使用 Amazon Glue 可观测性指标进行监控
注意
Amazon Glue 可观测性指标在 Amazon Glue 4.0 及更高版本中可用。
使用 Amazon Glue 可观测性指标可深入了解 Amazon Glue 内部发生的情况,以便 Apache Spark 作业可以改进对问题的分类和分析。可观测性指标通过 Amazon CloudWatch 控制面板进行可视化显示,有助于分析错误的根本原因以及诊断性能瓶颈。您可以缩短大规模问题调试所需的时间,从而专注于更快、更有效地解决问题。
Amazon Glue 可观测性提供了以下四组 Amazon CloudWatch 指标:
-
可靠性(即错误类别)– 可轻松确定给定时间范围内可能需要解决的最常见故障原因。
-
性能(即偏斜)– 确定性能瓶颈并应用优化技术。例如,性能因作业偏斜而下降时,可能需要启用 Spark 自适应查询执行并微调优化偏斜联接阈值。
-
吞吐量(即每源/接收器吞吐量)– 监控数据读取和写入的趋势。您还可以针对异常配置 Amazon CloudWatch 警报。
-
资源利用率(即 Worker 线程、内存和磁盘利用率)– 高效地查找容量利用率低的作业。您可能需要为这些作业启用 Amazon Glue 自动扩缩。
Amazon Glue 可观测性指标入门
注意
默认情况下,新指标在 Amazon Glue Studio 控制台中已启用。
在 Amazon Glue Studio 中配置可观测性指标:
-
登录 Amazon Glue 控制台并从控制台菜单中选择 ETL 作业。
-
单击您的作业部分中的作业名称,从而选择作业。
-
选择 Job details(任务详细信息)选项卡。
-
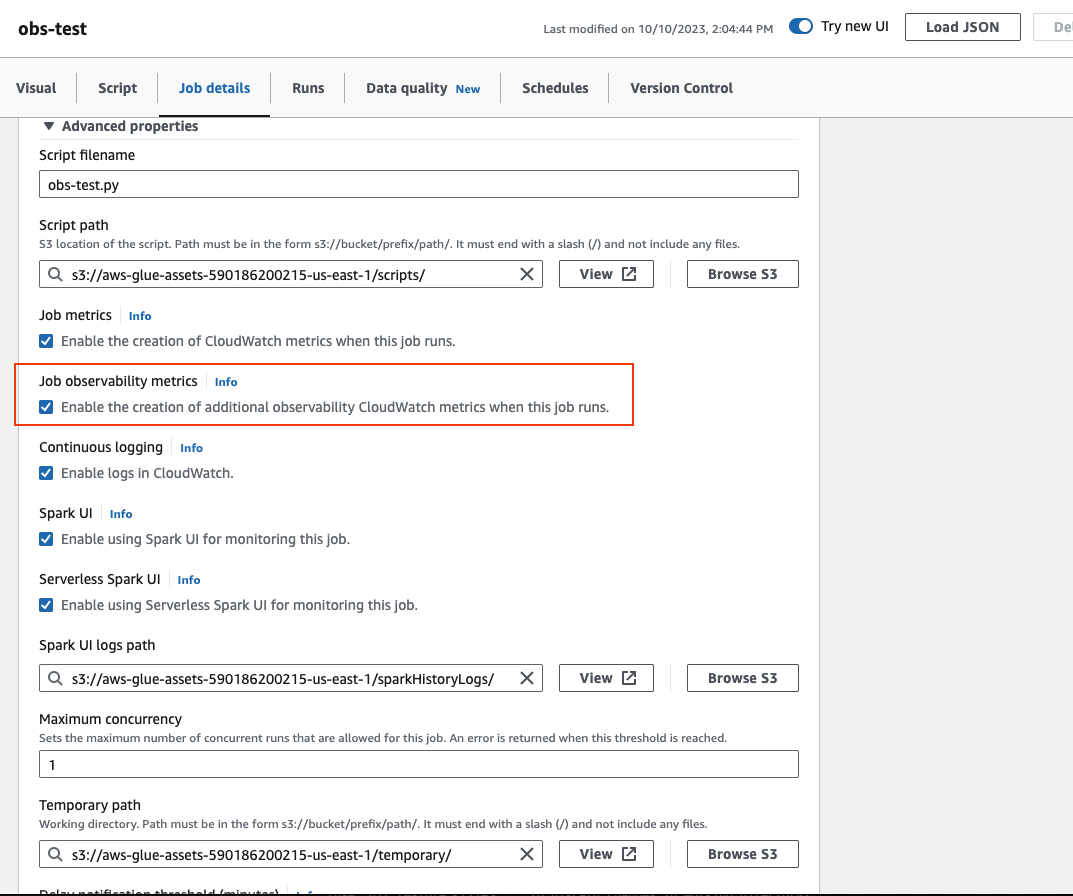
滚动到底部并选择高级属性,然后选择作业可观测性指标。
通过 Amazon CLI 启用 Amazon Glue 可观测性指标:
-
将输入 JSON 文件中的以下键值添加到
--default-arguments映射中:--enable-observability-metrics, true
使用 Amazon Glue 可观测性
由于 Amazon Glue 可观测性指标是通过 Amazon CloudWatch 提供的,因此您可以通过 Amazon CloudWatch 控制台、Amazon CLI、SDK 或 API 来查询可观测性指标数据点。有关何时使用 Amazon Glue 可观测性指标的示例用例,请参阅 Using Glue Observability for monitoring resource utilization to reduce cost
在 Amazon CloudWatch 控制台中使用 Amazon Glue 可观测性
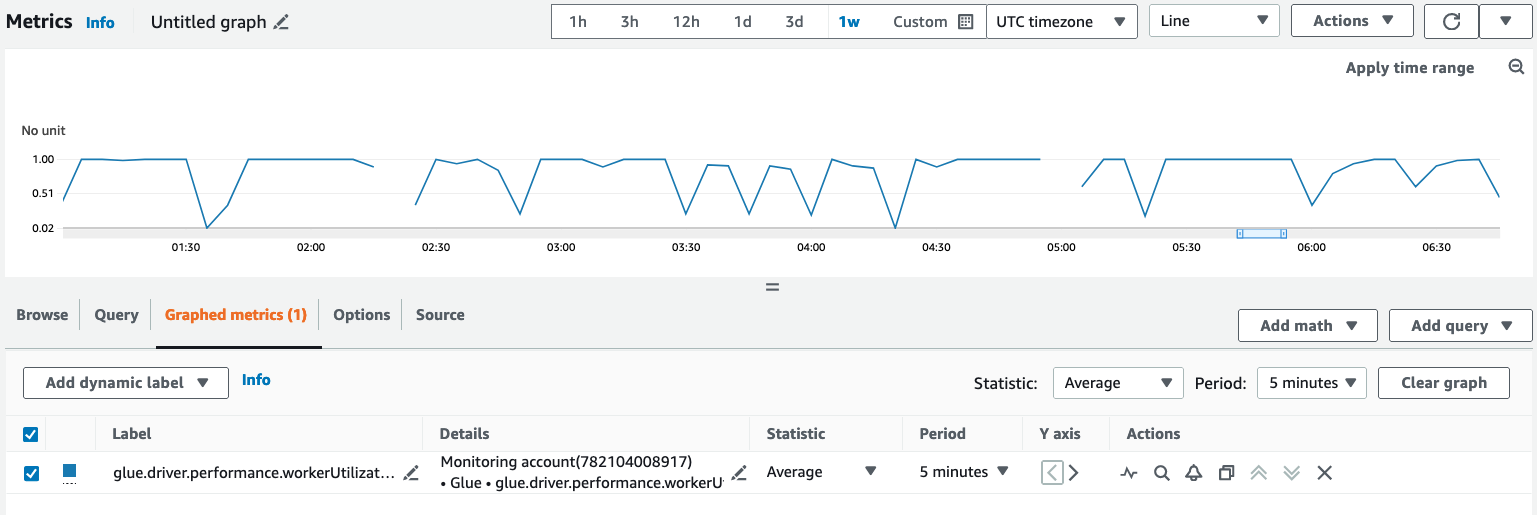
在 Amazon CloudWatch 控制台中查询和可视化显示指标:
-
打开 Amazon CloudWatch 控制台,然后选择 所有指标。
-
在“自定义命名空间”下,选择 Amazon Glue。
-
选择作业可观测性指标、每源可观测性指标或每接收器可观测性指标。
-
搜索特定的指标名称、作业名称、作业运行 ID,然后将其选中。
-
在图形化指标选项卡下,配置您的首选统计数据、周期和其他选项。
使用 Amazon CLI 查询可观测性指标:
-
创建指标定义 JSON 文件并将
your-Glue-job-name和your-Glue-job-run-id替换为您的值。$ cat multiplequeries.json [ { "Id": "avgWorkerUtil_0", "MetricStat": { "Metric": { "Namespace": "Glue", "MetricName": "glue.driver.workerUtilization", "Dimensions": [ { "Name": "JobName", "Value": "<your-Glue-job-name-A>" }, { "Name": "JobRunId", "Value": "<your-Glue-job-run-id-A>" }, { "Name": "Type", "Value": "gauge" }, { "Name": "ObservabilityGroup", "Value": "resource_utilization" } ] }, "Period": 1800, "Stat": "Minimum", "Unit": "None" } }, { "Id": "avgWorkerUtil_1", "MetricStat": { "Metric": { "Namespace": "Glue", "MetricName": "glue.driver.workerUtilization", "Dimensions": [ { "Name": "JobName", "Value": "<your-Glue-job-name-B>" }, { "Name": "JobRunId", "Value": "<your-Glue-job-run-id-B>" }, { "Name": "Type", "Value": "gauge" }, { "Name": "ObservabilityGroup", "Value": "resource_utilization" } ] }, "Period": 1800, "Stat": "Minimum", "Unit": "None" } } ] -
运行
get-metric-data命令:$ aws cloudwatch get-metric-data --metric-data-queries file: //multiplequeries.json \ --start-time '2023-10-28T18: 20' \ --end-time '2023-10-28T19: 10' \ --region us-east-1 { "MetricDataResults": [ { "Id": "avgWorkerUtil_0", "Label": "<your-label-for-A>", "Timestamps": [ "2023-10-28T18:20:00+00:00" ], "Values": [ 0.06718750000000001 ], "StatusCode": "Complete" }, { "Id": "avgWorkerUtil_1", "Label": "<your-label-for-B>", "Timestamps": [ "2023-10-28T18:50:00+00:00" ], "Values": [ 0.5959183673469387 ], "StatusCode": "Complete" } ], "Messages": [] }
可观测性指标
Amazon Glue 可观测性每隔 30 秒分析以下指标并将其发送到 Amazon CloudWatch,其中一些指标可以在 Amazon Glue Studio 作业运行监测页面中看到。
| 指标 | 说明 | 类别 |
|---|---|---|
| glue.driver.skewness.stage |
指标类别:job_performance Spark 分阶段执行偏度:该指标反映特定阶段内最长任务持续时间与该阶段任务持续时间中位数相比的差异程度。此指标捕获执行偏度,这可能是由输入数据偏度或转换(例如,偏斜联接)引起的。该指标值的范围是 [0, 无穷大],其中 0 表示该阶段中所有任务中最长任务执行时间与中值任务执行时间的比率,小于某个阶段偏度系数。默认的阶段偏度系数为“5”,可以通过 spark conf 进行覆盖:spark.metrics.conf.driver.source.glue.jobPerformance.skewnessFactor 阶段偏度值为 1 表示该比率是阶段偏度系数的两倍。 阶段偏度值每 30 秒更新一次,以反映当前偏度。阶段结束时的值反映了最终阶段偏度。 此阶段级指标用于计算作业级指标 有效维度:JobName(Amazon Glue 作业名称)、JobRunId(JobRun ID 或 ALL)、Type(量规)和 ObservabilityGroup (job_performance) 有效统计信息:平均值、最大值、最小值、百分比 单位:个 |
