与 Amazon Glue 架构注册表集成
这些章节介绍了与 Amazon Glue 架构注册表集成的相关知识。本部分中的示例显示了具有 AVRO 数据格式的架构。有关更多示例(包括具有 JSON 数据格式的架构),请参阅 Amazon Glue 架构注册表开源存储库
主题
使用案例:将架构注册表连接到 Amazon MSK 或 Apache Kafka
假设您正在向 Apache Kafka 主题写入数据,您可以按照以下步骤操作。
创建 Amazon Managed Streaming for Apache Kafka(Amazon MSK)或 Apache Kafka 集群,至少具有一个主题。如果创建 Amazon MSK 集群,您可以使用 Amazon Web Services 管理控制台。遵循以下说明:请参阅《Amazon Managed Streaming for Apache Kafka 开发人员指南》中的开始使用 Amazon MSK。
遵循上面的安装 SerDe 库步骤。
要创建架构注册表、架构或架构版本,请按照本文档架构注册表入门部分下面的说明操作。
启动您的创建器和使用器,使用架构注册表将记录写入 Amazon MSK 或 Apache Kafka,或者从其中读取记录。您可从 Serde 库的自述文件
中找到示例创建器和使用器代码。创建器上的架构注册表库将自动序列化记录,并使用架构版本 ID 装饰记录。 如果已输入此记录的架构,或者启用了自动注册,则该架构将已在架构注册表中注册。
如果使用器从 Amazon MSK 或 Apache Kafka 主题读取数据,使用 Amazon Glue 架构注册表库,则该使用器将自动从架构注册表中查找架构。
使用案例:将 Amazon Kinesis Data Streams 与 Amazon Glue 架构注册表集成
此集成要求您拥有现有 Amazon Kinesis 数据流。有关更多信息,请参阅《Amazon Kinesis Data Streams 开发人员指南》中的 Amazon Kinesis Data Streams 入门。
您可以通过两种方式与 Kinesis 数据流中的数据进行交互。
通过 Java 中的 Kinesis Producer Library(KPL)和 Kinesis Client Library(KCL)库。不提供多语言支持。
通过 适用于 Java 的 Amazon SDK 中的
PutRecords、PutRecord和GetRecordsKinesis Data Streams API。
如果您当前使用的是 KPL/KCL 库,我们建议您继续使用该方法。有更新的 KCL 和 KPL 版本集成了架构注册表,如示例所示。否则,您可以使用示例代码来利用 Amazon Glue 架构注册表(如果直接使用 KDS API)。
架构注册表集成仅适用于 KPL v0.14.2 或更高版本以及 KCL v2.3 或更高版本。架构注册表与 JSON 数据格式的集成仅适用于 KPL v0.14.8 或更高版本以及 KCL v2.3.6 或更高版本。
使用 Kinesis SDK V2 与数据进行交互
本部分介绍如何使用 Kinesis SDK V2 与 Kinesis 进行交互
// Example JSON Record, you can construct a AVRO record also private static final JsonDataWithSchema record = JsonDataWithSchema.builder(schemaString, payloadString); private static final DataFormat dataFormat = DataFormat.JSON; //Configurations for Schema Registry GlueSchemaRegistryConfiguration gsrConfig = new GlueSchemaRegistryConfiguration("us-east-1"); GlueSchemaRegistrySerializer glueSchemaRegistrySerializer = new GlueSchemaRegistrySerializerImpl(awsCredentialsProvider, gsrConfig); GlueSchemaRegistryDataFormatSerializer dataFormatSerializer = new GlueSchemaRegistrySerializerFactory().getInstance(dataFormat, gsrConfig); Schema gsrSchema = new Schema(dataFormatSerializer.getSchemaDefinition(record), dataFormat.name(), "MySchema"); byte[] serializedBytes = dataFormatSerializer.serialize(record); byte[] gsrEncodedBytes = glueSchemaRegistrySerializer.encode(streamName, gsrSchema, serializedBytes); PutRecordRequest putRecordRequest = PutRecordRequest.builder() .streamName(streamName) .partitionKey("partitionKey") .data(SdkBytes.fromByteArray(gsrEncodedBytes)) .build(); shardId = kinesisClient.putRecord(putRecordRequest) .get() .shardId(); GlueSchemaRegistryDeserializer glueSchemaRegistryDeserializer = new GlueSchemaRegistryDeserializerImpl(awsCredentialsProvider, gsrConfig); GlueSchemaRegistryDataFormatDeserializer gsrDataFormatDeserializer = glueSchemaRegistryDeserializerFactory.getInstance(dataFormat, gsrConfig); GetShardIteratorRequest getShardIteratorRequest = GetShardIteratorRequest.builder() .streamName(streamName) .shardId(shardId) .shardIteratorType(ShardIteratorType.TRIM_HORIZON) .build(); String shardIterator = kinesisClient.getShardIterator(getShardIteratorRequest) .get() .shardIterator(); GetRecordsRequest