调试要求苛刻的阶段和落后任务
您可以使用 Amazon Glue 作业分析来确定提取、转换和加载 (ETL) 作业中要求苛刻的阶段和落后任务。在 Amazon Glue 作业的某个阶段,落后任务比其余任务需要更长的时间。因此,该阶段需要更长的时间才能完成,这也会延迟作业的总执行时间。
将小型输入文件合并为更大的输出文件
当不同任务中的工作分配不均衡时,可能会出现落后任务,或者数据倾斜会导致一个任务处理更多数据。
您可以分析以下代码 – Apache Spark 中的一种常见模式 – 以将大量小文件合并为更大的输出文件。在本示例中,输入数据集为 32 GB 的 JSON Gzip 压缩文件。输出数据集包含大约 190 GB 的未压缩 JSON 文件。
配置的代码如下所示:
datasource0 = spark.read.format("json").load("s3://input_path") df = datasource0.coalesce(1) df.write.format("json").save(output_path)
在 Amazon Glue 控制台上可视化分析指标
您可以分析您的作业以检查四组不同的指标:
-
ETL 数据移动
-
执行程序之间的数据随机排序
-
任务执行
-
内存配置文件
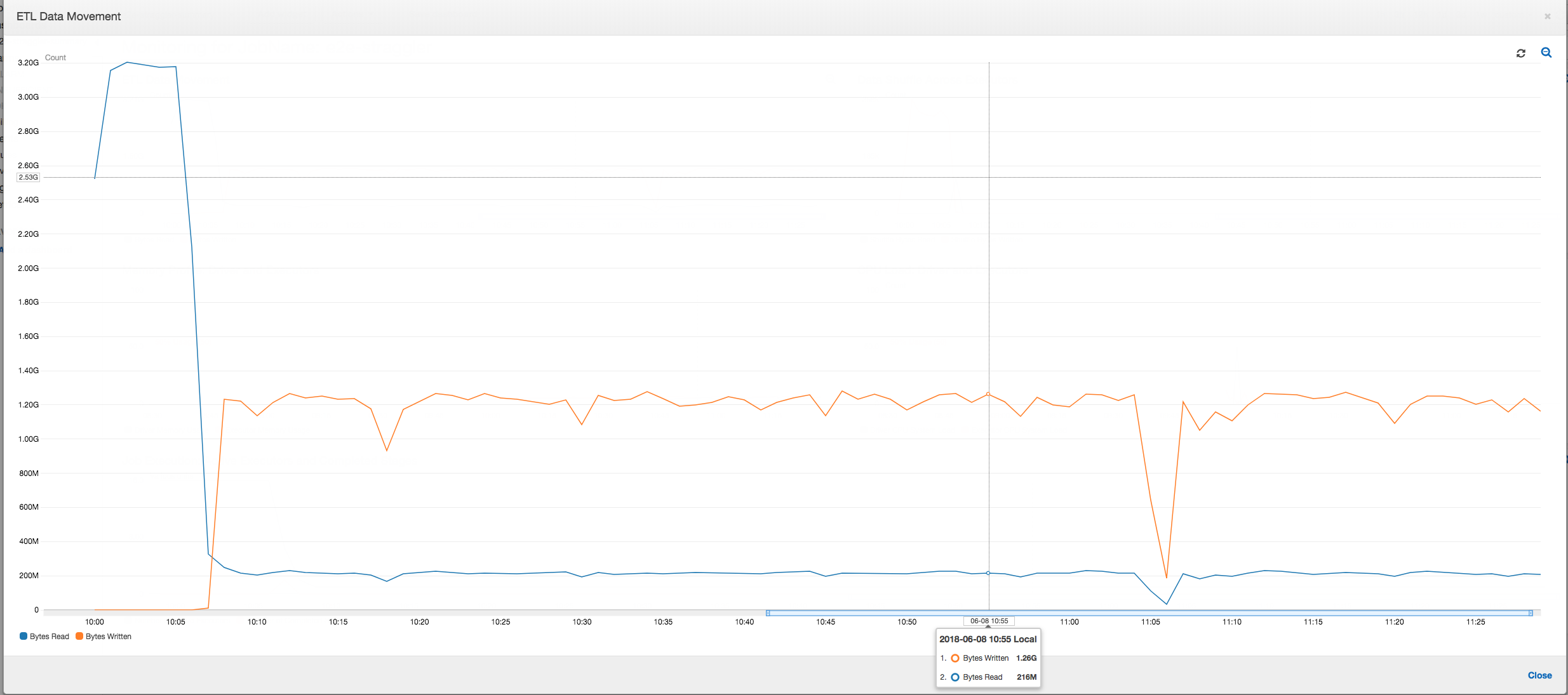
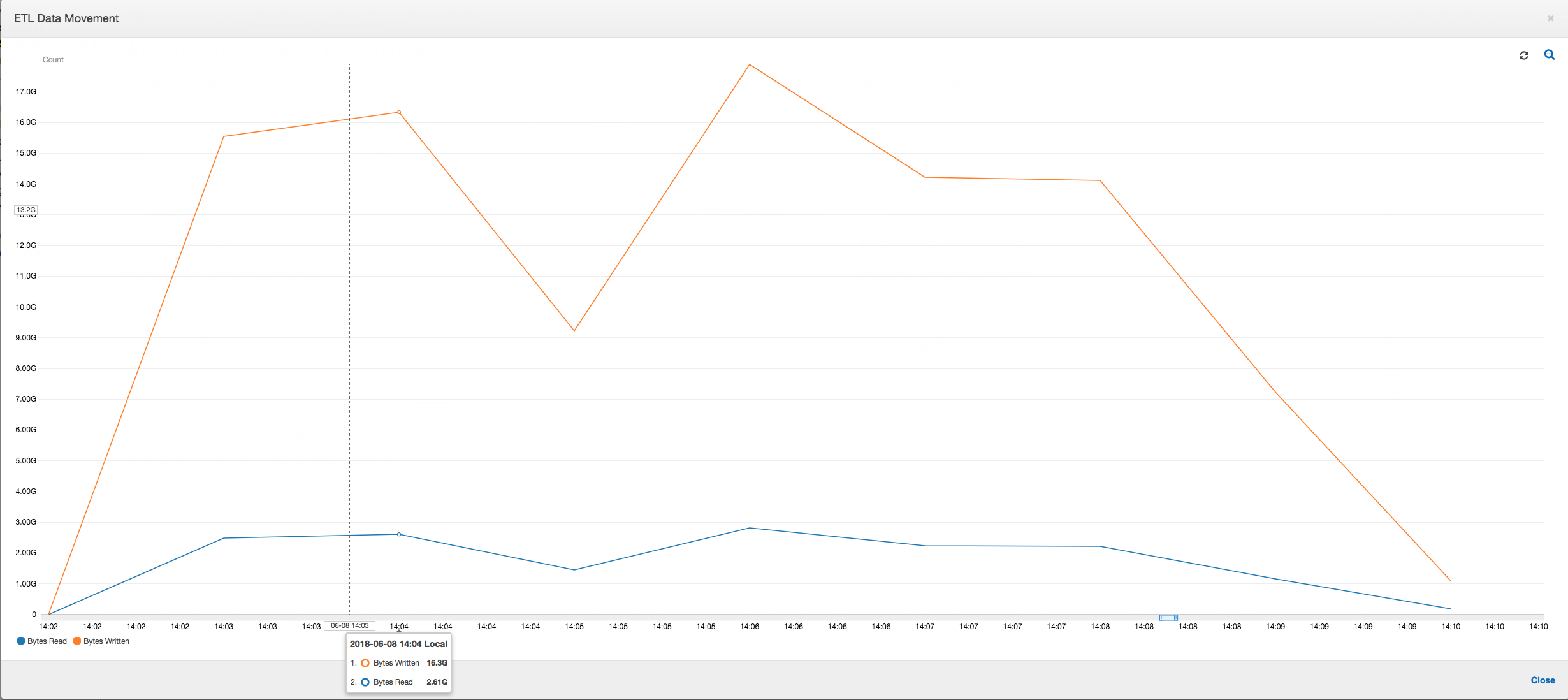
ETL 数据移动:在 ETL 数据移动配置文件中,在前六分钟内完成的第一阶段中的所有执行程序都会相当快速地读取字节。但是,总作业执行时间大约为一小时,主要由数据写入时间组成。
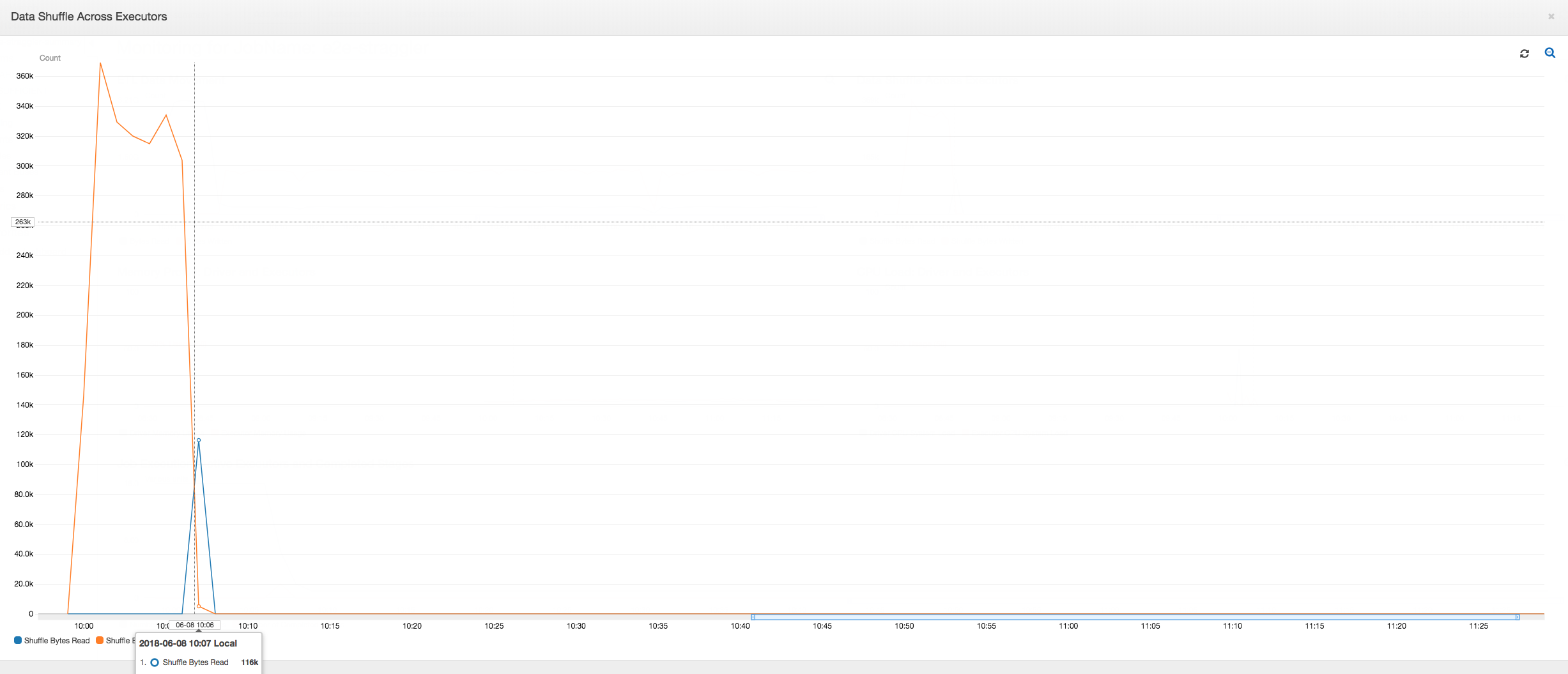