job_performance |
| glue.driver.skewness.job |
指标类别:job_performance 作业偏度是所有阶段加权偏度的最大值。阶段偏度 (glue.driver.skewness.stage) 采用阶段持续时间加权计算。这是为了避免极端的情况,即一个非常偏斜的阶段相对于其他阶段实际上运行的时间很短(因此其偏度对整体作业性能并不重要,也没必要费力解决其偏度)。 该指标在每个阶段完成后更新,因此最后一个值反映了实际的整体作业偏度。 有效维度:JobName(Amazon Glue 作业名称)、JobRunId(JobRun ID 或 ALL)、Type(量规)和 ObservabilityGroup(job_performance) 有效统计信息:平均值、最大值、最小值、百分比 单位:个 |
job_performance |
| glue.succeed.ALL |
指标类别:错误 成功运行的作业总数,以全面了解失败类别 有效维度:JobName(Amazon Glue 作业名称)、JobRunId(JobRun ID 或 ALL)、Type(计数)和 ObservabilityGroup(错误) 有效统计信息:SUM 单位:个 |
错误 |
| glue.error.ALL |
指标类别:错误 作业运行错误总数,以全面了解失败类别 有效维度:JobName(Amazon Glue 作业名称)、JobRunId(JobRun ID 或 ALL)、Type(计数)和 ObservabilityGroup(错误) 有效统计信息:SUM 单位:个 |
错误 |
| glue.error.[错误类别] |
指标类别:错误 这实际上是一组指标,只有在作业运行失败时才会更新。错误分类有助于分类和调试。作业运行失败时,会对导致失败的错误进行分类,并将相应的错误类别指标设置为 1。这有助于执行一段时间内的故障分析,以及对所有作业进行错误分析,以确定最常见的失败类别并开始解决这些问题。Amazon Glue 有 28 个错误类别,包括 OUT_OF_MEMORY(驱动程序和执行程序)、PERMISSION、SYNTAX 和 THROTTLING 错误类别。错误类别还包括 COMPILATION、LAUNCH 和 TIMEOUT 错误类别。 有效维度:JobName(Amazon Glue 作业名称)、JobRunId(JobRun ID 或 ALL)、Type(计数)和 ObservabilityGroup(错误) 有效统计信息:SUM 单位:个 |
错误 |
| glue.driver.workerUtilization |
指标类别:resource_utilization 实际使用的已分配工作人员的百分比。如果效果不佳,自动扩缩功能可以提供帮助。 有效维度:JobName(Amazon Glue 作业名称)、JobRunId(JobRun ID 或 ALL)、Type(量规)和 ObservabilityGroup(resource_utilization) 有效统计信息:平均值、最大值、最小值、百分比 单位:百分比 |
resource_utilization |
| glue.driver.memory.heap.[available | used] |
指标类别:resource_utilization 作业运行期间,驱动程序的可用/已用堆内存。这有助于了解内存使用趋势,尤其是随时间推移而来的内存使用趋势,从而能帮助避免潜在的故障,此外还可以调试与内存相关的故障。 有效维度:JobName(Amazon Glue 作业名称)、JobRunId(JobRun ID 或 ALL)、Type(量规)和 ObservabilityGroup(resource_utilization) 有效统计信息:平均值 单位:字节 |
resource_utilization |
| glue.driver.memory.heap.used.percentage |