getRecordRequest = GetRecordsRequest.builder() .shardIterator(shardIterator) .build(); GetRecordsResponse recordsResponse = kinesisClient.getRecords(getRecordRequest) .get(); List<Object> consumerRecords = new ArrayList<>(); List<Record> recordsFromKinesis = recordsResponse.records(); for (int i = 0; i < recordsFromKinesis.size(); i++) { byte[] consumedBytes = recordsFromKinesis.get(i) .data() .asByteArray(); Schema gsrSchema = glueSchemaRegistryDeserializer.getSchema(consumedBytes); Object decodedRecord = gsrDataFormatDeserializer.deserialize(ByteBuffer.wrap(consumedBytes), gsrSchema.getSchemaDefinition()); consumerRecords.add(decodedRecord); }
使用 KPL/KCL 库与数据进行交互
本部分介绍如何使用 KPL/KCL 库将 Kinesis Data Streams 与架构注册表集成。有关 KPL/KCL 使用的更多信息,请参阅《Amazon Kinesis Data Streams 开发人员指南》中的 使用 Amazon Kinesis Producer Library 开发创建器。
在 KPL 中设置架构注册表
定义 Amazon Glue 架构注册表中编写的数据、数据格式和架构名称的架构定义。
(可选)配置
GlueSchemaRegistryConfiguration对象。将架构对象传递到
addUserRecord API。private static final String SCHEMA_DEFINITION = "{"namespace": "example.avro",\n" + " "type": "record",\n" + " "name": "User",\n" + " "fields": [\n" + " {"name": "name", "type": "string"},\n" + " {"name": "favorite_number", "type": ["int", "null"]},\n" + " {"name": "favorite_color", "type": ["string", "null"]}\n" + " ]\n" + "}"; KinesisProducerConfiguration config = new KinesisProducerConfiguration(); config.setRegion("us-west-1") //[Optional] configuration for Schema Registry. GlueSchemaRegistryConfiguration schemaRegistryConfig = new GlueSchemaRegistryConfiguration("us-west-1"); schemaRegistryConfig.setCompression(true); config.setGlueSchemaRegistryConfiguration(schemaRegistryConfig); ///Optional configuration ends. final KinesisProducer producer = new KinesisProducer(config); final ByteBuffer data = getDataToSend(); com.amazonaws.services.schemaregistry.common.Schema gsrSchema = new Schema(SCHEMA_DEFINITION, DataFormat.AVRO.toString(), "demoSchema"); ListenableFuture<UserRecordResult> f = producer.addUserRecord( config.getStreamName(), TIMESTAMP, Utils.randomExplicitHashKey(), data, gsrSchema); private static ByteBuffer getDataToSend() { org.apache.avro.Schema avroSchema = new org.apache.avro.Schema.Parser().parse(SCHEMA_DEFINITION); GenericRecord user = new GenericData.Record(avroSchema); user.put("name", "Emily"); user.put("favorite_number", 32); user.put("favorite_color", "green"); ByteArrayOutputStream outBytes = new ByteArrayOutputStream(); Encoder encoder = EncoderFactory.get().directBinaryEncoder(outBytes, null); new GenericDatumWriter<>(avroSchema).write(user, encoder); encoder.flush(); return ByteBuffer.wrap(outBytes.toByteArray()); }
设置 Kinesis 客户端库
您将在 Java 中开发 Kinesis Client Library 使用器 有关更多信息,请参阅《Amazon Kinesis Data Streams 开发人员指南》中的 在 Java 中开发 Kinesis Client Library 使用器。
传递
GlueSchemaRegistryConfiguration对象以创建GlueSchemaRegistryDeserializer的实例。将
GlueSchemaRegistryDeserializer传递到retrievalConfig.glueSchemaRegistryDeserializer。调用
