监控多个作业的进度
您可以一起分析多个 Amazon Glue 作业并监控它们之间的数据流。这是一种常见的工作流模式,需要监控单个作业进度、数据处理积压、数据重新处理和作业书签。
分析代码
在此工作流程中,您有两个作业:一个输入作业和一个输出作业。输入作业计划使用定期触发器每 30 分钟运行一次。输出作业计划在每次成功运行输入作业后运行。可使用作业触发器控制这些计划作业。

输入任务:此任务从 Amazon Simple Storage Service(Amazon S3)位置读取数据,使用 ApplyMapping 对数据进行转换,并将其写入暂存的 Amazon S3 位置。以下代码是输入作业的分析代码:
datasource0 = glueContext.create_dynamic_frame.from_options(connection_type="s3", connection_options = {"paths": ["s3://input_path"], "useS3ListImplementation":True,"recurse":True}, format="json") applymapping1 = ApplyMapping.apply(frame = datasource0, mappings = [map_spec]) datasink2 = glueContext.write_dynamic_frame.from_options(frame = applymapping1, connection_type = "s3", connection_options = {"path": staging_path, "compression": "gzip"}, format = "json")
输出任务:此任务从 Amazon S3 中的暂存位置读取输入任务的输出,再次对其进行转换,并将其写入目标位置:
datasource0 = glueContext.create_dynamic_frame.from_options(connection_type="s3", connection_options = {"paths": [staging_path], "useS3ListImplementation":True,"recurse":True}, format="json") applymapping1 = ApplyMapping.apply(frame = datasource0, mappings = [map_spec]) datasink2 = glueContext.write_dynamic_frame.from_options(frame = applymapping1, connection_type = "s3", connection_options = {"path": output_path}, format = "json")
在 Amazon Glue 控制台上可视化分析指标
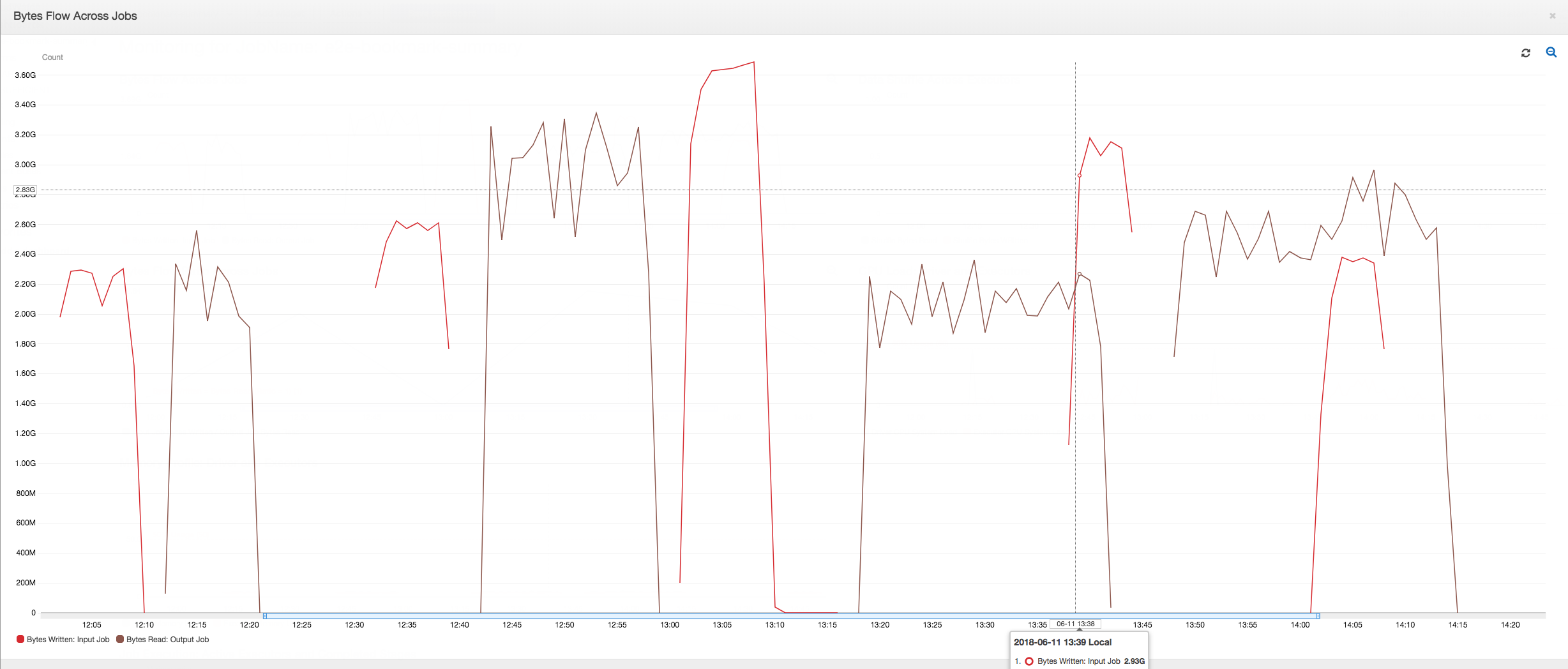