指标类别:resource_utilization 作业运行期间,驱动程序的已用堆内存(%)。这有助于了解内存使用趋势,尤其是随时间推移而来的内存使用趋势,从而能帮助避免潜在的故障,此外还可以调试与内存相关的故障。 有效维度:JobName(Amazon Glue 作业名称)、JobRunId(JobRun ID 或 ALL)、Type(量规)和 ObservabilityGroup(resource_utilization) 有效统计信息:平均值 单位:百分比 |
resource_utilization |
| glue.driver.memory.non-heap.[available | used] |
指标类别:resource_utilization 作业运行期间,驱动程序的可用/已用非堆内存。这有助于了解内存使用趋势,尤其是随时间推移而来的内存使用趋势,这有助于避免潜在的故障,此外还可以调试与内存相关的故障。 有效维度:JobName(Amazon Glue 作业名称)、JobRunId(JobRun ID 或 ALL)、Type(量规)和 ObservabilityGroup(resource_utilization) 有效统计信息:平均值 单位:字节 |
resource_utilization |
| glue.driver.memory.non-heap.used.percentage |
指标类别:resource_utilization 作业运行期间,驱动程序的已用非堆内存(%)。这有助于了解内存使用趋势,尤其是随时间推移而来的内存使用趋势,从而能帮助避免潜在的故障,此外还可以调试与内存相关的故障。 有效维度:JobName(Amazon Glue 作业名称)、JobRunId(JobRun ID 或 ALL)、Type(量规)和 ObservabilityGroup(resource_utilization) 有效统计信息:平均值 单位:百分比 |
resource_utilization |
| glue.driver.memory.total.[available | used] |
指标类别:resource_utilization 作业运行期间,驱动程序的可用/已用总内存。这有助于了解内存使用趋势,尤其是随时间推移而来的内存使用趋势,从而能帮助避免潜在的故障,此外还可以调试与内存相关的故障。 有效维度:JobName(Amazon Glue 作业名称)、JobRunId(JobRun ID 或 ALL)、Type(量规)和 ObservabilityGroup(resource_utilization) 有效统计信息:平均值 单位:字节 |
resource_utilization |
| glue.driver.memory.total.used.percentage |
指标类别:resource_utilization 作业运行期间,驱动程序的已用总内存(%)。这有助于了解内存使用趋势,尤其是随时间推移而来的内存使用趋势,从而能帮助避免潜在的故障,此外还可以调试与内存相关的故障。 有效维度:JobName(Amazon Glue 作业名称)、JobRunId(JobRun ID 或 ALL)、Type(量规)和 ObservabilityGroup(resource_utilization) 有效统计信息:平均值 单位:百分比 |
resource_utilization |
| glue.ALL.memory.heap.[available | used] |
指标类别:resource_utilization 执行程序的可用/已用堆内存。ALL 表示所有执行程序。 有效维度:JobName(Amazon Glue 作业名称)、JobRunId(JobRun ID 或 ALL)、Type(量规)和 ObservabilityGroup(resource_utilization) 有效统计信息:平均值 单位:字节 |
resource_utilization |
| glue.ALL.memory.heap.used.percentage |
指标类别:resource_utilization 执行程序的已用堆内存(%)。ALL 表示所有执行程序。 有效维度:JobName(Amazon Glue 作业名称)、JobRunId(JobRun ID 或 ALL)、Type(量规)和 ObservabilityGroup(resource_utilization) 有效统计信息:平均值 单位:百分比 |
