存储 Spark 随机排序数据
每当数据在分区之间重新排列时,随机排序是 Spark 任务中的一个重要步骤。这是必需的,因为 join、
groupByKey、reduceByKey 和 repartition 等广泛的转换需要来自其他分区的信息才能完成处理。Spark 从每个分区收集所需的数据,并将其合并到一个新的分区中。在随机排序过程中,数据会写入磁盘并通过网络传输。因此,随机排序操作绑定到本地磁盘容量。当执行程序上没有足够的磁盘空间并且没有恢复时,Spark 会抛出一个 No space left on device 或
MetadataFetchFailedException 错误。
注意
Amazon S3 中的 Amazon Glue Spark Shuffle Plugin 仅支持 Amazon Glue ETL 作业。
解决方案
通过 Amazon Glue,您现在可以使用 Amazon S3 存储 Spark Shuffle 数据。Amazon S3 是一种对象存储服务,提供行业领先的可扩展性、数据可用性、安全性和性能。此解决方案可分解 Spark 任务的计算和存储,并提供完整的弹性和低成本的随机排序存储,使您能够可靠地运行随机排序最密集的工作负载。
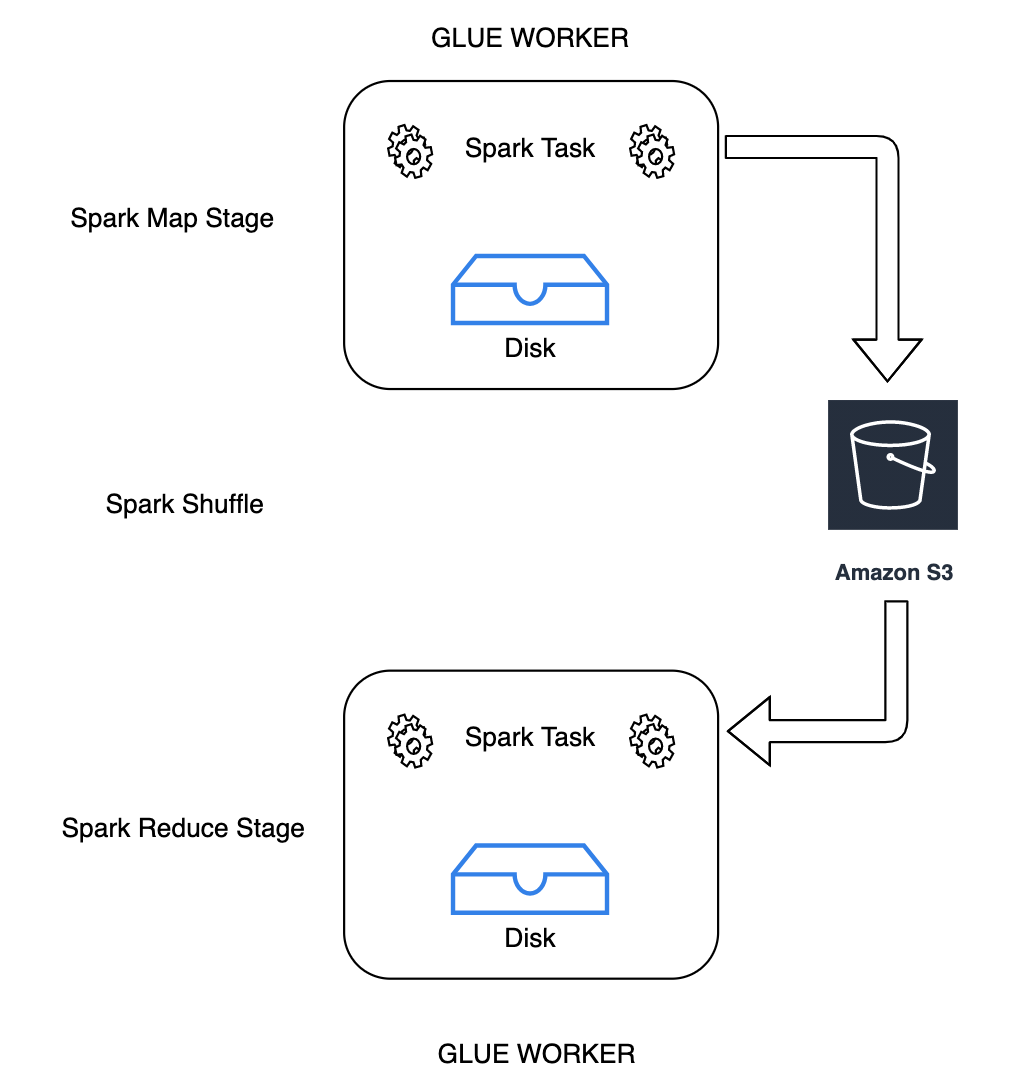
我们即将推出适用于 Apache Spark 的 Cloud Shuffle Storage 插件,以使用 Amazon S3。如果已知任务受大规模随机排序操作的本地磁盘容量限制,则可以启用 Amazon S3 随机排序来可靠、无故障地运行 Amazon Glue 任务。在某些情况下,如果您有大量的小分区或随机排序文件写入 Amazon S3,则随机排序到 Amazon S3 的速度比本地磁盘(或 EBS)慢一些。
使用 Cloud Shuffle Storage Plugin 的先决条件
要将 Cloud Shuffle Storage Plugin 用于 Amazon Glue ETL 作业,需要满足以下条件:
-
与您的作业运行位于同一区域的 Amazon S3 存储桶,用于存储随机排序和溢出的数据。可使用
--conf spark.shuffle.glue.s3ShuffleBucket=s3://指定随机排序存储的 Amazon S3 前缀,如以下示例所示:shuffle-bucket/prefix/--conf spark.shuffle.glue.s3ShuffleBucket=s3://glue-shuffle-123456789-us-east-1/glue-shuffle-data/ -
在前缀上设置 Amazon S3 存储生命周期策略(例如
glue-shuffle-data),因为作业完成后,随机排序管理器不会清理文件。作业完成后,应删除中间随机排序和溢出的数据。用户可以在前缀上设置短生命周期策略。有关设置 Amazon S3 生命周期策略的说明,请参阅《 Amazon Simple Storage Service 用户指南》中的 Setting lifecycle configuration on a bucket。
