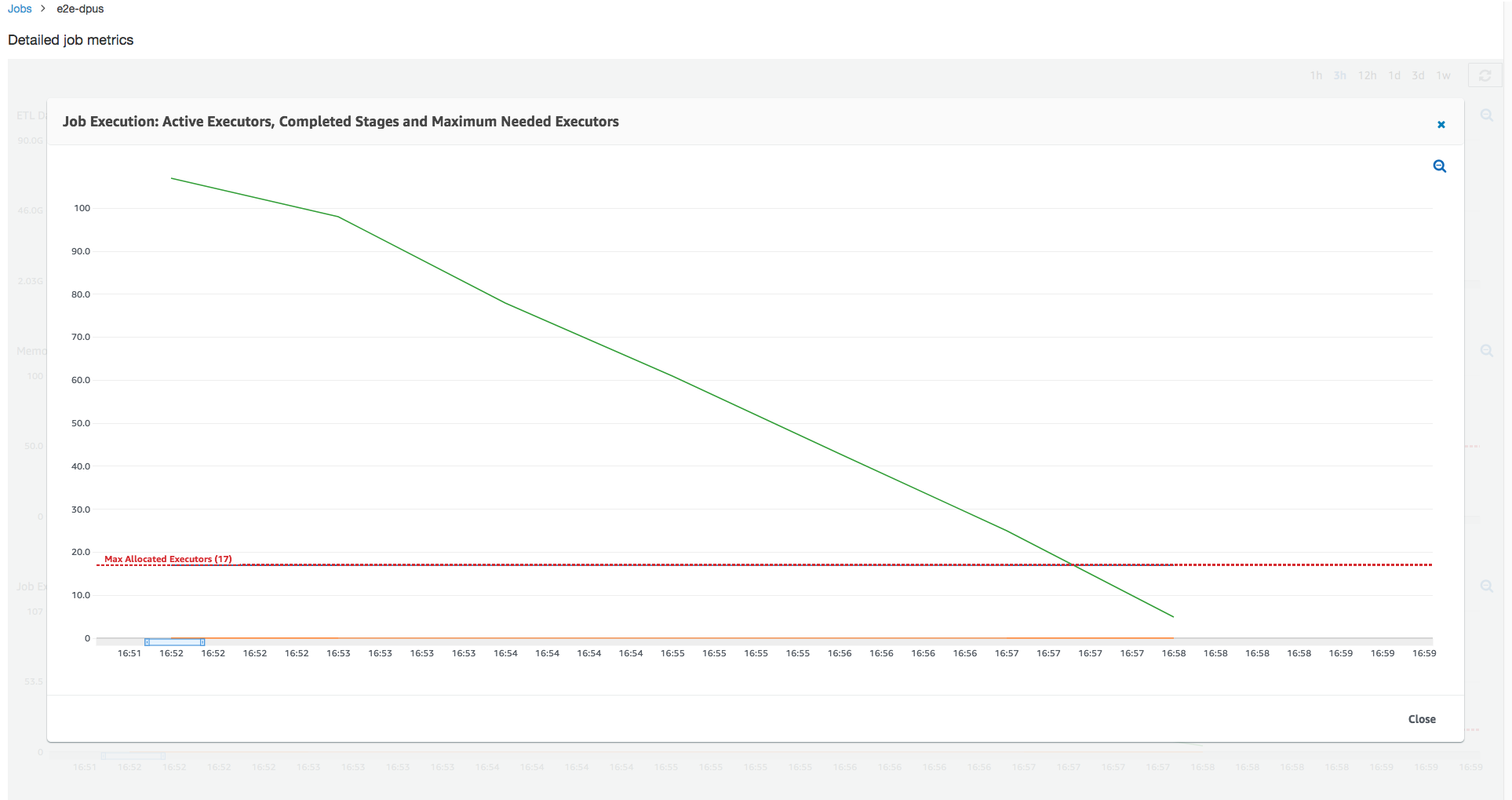
如图所示,所需的最大执行程序数在作业开始时从 107 开始,而活动执行程序数保持为 17。这与具有 10 个 DPU 的最大已分配执行程序数相同。所需的最大执行程序数和最大已分配执行程序数之间的比率(对于 Spark 驱动程序,两者都加 1)会为您提供预配置不足系数:108/18 = 6x。您可以预置 6(在配置比率下)* 9(当前 DPU 容量 - 1)+ 1 个 DPU = 55 个 DPU 来扩展作业,以最大并行度运行它并更快地完成。
Amazon Glue 控制台将详细的作业指标显示为表示原始最大已分配执行程序数的静态行。控制台从指标的作业定义计算最大已分配执行程序数。相比这下,对于详细的作业运行指标,控制台从作业运行配置计算最大已分配执行程序数,特别是为作业运行分配的 DPU。要查看各个作业运行的指标,请选择作业运行并选择 View run metrics (查看运行指标)。