resource_utilization |
| glue.ALL.memory.non-heap.[available | used] |
指标类别:resource_utilization 执行程序的可用/已用非堆内存。ALL 表示所有执行程序。 有效维度:JobName(Amazon Glue 作业名称)、JobRunId(JobRun ID 或 ALL)、Type(量规)和 ObservabilityGroup(resource_utilization) 有效统计信息:平均值 单位:字节 |
resource_utilization |
| glue.ALL.memory.non-heap.used.percentage |
指标类别:resource_utilization 执行程序的已用非堆内存(%)。ALL 表示所有执行程序。 有效维度:JobName(Amazon Glue 作业名称)、JobRunId(JobRun ID 或 ALL)、Type(量规)和 ObservabilityGroup(resource_utilization) 有效统计信息:平均值 单位:百分比 |
resource_utilization |
| glue.ALL.memory.total.[available | used] |
指标类别:resource_utilization 执行程序的可用/已用总内存。ALL 表示所有执行程序。 有效维度:JobName(Amazon Glue 作业名称)、JobRunId(JobRun ID 或 ALL)、Type(量规)和 ObservabilityGroup(resource_utilization) 有效统计信息:平均值 单位:字节 |
resource_utilization |
| glue.ALL.memory.total.used.percentage |
指标类别:resource_utilization 执行程序的已用总内存(%)。ALL 表示所有执行程序。 有效维度:JobName(Amazon Glue 作业名称)、JobRunId(JobRun ID 或 ALL)、Type(量规)和 ObservabilityGroup(resource_utilization) 有效统计信息:平均值 单位:百分比 |
resource_utilization |
| glue.driver.disk.[available_GB | used_GB] |
指标类别:resource_utilization 作业运行期间,驱动程序的可用/已用磁盘空间。这有助于了解磁盘使用趋势,尤其是随时间推移而来的内存使用趋势,从而能帮助避免潜在的故障,此外还可以调试与充足磁盘空间相关的故障。 有效维度:JobName(Amazon Glue 作业名称)、JobRunId(JobRun ID 或 ALL)、Type(量规)和 ObservabilityGroup(resource_utilization) 有效统计信息:平均值 单位:千兆字节 |
resource_utilization |
| glue.driver.disk.used.percentage] |
指标类别:resource_utilization 作业运行期间,驱动程序的可用/已用磁盘空间。这有助于了解磁盘使用趋势,尤其是随时间推移而来的内存使用趋势,从而能帮助避免潜在的故障,此外还可以调试与充足磁盘空间相关的故障。 有效维度:JobName(Amazon Glue 作业名称)、JobRunId(JobRun ID 或 ALL)、Type(量规)和 ObservabilityGroup(resource_utilization) 有效统计信息:平均值 单位:百分比 |
resource_utilization |
| glue.ALL.disk.[available_GB | used_GB] |
指标类别:resource_utilization 执行程序的可用/已用磁盘空间。ALL 表示所有执行程序。 有效维度:JobName(Amazon Glue 作业名称)、JobRunId(JobRun ID 或 ALL)、Type(量规)和 ObservabilityGroup(resource_utilization) 有效统计信息:平均值 单位:千兆字节 |