kinesisClientRecord.getSchema(),访问传入消息的架构。GlueSchemaRegistryConfiguration schemaRegistryConfig = new GlueSchemaRegistryConfiguration(this.region.toString()); GlueSchemaRegistryDeserializer glueSchemaRegistryDeserializer = new GlueSchemaRegistryDeserializerImpl(DefaultCredentialsProvider.builder().build(), schemaRegistryConfig); RetrievalConfig retrievalConfig = configsBuilder.retrievalConfig().retrievalSpecificConfig(new PollingConfig(streamName, kinesisClient)); retrievalConfig.glueSchemaRegistryDeserializer(glueSchemaRegistryDeserializer); Scheduler scheduler = new Scheduler( configsBuilder.checkpointConfig(), configsBuilder.coordinatorConfig(), configsBuilder.leaseManagementConfig(), configsBuilder.lifecycleConfig(), configsBuilder.metricsConfig(), configsBuilder.processorConfig(), retrievalConfig ); public void processRecords(ProcessRecordsInput processRecordsInput) { MDC.put(SHARD_ID_MDC_KEY, shardId); try { log.info("Processing {} record(s)", processRecordsInput.records().size()); processRecordsInput.records() .forEach( r -> log.info("Processed record pk: {} -- Seq: {} : data {} with schema: {}", r.partitionKey(), r.sequenceNumber(), recordToAvroObj(r).toString(), r.getSchema())); } catch (Throwable t) { log.error("Caught throwable while processing records. Aborting."); Runtime.getRuntime().halt(1); } finally { MDC.remove(SHARD_ID_MDC_KEY); } } private GenericRecord recordToAvroObj(KinesisClientRecord r) { byte[] data = new byte[r.data().remaining()]; r.data().get(data, 0, data.length); org.apache.avro.Schema schema = new org.apache.avro.Schema.Parser().parse(r.schema().getSchemaDefinition()); DatumReader datumReader = new GenericDatumReader<>(schema); BinaryDecoder binaryDecoder = DecoderFactory.get().binaryDecoder(data, 0, data.length, null); return (GenericRecord) datumReader.read(null, binaryDecoder); }
使用 Kinesis Data Streams API 与数据交互
本部分介绍如何使用 Kinesis Data Streams API 将 Kinesis Data Streams 与架构注册表集成。
更新这些 Maven 依赖关系:
<dependencyManagement> <dependencies> <dependency> <groupId>com.amazonaws</groupId> <artifactId>aws-java-sdk-bom</artifactId> <version>1.11.884</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement> <dependencies> <dependency> <groupId>com.amazonaws</groupId> <artifactId>aws-java-sdk-kinesis</artifactId> </dependency> <dependency> <groupId>software.amazon.glue</groupId> <artifactId>schema-registry-serde</artifactId> <version>1.1.5</version> </dependency> <dependency> <groupId>com.fasterxml.jackson.dataformat</groupId> <artifactId>jackson-dataformat-cbor</artifactId> <version>2.11.3</version> </dependency> </dependencies>在创建器中,使用 Kinesis Data Streams 中的
PutRecords或者PutRecordAPI 添加架构标头信息。//The following lines add a Schema Header to the record com.amazonaws.services.schemaregistry.common.Schema awsSchema = new com.amazonaws.services.schemaregistry.common.Schema(schemaDefinition, DataFormat.AVRO.name(), schemaName); GlueSchemaRegistrySerializerImpl glueSchemaRegistrySerializer = new GlueSchemaRegistrySerializerImpl(DefaultCredentialsProvider.builder().build(), new GlueSchemaRegistryConfiguration(getConfigs())); byte[] recordWithSchemaHeader = glueSchemaRegistrySerializer.encode(streamName, awsSchema, recordAsBytes);在创建器中,使用
PutRecords或者PutRecordAPI 将记录放入数据流。在使用器中,从标头中删除架构记录,然后序列化 Avro 架构记录。
