使用 Apache Spark Web UI 监控作业
可以使用 Apache Spark Web UI 监控和调试在 Amazon Glue 作业系统上运行的 Amazon Glue ETL 作业以及在 Amazon Glue 开发终端节点上运行的 Spark 应用程序。可使用 Spark UI 检查每个作业的以下内容:
-
每个 Spark 阶段的事件时间表
-
作业的有向非循环图 (DAG)
-
SparkSQL 查询的物理和逻辑计划
-
每个作业的基础 Spark 环境变量
有关使用 Spark Web UI 的更多信息,请参阅 Spark 文档中的 Web UI
您可以在 Amazon Glue 控制台中查看 Spark UI。当 Amazon Glue 任务在 Amazon Glue 3.0 或更高版本上运行,并且日志以标准(而不是传统)格式(对于较新的任务,默认格式为标准)生成时,可以使用此功能。如果您的日志文件大于 0.5 GB,则可以为在 Amazon Glue 4.0 或更高版本上运行的任务启用滚动日志支持,以此简化日志存档、分析和故障排除。
您可以使用 Amazon Glue 控制台或 Amazon Command Line Interface (Amazon CLI) 启用 Spark UI。在启用 Spark UI 后,Amazon Glue 开发端点上的 Amazon Glue ETL 任务和 Spark 应用程序可将 Spark 事件日志备份到您在 Amazon Simple Storage Service (Amazon S3) 中指定的位置。您可以将 Amazon S3 中备份的事件日志与 Spark UI 一起使用,既可以在任务运行时实时使用,也可以在任务完成后使用。日志保留在 Amazon S3 中时,Amazon Glue 控制台中的 Spark UI 可以查看它们。
权限
要在 Amazon Glue 控制台中使用 Spark UI,您可以使用 UseGlueStudio 或分别添加所有单独的服务 API。需要所有 API 才能完全使用 Spark UI,不过用户可以通过在其 IAM 权限中添加相关服务 API 来访问相应的 SparkUI 功能,从而实现精细访问控制。
RequestLogParsing 负责执行日志解析,因此最为关键。其余的 API 用于读取相应的解析数据。例如,GetStages 将提供对 Spark 作业所有阶段数据的访问权限。
在示例策略中,映射到 UseGlueStudio 的 Spark UI 服务 API 列表如下。以下策略仅提供使用 Spark UI 功能的权限。要添加其他权限(例如 Amazon S3 和 IAM),请参阅 Creating Custom IAM Policies for Amazon Glue Studio。
在示例策略中,映射到 UseGlueStudio 的 Spark UI 服务 API 列表如下。使用 Spark UI 服务 API 时,请使用以下命名空间:glue:<ServiceAPI>。
限制
-
Amazon Glue 控制台中的 Spark UI 不适用于 2023 年 11 月 20 日之前的任务运行,因为此类任务采用旧版日志格式。
-
Amazon Glue 控制台中的 Spark UI 支持为 Amazon Glue 4.0 启用滚动日志,例如流式处理任务中默认生成的日志。所有生成的滚动日志事件文件的最大总和为 2 GB。对于不支持滚动日志的 Amazon Glue 任务,SparkUI 支持的日志事件文件最大大小为 0.5 GB。
-
如果 Spark 事件日志存储在只能由您的 VPC 访问的 Amazon S3 存储桶中,则无服务器 Spark UI 不适用于此类日志。
示例:Apache Spark Web UI
此示例演示了如何使用 Spark UI 了解任务性能。屏幕截图显示了由自行管理的 Spark 历史记录服务器提供的 Spark Web UI。Amazon Glue 控制台中的 Spark UI 提供了类似视图。有关使用 Spark Web UI 的更多信息,请参阅 Spark 文档中的 Web UI
以下是一个示例 Spark 应用程序,其从两个数据源读取数据,执行联接转换,并以 Parquet 格式将其写入 Amazon S3。
import sys from awsglue.transforms import * from awsglue.utils import getResolvedOptions from pyspark.context import SparkContext from awsglue.context import GlueContext from awsglue.job import Job from pyspark.sql.functions import count, when, expr, col, sum, isnull from pyspark.sql.functions import countDistinct from awsglue.dynamicframe import DynamicFrame args = getResolvedOptions(sys.argv, ['JOB_NAME']) sc = SparkContext() glueContext = GlueContext(sc) spark = glueContext.spark_session job = Job(glueContext) job.init(args['JOB_NAME']) df_persons = spark.read.json("s3://awsglue-datasets/examples/us-legislators/all/persons.json") df_memberships = spark.read.json("s3://awsglue-datasets/examples/us-legislators/all/memberships.json") df_joined = df_persons.join(df_memberships, df_persons.id == df_memberships.person_id, 'fullouter') df_joined.write.parquet("s3://aws-glue-demo-sparkui/output/") job.commit()
以下 DAG 可视化显示此 Spark 作业中的各个阶段。
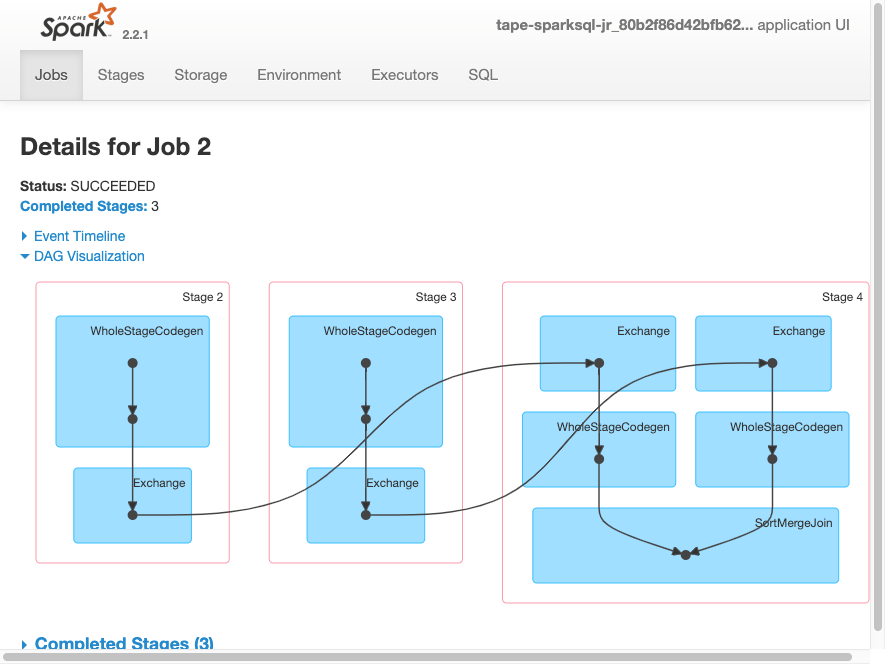
以下作业事件时间表显示了各个 Spark 执行程序的启动、执行和终止。

以下屏幕显示了 SparkSQL 查询计划的详细信息:
-
已解析的逻辑计划
-
已分析的逻辑计划
-
已优化的逻辑计划
-
执行的物理计划