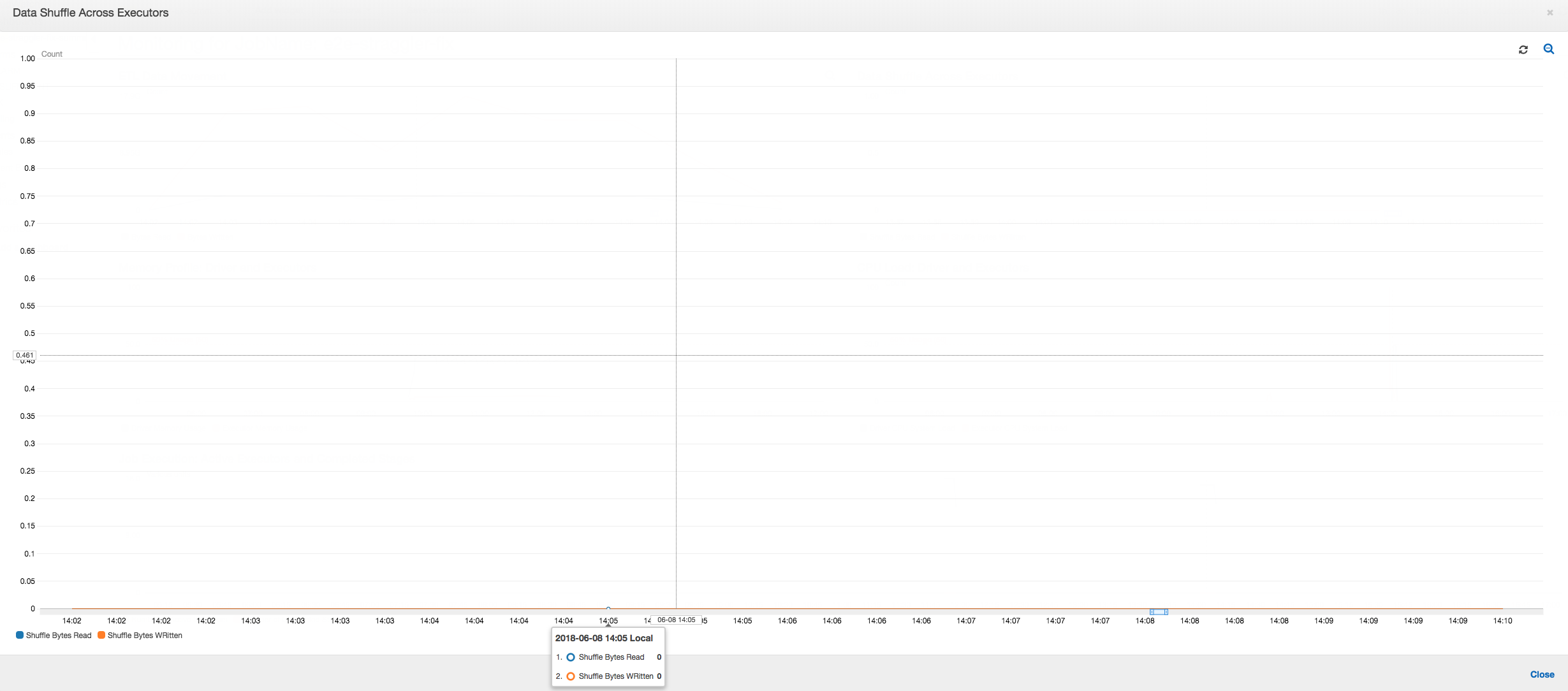
执行程序之间的数据随机排序:随机排序期间读取和写入的字节数还在阶段 2 结束之前显示一个峰值,如Job Execution (作业执行) 和Data Shuffle (数据随机排序) 指标所示。在从所有执行程序对数据进行随机排序之后,读取和写入仅从 3 号执行程序继续。
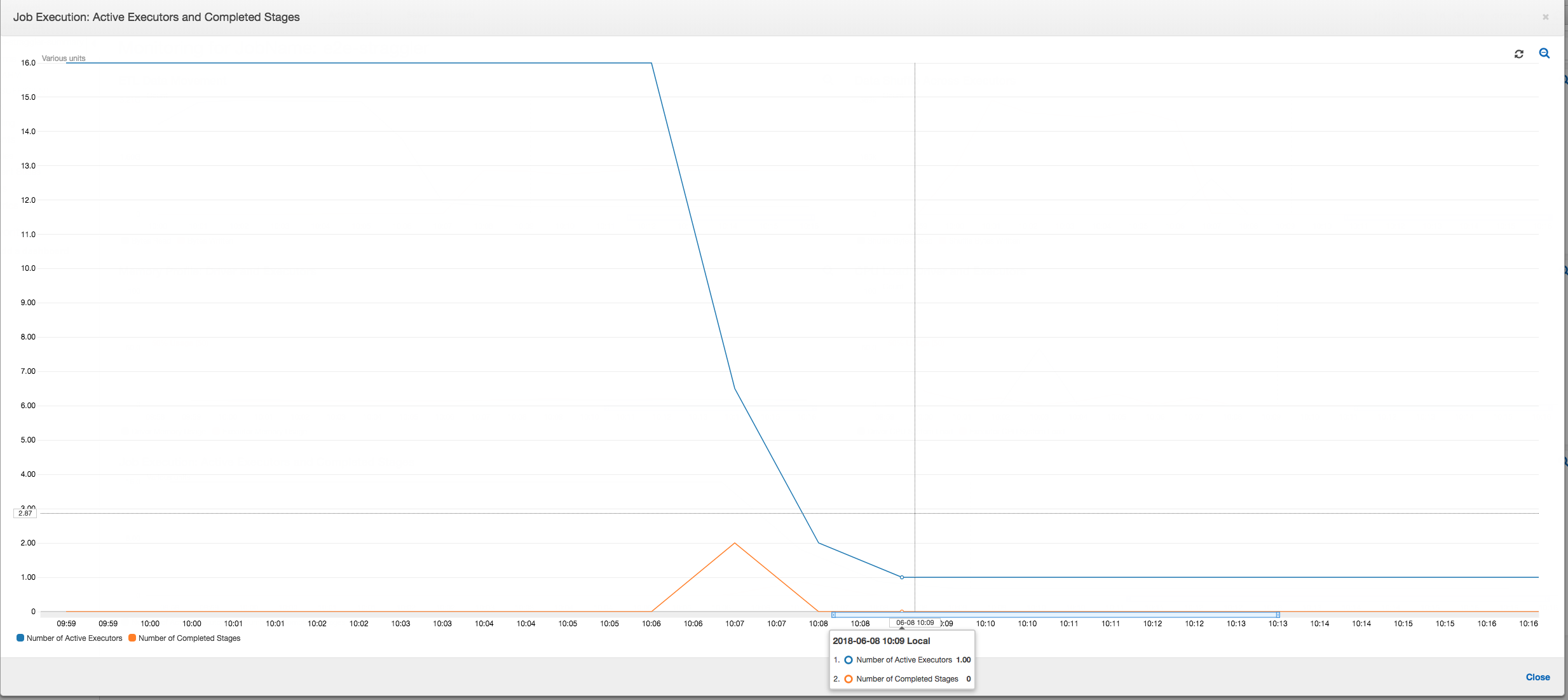
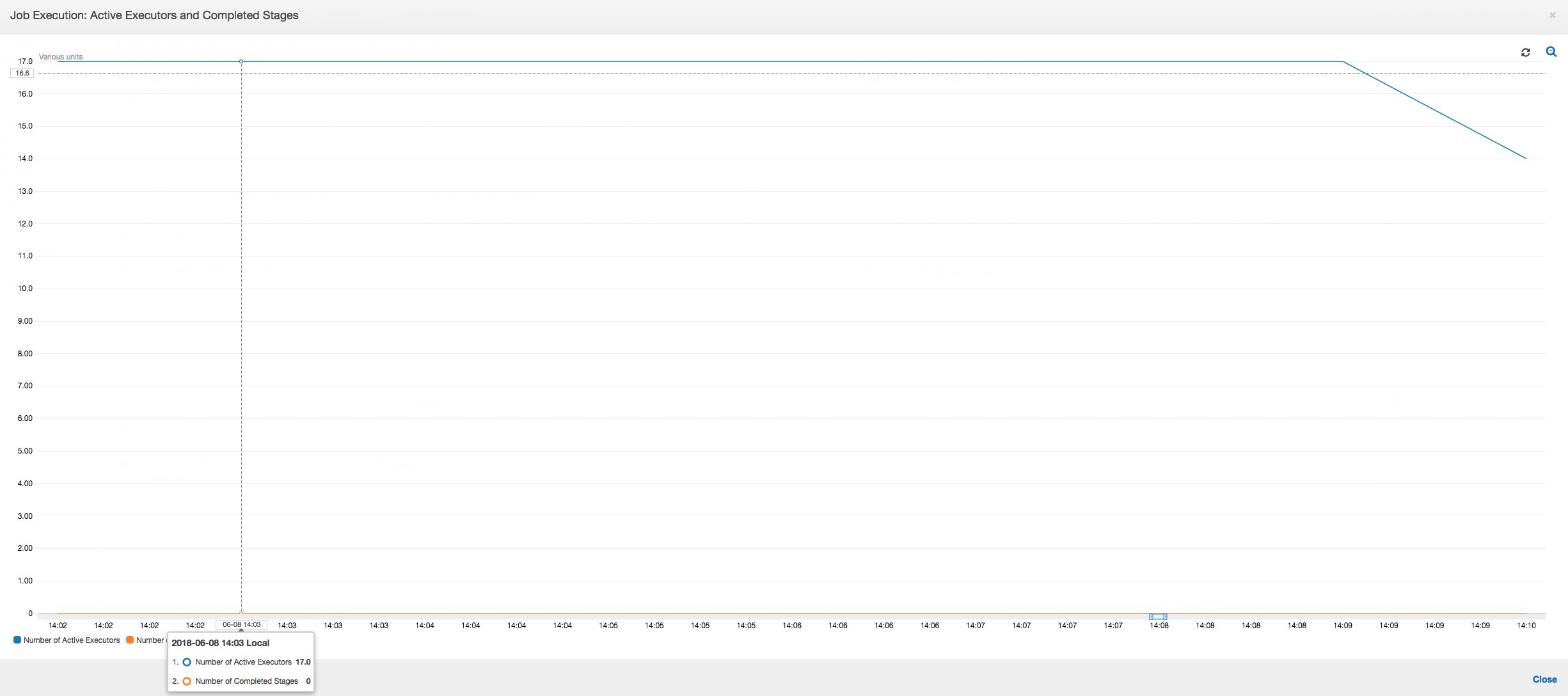