以下控制面板将输入任务中的 Amazon S3 字节写入指标叠加到输出任务的同一时间表的 Amazon S3 字节读取指标上。时间表显示输入和输出作业的不同作业运行。输入作业(以红色显示)每 30 分钟启动一次。输出作业(以棕色显示)在输入作业完成时启动,最大并发数为 1。
在本示例中,未启用作业书签。没有用于在脚本代码中启用作业书签的转换上下文。
作业历史记录:输入和输出作业具有多个从中午 12:00 启动的作业运行,如历史记录选项卡上所示。
Amazon Glue 控制台上的输入任务如下所示:

下图显示了输出作业:

第一次作业运行:如下面的数据字节读取和写入图表所示,在 12:00 到 12:30 之间的输入和输出作业的第一次作业运行显示曲线下大致相同的区域。这些区域表示由输入任务写入的 Amazon S3 字节和由输出任务读取的 Amazon S3 字节。此数据同样通过写入的 Amazon S3 字节的比率(总计超过 30 分钟 – 输入任务的任务触发频率)来确认。中午 12:00 启动的输入作业运行的比率的数据点也是 1。
下图显示了所有作业运行的数据流比率:
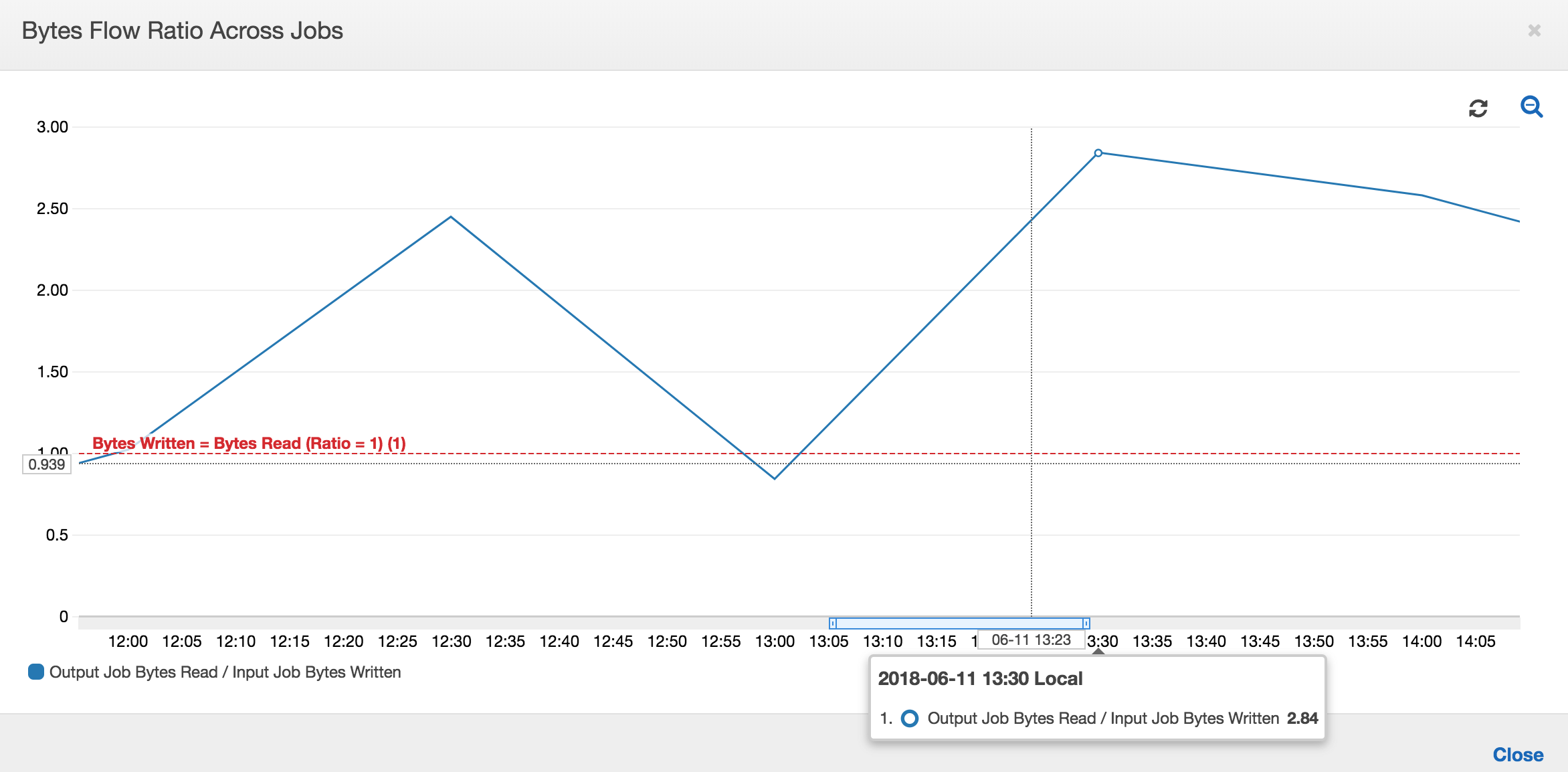
第二次作业运行:在第二次作业运行中,输出作业读取的字节数与输入作业写入的字节数相比明显不同。(比较输出作业的两次作业运行的曲线下的区域,或比较输入和输出作业的第二次运行中的区域。) 