resource_utilization |
| glue.ALL.disk.used.percentage |
指标类别:resource_utilization 执行程序的可用/已用/已用(%)磁盘空间。ALL 表示所有执行程序。 有效维度:JobName(Amazon Glue 作业名称)、JobRunId(JobRun ID 或 ALL)、Type(量规)和 ObservabilityGroup(resource_utilization) 有效统计信息:平均值 单位:百分比 |
resource_utilization |
| glue.driver.bytesRead |
指标类别:吞吐量 此作业运行中每个输入源以及所有源读取的字节数。这有助于了解数据量及其随着时间的推移而发生的变化,从而帮助解决诸如数据偏斜之类的问题。 有效维度:JobName(Amazon Glue 作业名称)、JobRunId(JobRun ID 或 ALL)、Type(量规)、ObservabilityGroup(resource_utilization)和 Source(源数据位置) 有效统计信息:平均值 单位:字节 |
吞吐量 |
| glue.driver.[recordsRead | filesRead] |
指标类别:吞吐量 此作业运行中每个输入源以及所有源读取的记录/文件数。这有助于了解数据量及其随着时间的推移而发生的变化,从而帮助解决诸如数据偏斜之类的问题。 有效维度:JobName(Amazon Glue 作业名称)、JobRunId(JobRun ID 或 ALL)、Type(量规)、ObservabilityGroup(resource_utilization)和 Source(源数据位置) 有效统计信息:平均值 单位:个 |
吞吐量 |
| glue.driver.partitionsRead |
指标类别:吞吐量 此作业运行中每个 Amazon S3 输入源以及所有源读取的分区数。 有效维度:JobName(Amazon Glue 作业名称)、JobRunId(JobRun ID 或 ALL)、Type(量规)、ObservabilityGroup(resource_utilization)和 Source(源数据位置) 有效统计信息:平均值 单位:个 |
吞吐量 |
| glue.driver.bytesWrittten |
指标类别:吞吐量 此作业运行中每个输出接收器以及所有接收器写入的字节数。这有助于了解数据量及其随着时间的推移而发生的变化,从而帮助解决诸如处理偏斜之类的问题。 有效维度:JobName(Amazon Glue 作业名称)、JobRunId(JobRun ID 或 ALL)、Type(量规)、ObservabilityGroup(resource_utilization)和 Sink(接收器数据位置) 有效统计信息:平均值 单位:字节 |
吞吐量 |
| glue.driver.[recordsWritten | filesWritten] |
指标类别:吞吐量 此作业运行中每个输出接收器以及所有接收器写入的记录/文件数。这有助于了解数据量及其随着时间的推移而发生的变化,从而帮助解决诸如处理偏斜之类的问题。 有效维度:JobName(Amazon Glue 作业名称)、JobRunId(JobRun ID 或 ALL)、Type(量规)、ObservabilityGroup(resource_utilization)和 Sink(接收器数据位置) 有效统计信息:平均值 单位:个 |
吞吐量 |
错误类别
| 错误类别 | 说明 |
|---|---|
| COMPILATION_ERROR | 编译 Scala 代码的过程中会出现错误。 |
| CONNECTION_ERROR | 连接到服务/远程主机/数据库服务等过程中会出现错误。 |
| DISK_NO_SPACE_ERROR |
当驱动程序/执行程序的磁盘中没有剩余空间时,就会出现错误。 |
| OUT_OF_MEMORY_ERROR | 当驱动程序/执行程序的内存中没有剩余空间时,就会出现错误。 |