作业执行:如下图所示,所有其他执行程序均处于空闲状态,并最终在 10:09 之前被释放。此时,执行程序的总数减少到只有一个。这显然表明 3 号执行程序由执行时间最长并且占据大部分作业执行时间的落后任务组成。
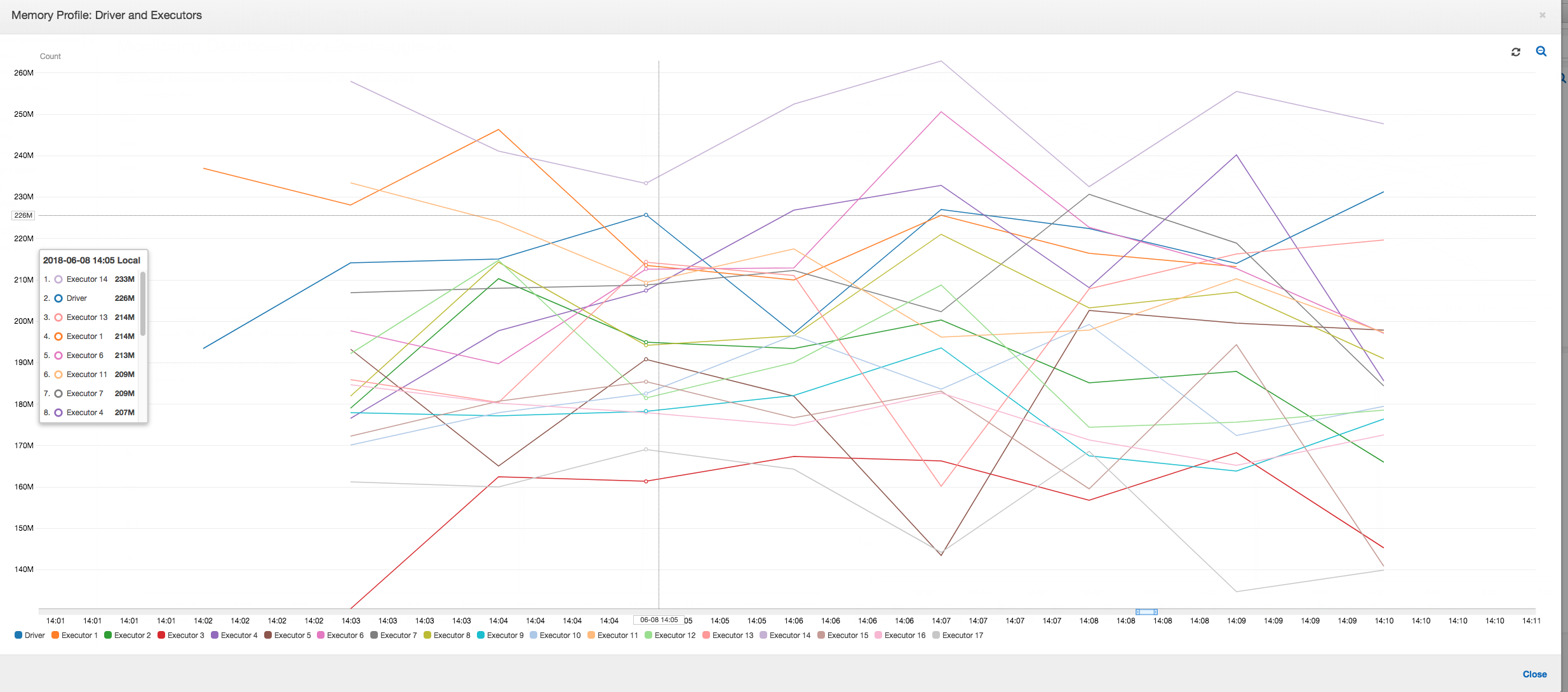
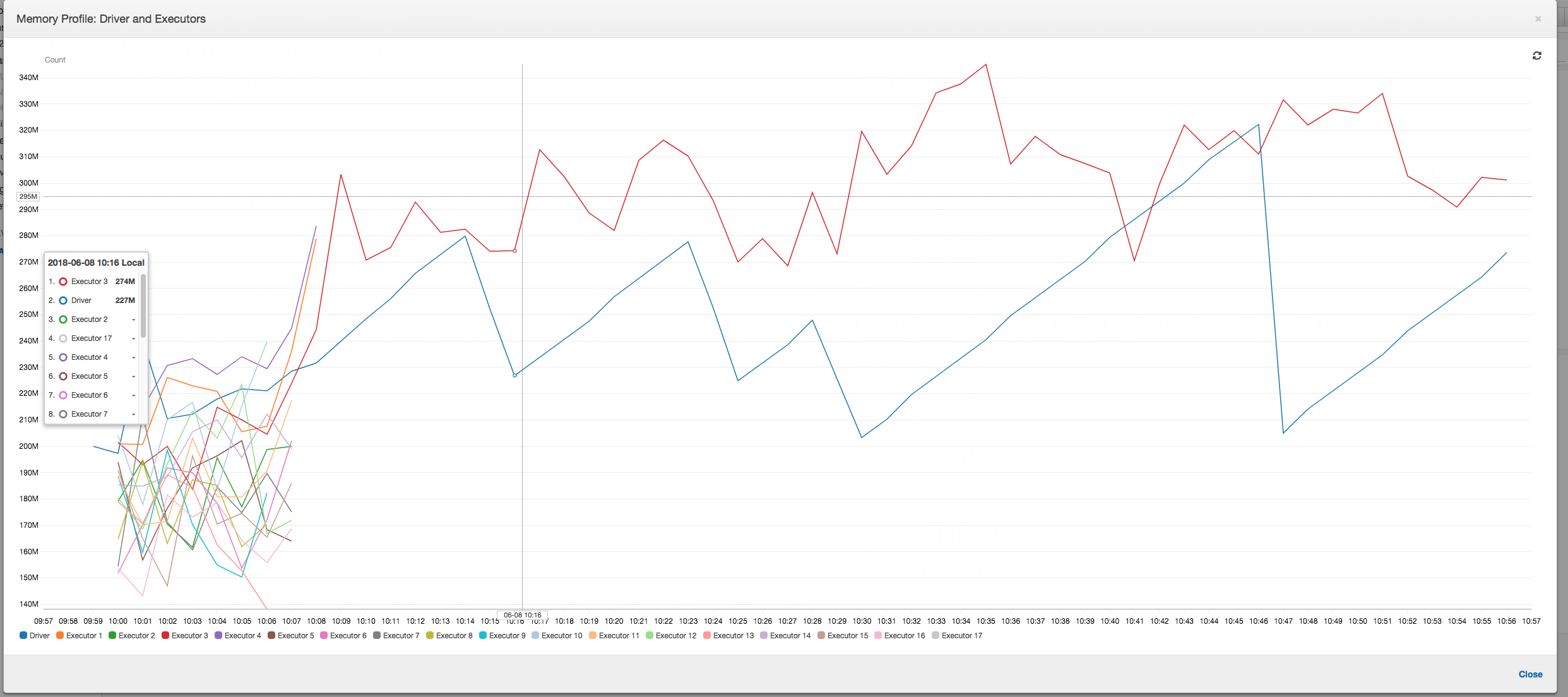
内存配置文件:在前两个阶段之后,只有 3 号执行程序在主动消耗内存来处理数据。其余执行程序只是处于空闲状态或在前两个阶段完成后很快被释放。
使用分组修复落后的执行程序