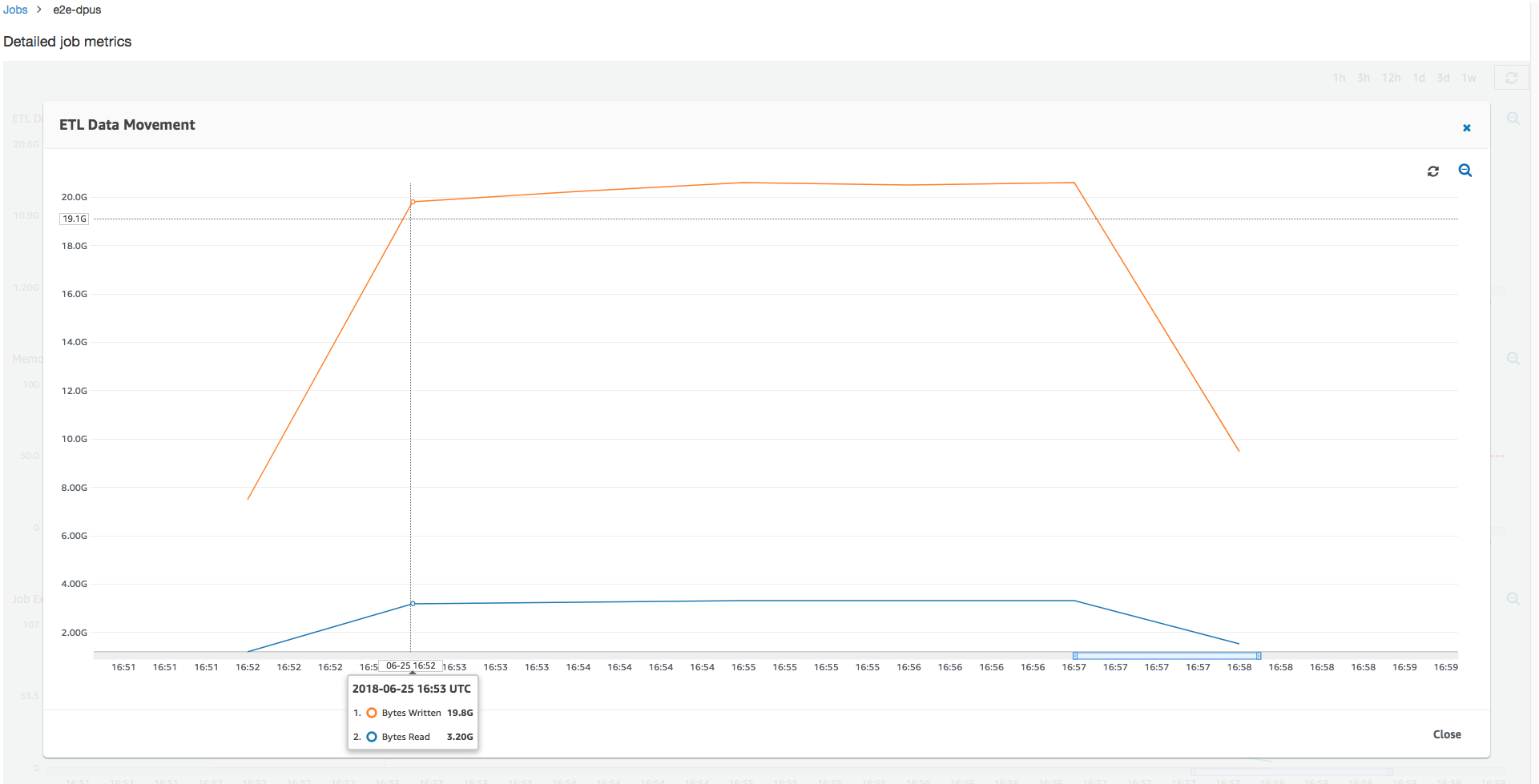
查看读取和写入的 Amazon S3 字节,请注意,该任务花费全部六分钟时间流式传输来自 Amazon S3 的数据并将其并行写出。已分配 DPU 上的所有核心都在读取和写入 Amazon S3。所需最大执行程序数为 107,同样与输入 Amazon S3 路径中的文件数 428 相匹配。每个执行程序可以启动四个 Spark 任务来处理四个输入文件(JSON gzip 类型)。
确定最佳 DPU 容量
根据先前作业运行的结果,您可以将已分配 DPU 总数增加到 55,并查看作业的执行情况。该任务在不到三分钟的时间内完成 – 是之前所需时间的一半。在这种情况下,作业扩展不是线性的,因为它是一个短时间运行作业。具有长期任务或大量任务(所需最大执行程序数)的作业受益于接近线性的 DPU 扩展性能加速。