| IMPORT_ERROR | 导入依赖项时会出现错误。 |
| INVALID_ARGUMENT_ERROR | 如果输入参数无效/非法,则会出现错误。 |
| PERMISSION_ERROR | 当缺乏服务、数据等权限时,就会出现错误。 |
| RESOURCE_NOT_FOUND_ERROR |
当数据、位置等无法退出时,就会出现错误。 |
| QUERY_ERROR | 执行 Spark SQL 查询时会出现错误。 |
| SYNTAX_ERROR | 当脚本中存在语法错误时,就会出现错误。 |
| THROTTLING_ERROR | 达到服务并发限制或超过服务限额限制时会出现错误。 |
| DATA_LAKE_FRAMEWORK_ERROR | Hudi、Iceberg 等 Amazon Glue 原生支持的数据湖框架出现错误。 |
| UNSUPPORTED_OPERATION_ERROR | 进行不支持的操作时会出现错误。 |
| RESOURCES_ALREADY_EXISTS_ERROR | 创建或添加的资源已存在时会出现错误。 |
| GLUE_INTERNAL_SERVICE_ERROR | 当出现 Amazon Glue 内部服务问题时,就会出现错误。 |
| GLUE_OPERATION_TIMEOUT_ERROR | Amazon Glue 操作超时时会出现错误。 |
| GLUE_VALIDATION_ERROR | 当无法验证 Amazon Glue 作业的所需值时,就会出现错误。 |
| GLUE_JOB_BOOKMARK_VERSION_MISMATCH_ERROR | 当同一作业外显子相同的源存储桶并同时写入相同/不同的目标时会出现错误(并发度 > 1) |
| LAUNCH_ERROR | Amazon Glue 作业启动阶段会出现错误。 |
| DYNAMODB_ERROR | 由 Amazon DynamoDB 服务引起的一般错误。 |
| GLUE_ERROR | 由 Amazon Glue 服务引起的一般错误。 |
| LAKEFORMATION_ERROR | 由 Amazon Lake Formation 服务引起的一般错误。 |
| REDSHIFT_ERROR | 由 Amazon Redshift 服务引起的一般错误。 |
| S3_ERROR | 由 Amazon S3 服务引起的一般错误。 |
| SYSTEM_EXIT_ERROR | 通用系统退出错误。 |
| TIMEOUT_ERROR | 当作业因操作超时而失败时,就会出现一般错误。 |
| UNCLASSIFIED_SPARK_ERROR | 由 Spark 引起的一般错误。 |
| UNCLASSIFIED_ERROR | 默认错误类别。 |
限制
注意
glueContext 必须初始化才能发布指标。
在源维度中,该值可以是 Amazon S3 路径或表名,具体视源类型而定。此外,如果源为 JDBC 并且使用了查询选项,则会在源维度中设置查询字符串。如果该值超过 500 个字符,则将其修剪为 500 个字符以内。以下是该值的限制:
-
将删除非 ASCII 字符。
如果源名称不包含任何 ASCII 字符,则会将其转换为 <非 ASCII 输入>。
吞吐量指标限制和注意事项
-
支持 DataFrame 和基于 DataFrame 的 DynamicFrame(例如 JDBC,在 Amazon S3 上从 parquet 读取),但不支持基于 RDD 的 DynamicFrame(例如在 Amazon S3 上读取 csv、json 等)。从技术上讲,支持 Spark UI 上显示的所有读取和写入。
-
如果数据来源为目录表且格式为 JSON、CSV、文本或 Iceberg,将发出
recordsRead指标。 -
JDBC 和 Iceberg 表中没有
glue.driver.throughput.recordsWritten、glue.driver.throughput.bytesWritten和glue.driver.throughput.filesWritten指标。 -
指标可能会延迟。如果作业在大约一分钟后完成,则 Amazon CloudWatch 指标中可能没有吞吐量指标。