//The following lines remove Schema Header from record GlueSchemaRegistryDeserializerImpl glueSchemaRegistryDeserializer = new GlueSchemaRegistryDeserializerImpl(DefaultCredentialsProvider.builder().build(), getConfigs()); byte[] recordWithSchemaHeaderBytes = new byte[recordWithSchemaHeader.remaining()]; recordWithSchemaHeader.get(recordWithSchemaHeaderBytes, 0, recordWithSchemaHeaderBytes.length); com.amazonaws.services.schemaregistry.common.Schema awsSchema = glueSchemaRegistryDeserializer.getSchema(recordWithSchemaHeaderBytes); byte[] record = glueSchemaRegistryDeserializer.getData(recordWithSchemaHeaderBytes); //The following lines serialize an AVRO schema record if (DataFormat.AVRO.name().equals(awsSchema.getDataFormat())) { Schema avroSchema = new org.apache.avro.Schema.Parser().parse(awsSchema.getSchemaDefinition()); Object genericRecord = convertBytesToRecord(avroSchema, record); System.out.println(genericRecord); }
使用 Kinesis Data Streams API 与数据交互
以下是使用 PutRecords 和 GetRecords API 的示例代码。
//Full sample code import com.amazonaws.services.schemaregistry.deserializers.GlueSchemaRegistryDeserializerImpl; import com.amazonaws.services.schemaregistry.serializers.GlueSchemaRegistrySerializerImpl; import com.amazonaws.services.schemaregistry.utils.AVROUtils; import com.amazonaws.services.schemaregistry.utils.AWSSchemaRegistryConstants; import org.apache.avro.Schema; import org.apache.avro.generic.GenericData; import org.apache.avro.generic.GenericDatumReader; import org.apache.avro.generic.GenericDatumWriter; import org.apache.avro.generic.GenericRecord; import org.apache.avro.io.Decoder; import org.apache.avro.io.DecoderFactory; import org.apache.avro.io.Encoder; import org.apache.avro.io.EncoderFactory; import software.amazon.awssdk.auth.credentials.DefaultCredentialsProvider; import software.amazon.awssdk.services.glue.model.DataFormat; import java.io.ByteArrayOutputStream; import java.io.File; import java.io.IOException; import java.nio.ByteBuffer; import java.util.Collections; import java.util.HashMap; import java.util.Map; public class PutAndGetExampleWithEncodedData { static final String regionName = "us-east-2"; static final String streamName = "testStream1"; static final String schemaName = "User-Topic"; static final String AVRO_USER_SCHEMA_FILE = "src/main/resources/user.avsc"; KinesisApi kinesisApi = new KinesisApi(); void runSampleForPutRecord() throws IOException { Object testRecord = getTestRecord(); byte[] recordAsBytes = convertRecordToBytes(testRecord); String schemaDefinition = AVROUtils.getInstance().getSchemaDefinition(testRecord); //The following lines add a Schema Header to a record com.amazonaws.services.schemaregistry.common.Schema awsSchema = new com.amazonaws.services.schemaregistry.common.Schema(schemaDefinition, DataFormat.AVRO.name(), schemaName); GlueSchemaRegistrySerializerImpl glueSchemaRegistrySerializer = new GlueSchemaRegistrySerializerImpl(DefaultCredentialsProvider.builder().build(), new GlueSchemaRegistryConfiguration(regionName)); byte[] recordWithSchemaHeader = glueSchemaRegistrySerializer.encode(streamName, awsSchema, recordAsBytes); //Use PutRecords api to pass a list of records