从 Amazon 控制台使用 Amazon Glue Spark 随机排序管理器
在配置作业时使用 Amazon Glue 控制台或 Amazon Glue Studio 设置 Amazon Glue Spark 随机排序管理器:选择 --write-shuffle-files-to-s3 作业参数启用作业的 Amazon S3 随机排序。
使用 Amazon Glue Spark Shuffle 插件
以下任务参数启用并调整 Amazon Glue 随机排序管理器。这些参数是标志,因此不考虑所提供的任何值。
-
--write-shuffle-files-to-s3– 主标志,启用 Amazon Glue Spark 随机排序管理器,以使用 Amazon S3 存储桶写入和读取随机排序数据。如果标志未指定,则不使用随机排序管理器。 -
--write-shuffle-spills-to-s3—(仅在 Amazon Glue 版本 2.0 上支持)。一个可选标志,允许您将溢出文件卸载到 Amazon S3 存储桶,从而为您的 Spark 作业提供额外的弹性。只有将大量数据溢出到磁盘的大型工作负载才需要这样做。如果未指定该标志,则不会写入任何中间溢出文件。 -
--conf spark.shuffle.glue.s3ShuffleBucket=s3://<shuffle-bucket>– 另一个可选标志,用于指定您在其中写入随机排序文件的 Amazon S3 存储桶。默认情况下,--TempDir/shuffle-data. Amazon Glue 3.0+ 支持通过使用逗号分隔符指定存储桶,将随机排序文件写入多个存储桶,如--conf spark.shuffle.glue.s3ShuffleBucket=s3://中所示。使用多个存储桶可以提高性能。shuffle-bucket-1/prefix,s3://shuffle-bucket-2/prefix/
您需要提供安全配置设置,才能对随机排序数据启用静态加密。有关安全配置的更多信息,请参阅 在 Amazon Glue 中设置加密。Amazon Glue 支持 Spark 提供的所有其他随机排序相关配置。
Cloud Shuffle Storage 插件的软件二进制文件
您还可以在 Apache 2.0 许可证下下载适用于 Apache Spark 的 Cloud Shuffle Storage 插件的软件二进制文件,然后在任何 Spark 环境中运行它。新插件对 Amazon S3 提供开箱即用支持,也可以轻松配置为使用其他形式的云存储,例如 Google Cloud Storage 和 Microsoft Azure Blob Storage
注释和限制
以下是 Amazon Glue 随机排序管理器的注释或限制:
-
作业完成后,Amazon Glue 随机排序管理器不会自动删除存储在 Amazon S3 存储桶中的(临时)随机排序数据文件。为确保数据保护,请在启用 Cloud Shuffle Storage Plugin 之前按照 使用 Cloud Shuffle Storage Plugin 的先决条件 中的说明进行操作。
-
如果数据出现误差,则可以使用此功能。