您可以通过使用 中的分组Amazon Glue功能来避免执行程序落后。使用分组在所有执行程序中均匀分配数据,并使用集群上的所有可用执行程序将文件合并为更大的文件。有关更多信息,请参阅 以较大的组读取输入文件。
要检查 Amazon Glue 作业中的 ETL 数据移动,请在启用分组的情况下配置以下代码:
df = glueContext.create_dynamic_frame_from_options("s3", {'paths': ["s3://input_path"], "recurse":True, 'groupFiles': 'inPartition'}, format="json") datasink = glueContext.write_dynamic_frame.from_options(frame = df, connection_type = "s3", connection_options = {"path": output_path}, format = "json", transformation_ctx = "datasink4")
ETL 数据移动:整个作业执行时间内的数据写入与数据读取现在并行进行流式传输。因此,任务在八分钟内完成 – 比以前快得多。
执行程序之间的数据随机排序:由于输入文件在读取期间使用分组功能进行了合并,因此在读取数据后不会进行代价高昂的数据随机排序。
作业执行:作业执行指标显示运行和处理数据的活动执行程序总数保持恒定。作业中没有单个落后者。所有执行程序均处于活动状态,在完成作业之前不会被释放。由于执行程序中没有数据的中间随机排序情况,因此作业中只有一个阶段。
内存配置文件:相关指标显示所有执行程序的活动内存消耗 – 跨所有执行程序重新确认存在活动。随着数据并行流入和写出,所有执行程序的总内存占用空间大致均匀,远低于所有执行程序的安全阈值。