kinesisApi.putRecords(Collections.singletonList(recordWithSchemaHeader), streamName, regionName); //OR //Use PutRecord api to pass single record //kinesisApi.putRecord(recordWithSchemaHeader, streamName, regionName); } byte[] runSampleForGetRecord() throws IOException { ByteBuffer recordWithSchemaHeader = kinesisApi.getRecords(streamName, regionName); //The following lines remove the schema registry header GlueSchemaRegistryDeserializerImpl glueSchemaRegistryDeserializer = new GlueSchemaRegistryDeserializerImpl(DefaultCredentialsProvider.builder().build(), new GlueSchemaRegistryConfiguration(regionName)); byte[] recordWithSchemaHeaderBytes = new byte[recordWithSchemaHeader.remaining()]; recordWithSchemaHeader.get(recordWithSchemaHeaderBytes, 0, recordWithSchemaHeaderBytes.length); com.amazonaws.services.schemaregistry.common.Schema awsSchema = glueSchemaRegistryDeserializer.getSchema(recordWithSchemaHeaderBytes); byte[] record = glueSchemaRegistryDeserializer.getData(recordWithSchemaHeaderBytes); //The following lines serialize an AVRO schema record if (DataFormat.AVRO.name().equals(awsSchema.getDataFormat())) { Schema avroSchema = new org.apache.avro.Schema.Parser().parse(awsSchema.getSchemaDefinition()); Object genericRecord = convertBytesToRecord(avroSchema, record); System.out.println(genericRecord); } return record; } private byte[] convertRecordToBytes(final Object record) throws IOException { ByteArrayOutputStream recordAsBytes = new ByteArrayOutputStream(); Encoder encoder = EncoderFactory.get().directBinaryEncoder(recordAsBytes, null); GenericDatumWriter datumWriter = new GenericDatumWriter<>(AVROUtils.getInstance().getSchema(record)); datumWriter.write(record, encoder); encoder.flush(); return recordAsBytes.toByteArray(); } private GenericRecord convertBytesToRecord(Schema avroSchema, byte[] record) throws IOException { final GenericDatumReader<GenericRecord> datumReader = new GenericDatumReader<>(avroSchema); Decoder decoder = DecoderFactory.get().binaryDecoder(record, null); GenericRecord genericRecord = datumReader.read(null, decoder); return genericRecord; } private Map<String, String> getMetadata() { Map<String, String> metadata = new HashMap<>(); metadata.put("event-source-1", "topic1"); metadata.put("event-source-2", "topic2"); metadata.put("event-source-3", "topic3"); metadata.put("event-source-4", "topic4"); metadata.put("event-source-5", "topic5"); return metadata; } private GlueSchemaRegistryConfiguration getConfigs() { GlueSchemaRegistryConfiguration configs = new GlueSchemaRegistryConfiguration(regionName); configs.setSchemaName(schemaName); configs.setAutoRegistration(true); configs.setMetadata(getMetadata()); return configs; } private Object getTestRecord() throws IOException { GenericRecord genericRecord; Schema.Parser parser = new Schema.Parser(); Schema avroSchema = parser.parse(new File(AVRO_USER_SCHEMA_FILE)); genericRecord = new GenericData.Record(avroSchema); genericRecord.put("name", "testName"); genericRecord.put("favorite_number", 99); genericRecord.put("favorite_color", "red"); return genericRecord; } }
应用场景:适用于 Apache Flink 的亚马逊托管服务