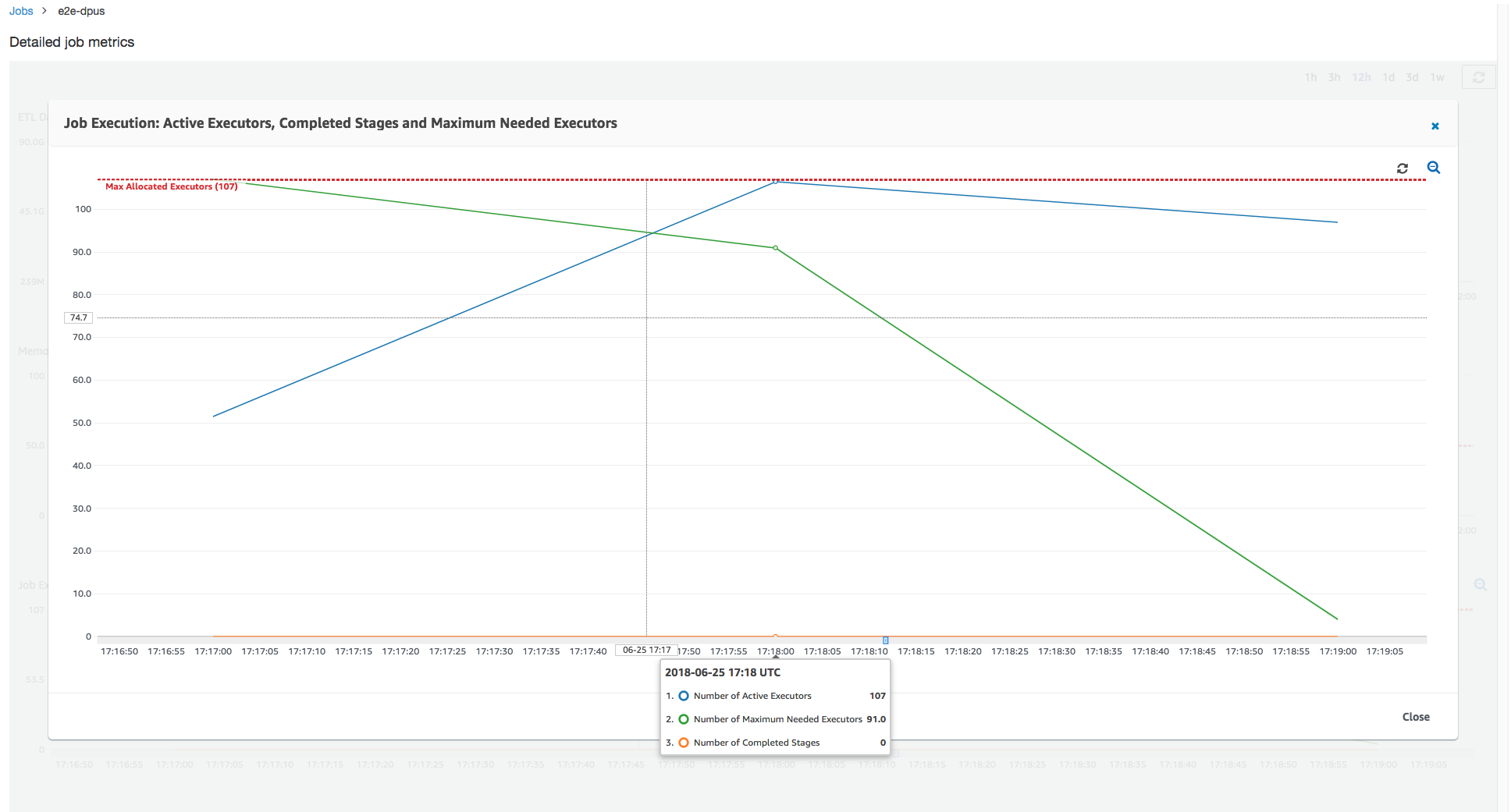
如上图所示,活动执行程序的总数达到最大分配数 – 107 个执行程序。同样,所需的最大执行程序数永远不会超过最大已分配执行程序数。所需的最大执行程序数根据主动运行和待处理任务计数计算,因此可能小于活动执行程序的数量。这是因为可能有执行程序在短时间内部分或完全空闲且尚未停用。
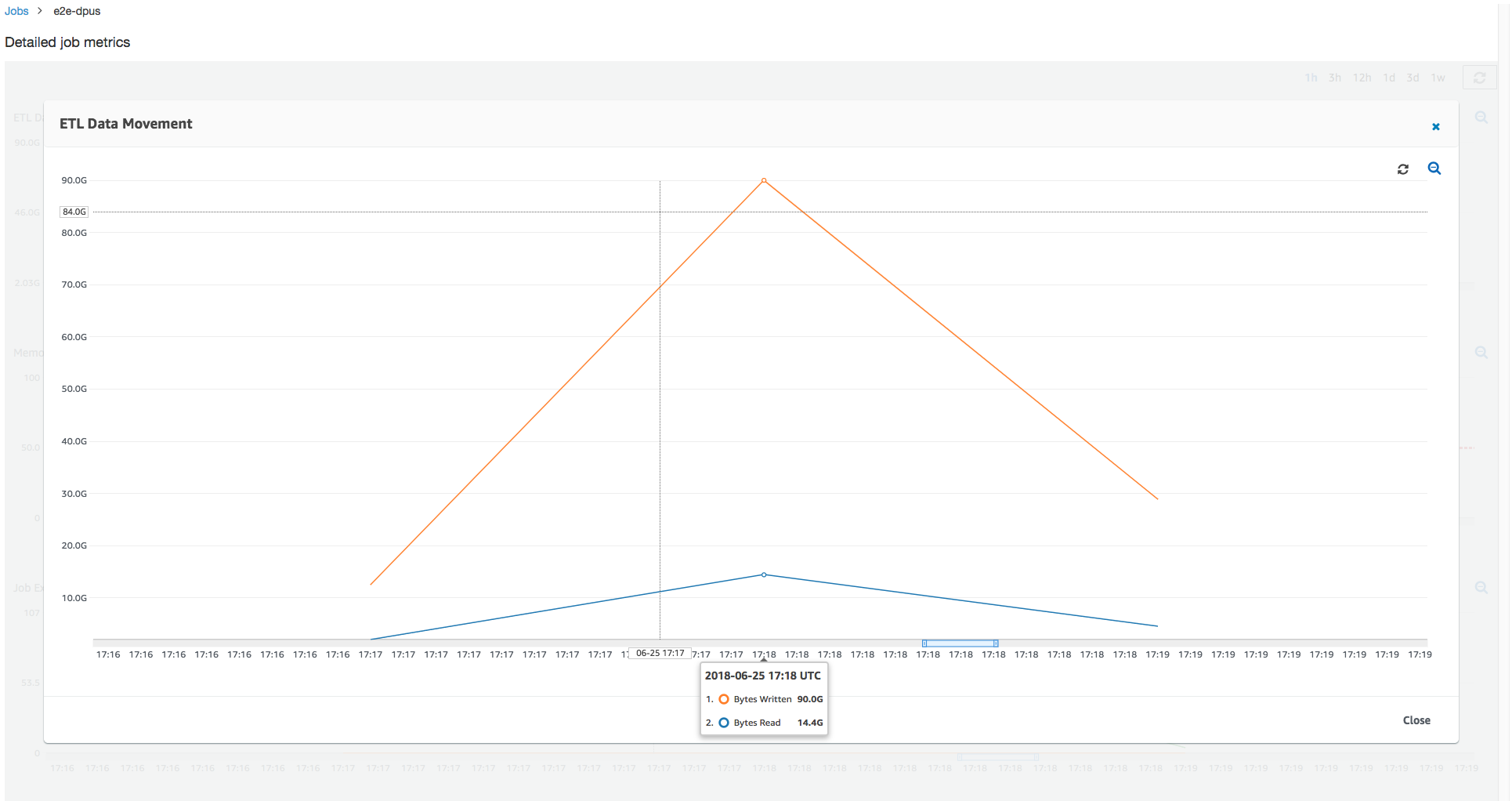
此任务运行使用 6 倍以上的执行程序来并行地在 Amazon S3 中读取和写入。因此,此任务运行使用更多 Amazon S3 带宽进行读取和写入,并且完成得更快。
识别过度预配置的 DPU
接下来,您可以确定使用 100 个 DPU(99 * 2 = 198 个执行程序)扩展作业是否有助于进一步扩展。如下图所示,该作业仍需要三分钟才能完成。同样,作业不会扩展超出 107 个执行程序(55 个 DPU 配置),其余 91 个执行程序被过度配置而根本未使用。这表明增加 DPU 的数量可能并不会始终提高性能,这从所需的最大执行程序数可以看出。
比较时间差异
下表中显示的三次作业运行汇总了 10 个 DPU、55 个 DPU 和 100 个 DPU 的作业执行时间。您可以使用通过监控第一次作业运行建立的估计值来查找 DPU 容量以缩短作业执行时间。
| 作业 ID | DPU 数量 | 执行时间 |
|---|---|---|
| jr_c894524c8ef5048a4d9... | 10 | 6 分钟 |
| jr_1a466cf2575e7ffe6856... | 55 | 3 分钟 |
| jr_34fa1ed4c6aa9ff0a814... | 100 | 3 分钟 |