读取和写入的字节比率表明,在 12:30 到 13:00 的第二个 30 分钟跨度内,输出作业读取的数据约为输入作业写入的数据的 2.5 倍。这是因为由于未启用作业书签,导致输出作业重新处理了输入作业的第一次作业运行的输出。比率大于 1 表示输出作业处理的数据存在额外的积压。
第三次作业运行:输入作业在写入的字节数方面相当一致(请参阅红色曲线下的区域)。但是,输入作业的第三次作业运行时间比预期的要长(请参阅红色曲线的长尾)。因此,输出作业的第三次作业运行启动较晚。第三次作业运行在 13:00 到 13:30 之间的剩余 30 分钟内仅处理了暂存位置中累积的一小部分数据。字节流的比率表明,它仅处理了由输入作业的第三次作业运行写入的 0.83 数据(请参阅 13:00 的比率)。
重叠的输入和输出作业:输入作业的第四次作业运行按照计划在输出作业的第三次作业运行完成之前于 13:30 启动。这两次作业运行之间存在部分重叠。但是,输出任务的第三次任务运行仅捕获它于 13:17 左右启动时在 Amazon S3 的暂存位置列出的文件。这包括输入作业的第一次作业运行的所有数据输出。13:30 的实际比率约为 2.75。输出作业的第三次作业运行处理了输入作业的第四次作业运行从 13:30 到 14:00 写入的大约 2.75 倍数据。
如这些图像所示,输出作业正在从输入作业的所有先前作业运行中的暂存位置重新处理数据。因此,输出作业的第四次作业运行时间最长,并与输入作业的整个第五次作业运行重叠。
修复文件的处理