Apache Flink 是一个热门的开源框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。适用于 Apache Flink 的亚马逊托管服务是一项完全托管式的 Amazon 服务,可让您构建和管理 Apache Flink 应用程序以处理流式传输数据。
开源 Apache Flink 提供了大量的源和接收器。例如,预定义的数据源包括从文件、目录和套接字读取数据,以及从集合和迭代器中提取数据。Apache Flink DataStream 连接器为 Apache Flink 提供与各种第三方系统(如作为源和/或接收器的 Apache Kafka 或 Kinesis)接口的代码。
有关更多信息,请参阅 Amazon Kinesis Data Analytics 开发人员指南。
Apache Flink Kafka 连接器
Apache Flink 提供 Apache Kafka 数据流连接器,用于从 Kafka 主题读取数据并将数据写入其中,确切具有一次保证。Flink 的 Kafka 使用器 FlinkKafkaConsumer 提供从一个或多个 Kafka 主题读取数据的访问权限。Apache Flink 的 Kafka 创建器 FlinkKafkaProducer 允许将记录流写入一个或多个 Kafka 主题。有关更多信息,请参阅 Apache Kafka 连接器
Apache Flink Kinesis Streams 连接器
Kinesis 数据流连接器可让您访问 Amazon Kinesis Data Streams。FlinkKinesisConsumer 是确切一次的并行流数据源,它订阅同一 Amazon 服务区域的多个 Kinesis 流,并且可以在任务运行时透明地处理流的重新分区。使用器的每个子任务负责从多个 Kinesis 分片中获取数据记录。随着分区关闭并由 Kinesis 创建,每个子任务获取的分片数量将发生变化。FlinkKinesisProducer 使用 Kinesis Producer Library(KPL)将来自 Apache Flink 流的数据放入 Kinesis 流。有关更多信息,请参阅 Amazon Kinesis Streams 连接器
有关更多信息,请参阅 Amazon Glue GitHub 存储库
与 Apache Flink 集成
架构注册表提供的 SerDes 库与 Apache Flink 集成。要使用 Apache Flink,您需要实施 SerializationSchemaDeserializationSchemaGlueSchemaRegistryAvroSerializationSchema 和 GlueSchemaRegistryAvroDeserializationSchema),您可以将其插入 Apache Fink 连接器。
将 Amazon Glue 架构注册表依赖关系添加到 Apache Flink 应用程序
将集成依赖项设置到 Apache Flink 应用程序中的 Amazon Glue 架构注册表:
将依赖项添加到
pom.xml文件。<dependency> <groupId>software.amazon.glue</groupId> <artifactId>schema-registry-flink-serde</artifactId> <version>1.0.0</version> </dependency>
将 Kafka 或 Amazon MSK 与 Apache Fink 集成
您可以使用 Managed Service for Apache Flink for Apache Flink,以 Kafka 作为源或接收器。
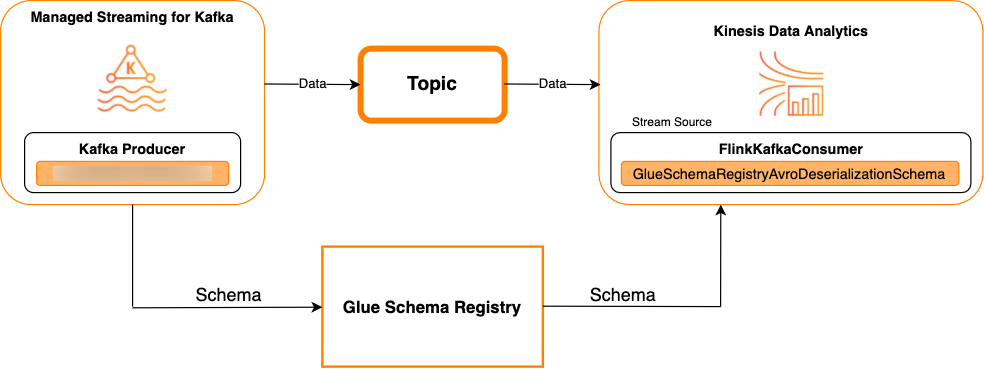
以 Kafka 为源:
下图显示了将 Kinesis Data Streams 与 Managed Service for Apache Flink for Apache Flink 集成,以 Kafka 作为源。
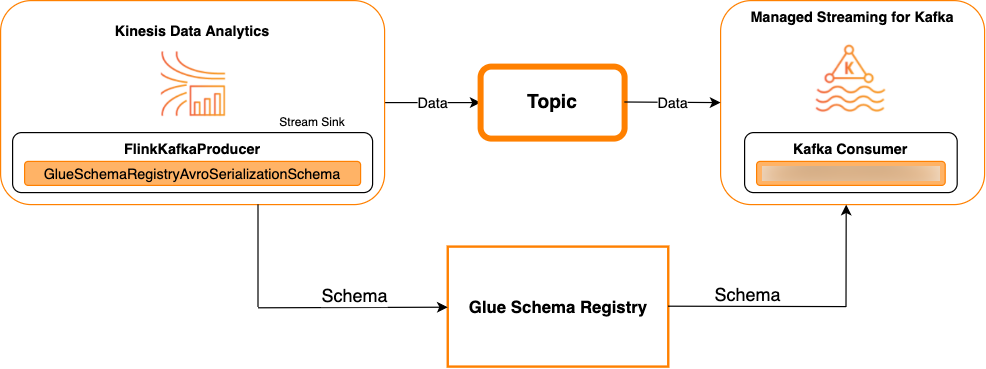
以 Kafka 为接收器
下图显示了将 Kinesis Data Streams 与 Managed Service for Apache Flink for Apache Flink 集成,以 Kafka 作为接收器。
要将 Kafka(或者 Amazon MSK)与 Managed Service for Apache Flink for Apache Flink 集成,以 Kafka 作为源或接收器,请在下面进行代码更改。将粗体代码数据块添加到类似部分中相应的代码。
如果 Kafka 是源,则使用反序列化程序代码(数据块 2)。如果 Kafka 是接收器,则使用序列化程序代码(数据块 3)。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); String topic = "topic"; Properties properties = new Properties(); properties.setProperty("bootstrap.servers", "localhost:9092"); properties.setProperty("group.id", "test"); // block 1 Map<String, Object> configs = new HashMap<>(); configs.put(AWSSchemaRegistryConstants.AWS_REGION, "aws-region"); configs.put(AWSSchemaRegistryConstants.SCHEMA_AUTO_REGISTRATION_SETTING, true); configs.put(AWSSchemaRegistryConstants.AVRO_RECORD_TYPE, AvroRecordType.GENERIC_RECORD.getName()); FlinkKafkaConsumer<GenericRecord> consumer = new FlinkKafkaConsumer<>( topic, // block 2 GlueSchemaRegistryAvroDeserializationSchema.forGeneric(schema, configs), properties); FlinkKafkaProducer<GenericRecord> producer = new FlinkKafkaProducer<>( topic, // block 3 GlueSchemaRegistryAvroSerializationSchema.forGeneric(schema, topic, configs), properties); DataStream<GenericRecord> stream = env.addSource(consumer); stream.addSink(producer); env.execute();
将 Kinesis Data Streams 与 Apache Flink 集成
您可以使用 Managed Service for Apache Flink for Apache Flink,以 Kinesis Data Streams 作为源或接收器。
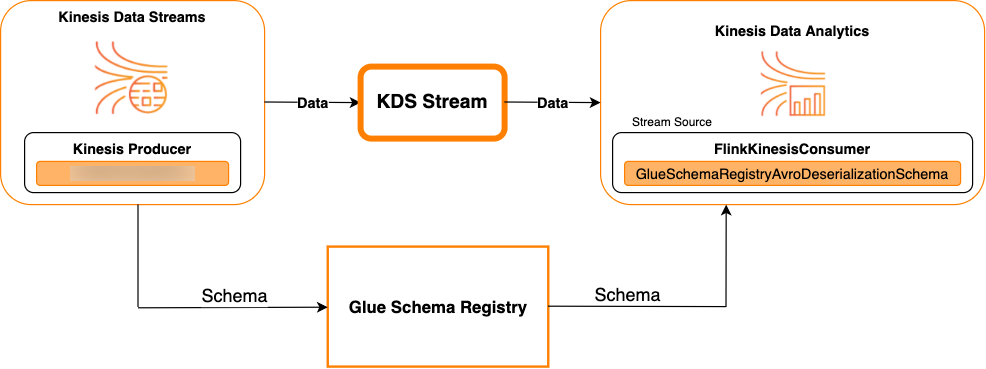
以 Kinesis Data Streams 为源
下图显示了将 Kinesis Data Streams 与 Managed Service for Apache Flink for Apache Flink 集成,以 Kinesis Data Streams 作为源。
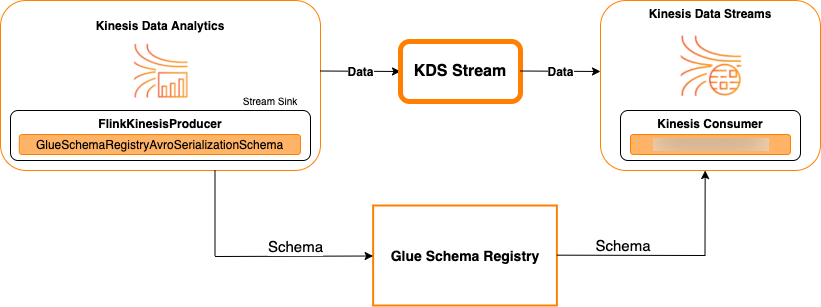
以 Kinesis Data Streams 为接收器
下图显示了将 Kinesis Data Streams 与 Managed Service for Apache Flink for Apache Flink 集成,以 Kinesis Data Streams 作为接收器。
要将 Kinesis Data Streams 与 Managed Service for Apache Flink for Apache Flink 集成,以 Kinesis Data Streams 作为源或接收器,请在下面进行代码更改。将粗体代码数据块添加到类似部分中相应的代码。
如果 Kinesis Data Streams 是源,请使用反序列化程序代码(数据块 2)。如果 Kinesis Data Streams 是接收器,请使用序列化程序代码(数据块 3)。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); String streamName = "stream"; Properties consumerConfig = new Properties(); consumerConfig.put(AWSConfigConstants.AWS_REGION, "aws-region"); consumerConfig.put(AWSConfigConstants.AWS_ACCESS_KEY_ID, "aws_access_key_id"); consumerConfig.put(AWSConfigConstants.AWS_SECRET_ACCESS_KEY, "aws_secret_access_key"); consumerConfig.put(ConsumerConfigConstants.STREAM_INITIAL_POSITION, "LATEST"); // block 1 Map<String, Object> configs = new HashMap<>(); configs.put(AWSSchemaRegistryConstants.AWS_REGION, "aws-region"); configs.put(AWSSchemaRegistryConstants.SCHEMA_AUTO_REGISTRATION_SETTING, true); configs.put(AWSSchemaRegistryConstants.AVRO_RECORD_TYPE, AvroRecordType.GENERIC_RECORD.getName()); FlinkKinesisConsumer<GenericRecord> consumer = new FlinkKinesisConsumer<>( streamName, // block 2 GlueSchemaRegistryAvroDeserializationSchema.forGeneric(schema, configs), properties); FlinkKinesisProducer<GenericRecord> producer = new FlinkKinesisProducer<>( // block 3 GlueSchemaRegistryAvroSerializationSchema.forGeneric(schema, topic, configs), properties); producer.setDefaultStream(streamName); producer.setDefaultPartition("0"); DataStream<GenericRecord> stream = env.addSource(consumer); stream.addSink(producer); env.execute();
使用案例:与 Amazon Lambda 集成
要将 Amazon Lambda 函数用作 Apache Kafka/Amazon MSK 使用器,并使用 Amazon Glue 架构注册表反序列化 Avro 编码消息,请访问 MSK Labs 页
使用案例:Amazon Glue Data Catalog
Amazon Glue 表支持您可以手动指定或通过引用 Amazon Glue 架构注册表的架构。架构注册表与数据目录集成,以允许您在创建或更新数据目录中 Amazon Glue 表或分区时选择性地使用存储于架构注册表中的架构。要标识架构注册表中的架构定义,您至少需要知道它所属的架构的 ARN。架构的架构版本(包含架构定义)可以通过其 UUID 或版本号引用。总有一个架构版本,即“最新”版本,可以在不知道其版本号或 UUID 的情况下查找。
当调用 CreateTable 或者 UpdateTable 操作时,您将传递一个 TableInput 结构,其中包含 StorageDescriptor,它可能有指向架构注册表中现有架构的 SchemaReference。同样,当您调用 GetTable 或者GetPartition API 时,响应可能包含架构和 SchemaReference。使用架构引用创建表或分区时,数据目录将尝试为此架构引用提取架构。如果无法在架构注册表中找到架构,它会在 GetTable 响应中返回空架构;否则响应将具有架构和架构引用。
您还可以在 Amazon Glue 控制台中执行操作。
要执行这些操作并创建、更新或查看架构信息,您必须为调用用户授予允许 GetSchemaVersion API 的 IAM 角色权限。
添加表或更新表的架构
从现有架构添加新表会将表绑定到特定架构版本。注册新架构版本后,您可以从 Amazon Glue 控制台的 View table (查看表) 页面或使用 UpdateTable 操作(Python:update_table) API 更新表定义。
从现有架构添加表
您可以使用 Amazon Glue 控制台或 CreateTable API 通过注册表中的架构版本创建 Amazon Glue 表。
Amazon Glue API
当调用 CreateTable API 时,您将传递一个 TableInput,其中包含 StorageDescriptor,它可能有指向架构注册表中现有架构的 SchemaReference。
Amazon Glue 控制台
从 Amazon Glue 控制台创建表:
-
登录 Amazon Web Services 管理控制台,然后打开 Amazon Glue 控制台,网址为:https://console.aws.amazon.com/glue/