您应确保输出作业仅处理输出作业的先前作业运行尚未处理的文件。为此,请启用作业书签并在输出作业中设置转换上下文,如下所示:
datasource0 = glueContext.create_dynamic_frame.from_options(connection_type="s3", connection_options = {"paths": [staging_path], "useS3ListImplementation":True,"recurse":True}, format="json", transformation_ctx = "bookmark_ctx")
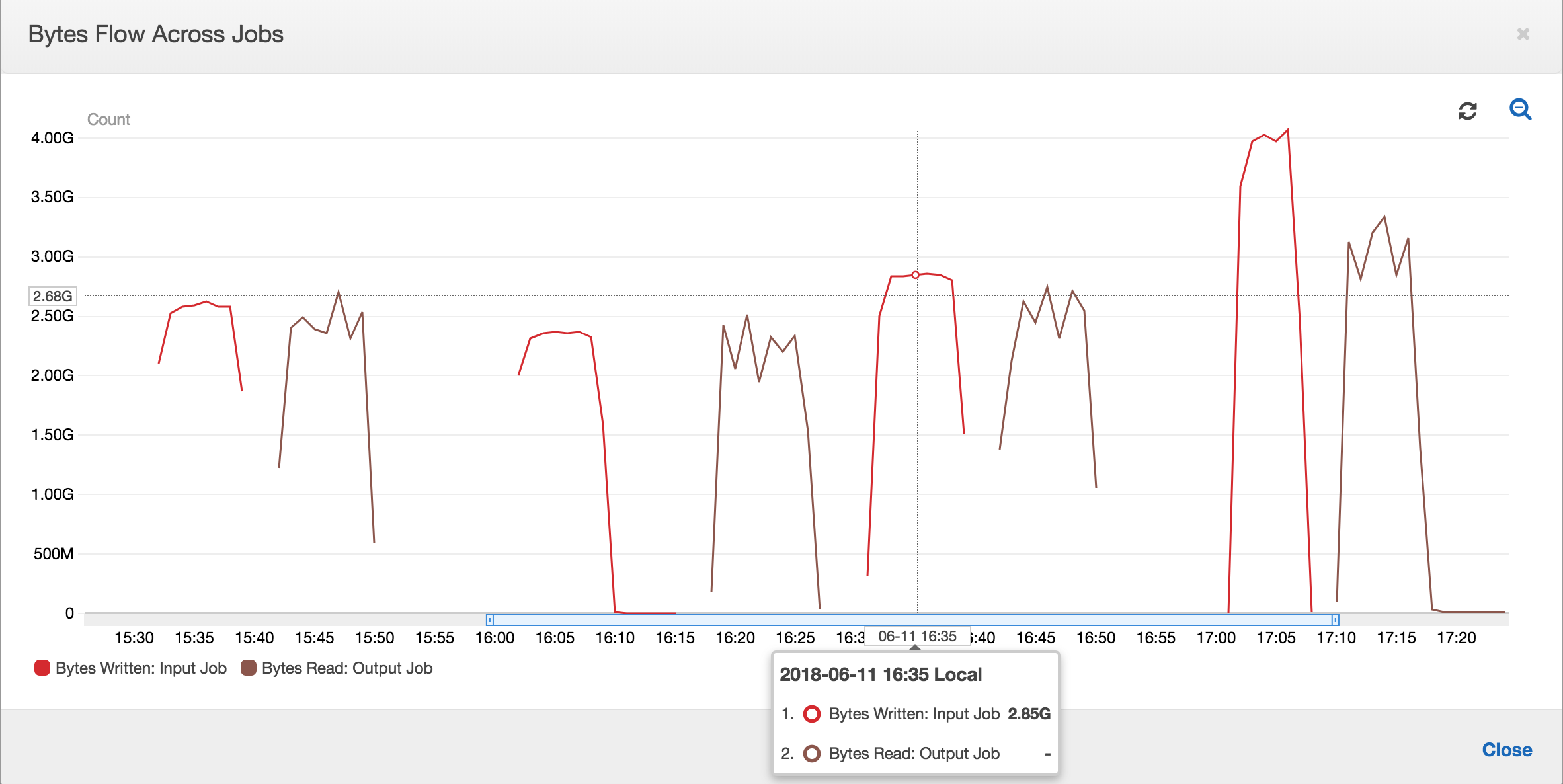
启用作业书签后,输出作业不会重新处理输入作业的所有先前作业运行的暂存位置中的数据。在显示读取和写入数据的下图中,棕色曲线下的区域相当一致,并与红色曲线类似。
字节流的比率还保持大致接近 1,因为没有处理其他数据。
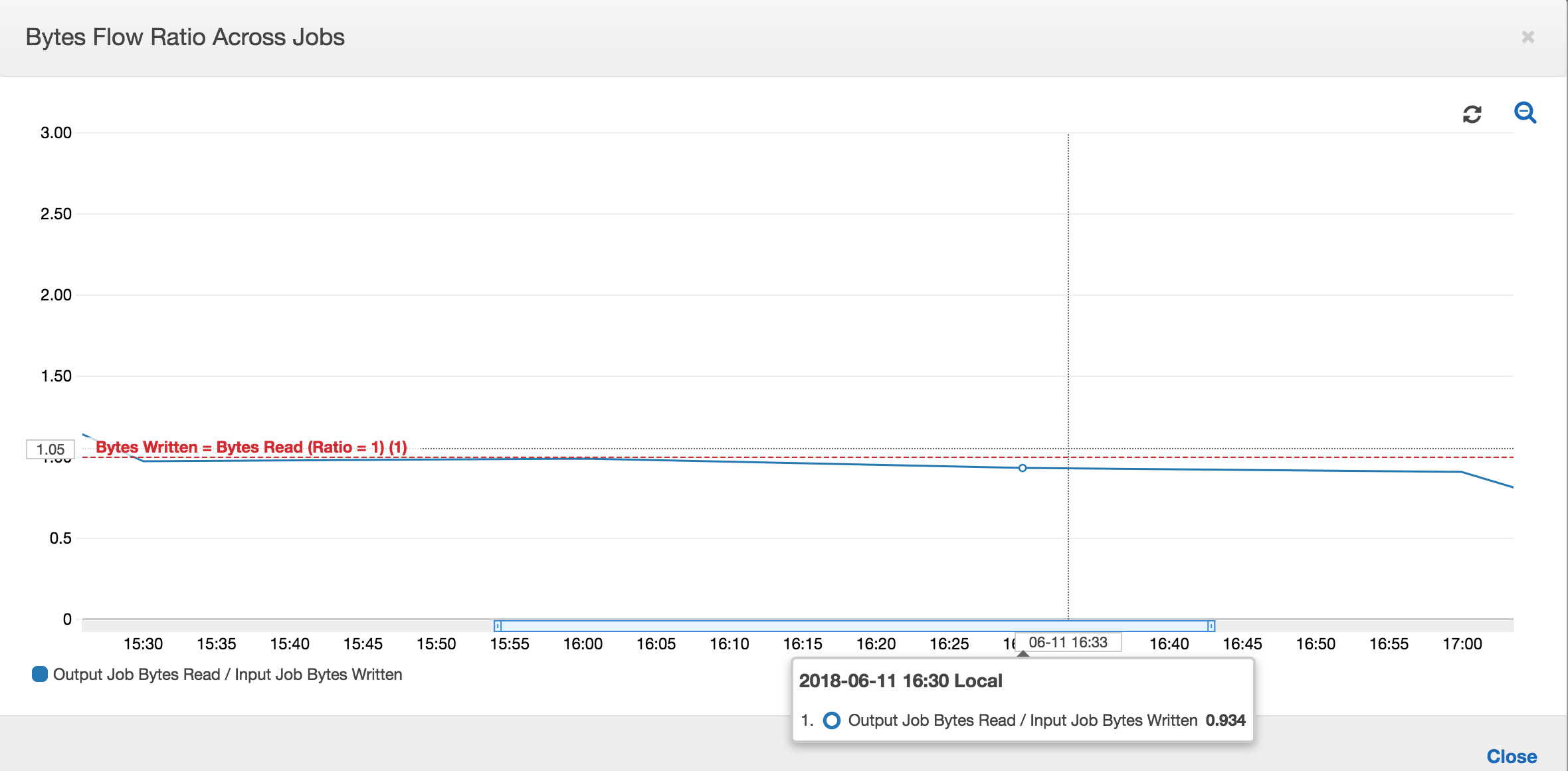
在下一次输入作业运行开始将更多数据放入暂存位置之前,输出作业的作业运行将启动并捕获暂存位置中的文件。只要它继续执行此操作,就会仅处理从先前输入作业运行中捕获的文件,并且该比率保持接近 1。
假设输入作业花费的时间超过预期,那么,输出作业将从两次输入作业运行中捕获暂存位置中的文件。该输出作业运行的比率将大于 1。但是,输出作业的以下作业运行不会处理已由输出作业的先前作业运行处理的任何文件。