。 在导航窗格的 Data catalog (数据目录) 中,请选择 Tables (表)。
在 Add Tables (添加表) 菜单中,选择 Add table from existing schema (从现有架构添加表)。
根据 Amazon Glue 开发人员指南配置表属性和数据存储。
在 Choose a Glue schema (选择 Glue 架构) 页面上,选择架构所在的 Registry (注册表)。
选择 Schema name (架构名称),然后选择要应用的架构的 Version (版本)。
查看架构预览,然后选择 Next (下一步)。
审核和创建表。
应用于表的架构和版本将在表列表的 Glue schema (Glue 架构)列中显示。您可以查看表以了解更多详细信息。
更新表架构
当有新架构版本时,您可能需要使用 UpdateTable 操作(Python:update_table) API 或 Amazon Glue 控制台更新表架构。
重要
当为已手动指定 Amazon Glue 架构的现有表更新架构时,架构注册表中引用的新架构可能不兼容。这可能会导致您的任务失败。
Amazon Glue API
当调用 UpdateTable API 时,您将传递一个 TableInput,其中包含 StorageDescriptor,它可能有指向架构注册表中现有架构的 SchemaReference。
Amazon Glue 控制台
从 Amazon Glue 控制台更新表的架构:
-
登录 Amazon Web Services 管理控制台,然后打开 Amazon Glue 控制台,网址为:https://console.aws.amazon.com/glue/
。 在导航窗格的 Data catalog (数据目录) 中,请选择 Tables (表)。
从表列表中查看表。
在告知您新版本的框中单击 Update schema (更新架构)。
查看当前架构和新架构之间的差异。
选择 Show all schema differences (显示所有架构差异),查看更多详细信息。
选择 Save table (保存表) 以接受新版本。
使用案例:Amazon Glue 流式传输
Amazon Glue 流式传输会首先使用流式传输源的数据并执行 ETL 操作,然后再写入输出接收器。可以使用数据表或直接通过指定源配置来指定输入流式传输源。
Amazon Glue 流式传输支持将利用 Amazon Glue Schema 注册表中存在的 Schema 创建的数据目录表作为流式传输源。您可以在 Amazon Glue Schema 注册表中创建一个 Schema 并利用此 Schema 创建一个带有流式传输源的 Amazon Glue 表。此 Amazon Glue 表可以用作 Amazon Glue 流式传输任务的输入,以确保输入流中数据的反序列化。
这里需要注意的是,在 Amazon Glue Schema 注册表中的 Schema 更改时,您需要重启 Amazon Glue 流式传输任务以反映 Schema 中的更改。
使用案例:Apache Kafka Streams
Apache Kafka Streams API 是一个客户端库,用于处理和分析存储在 Apache Kafka 中的数据。本部分介绍 Apache Kafka Streams 与 Amazon Glue 架构注册表的集成,允许您在数据流应用程序上管理和强制实施架构。有关 Apache Kafka Streams 的更多信息,请参阅 Apache Kafka
与 SerDes 库集成
有一个 GlueSchemaRegistryKafkaStreamsSerde 类,您可以使用其配置 Streams 应用程序。
Kafka Streams 应用程序示例代码
在 Apache Kafka Streams 应用程序内使用 Amazon Glue 架构注册表:
配置 Kafka Streams 应用程序。
final Properties props = new Properties(); props.put(StreamsConfig.APPLICATION_ID_CONFIG, "avro-streams"); props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); props.put(StreamsConfig.CACHE_MAX_BYTES_BUFFERING_CONFIG, 0); props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName()); props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, AWSKafkaAvroSerDe.class.getName()); props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest"); props.put(AWSSchemaRegistryConstants.AWS_REGION, "aws-region"); props.put(AWSSchemaRegistryConstants.SCHEMA_AUTO_REGISTRATION_SETTING, true); props.put(AWSSchemaRegistryConstants.AVRO_RECORD_TYPE, AvroRecordType.GENERIC_RECORD.getName()); props.put(AWSSchemaRegistryConstants.DATA_FORMAT, DataFormat.AVRO.name());通过主题 avro-input 创建流。
StreamsBuilder builder = new StreamsBuilder(); final KStream<String, GenericRecord> source = builder.stream("avro-input");处理数据记录(该示例会筛选出 favorite_color 值为 pink 或金额值为 15 的记录)。
final KStream<String, GenericRecord> result = source .filter((key, value) -> !"pink".equals(String.valueOf(value.get("favorite_color")))); .filter((key, value) -> !"15.0".equals(String.valueOf(value.get("amount"))));将结果写回主题 avro-output。
result.to("avro-output");启动 Apache Kafka Streams 应用程序。
KafkaStreams streams = new KafkaStreams(builder.build(), props); streams.start();
实施结果
这些结果显示了记录筛选流程,这些记录在步骤 3 中筛选出,其 favorite_color 为“pink”或值为“15.0”。
筛选前的记录:
{"name": "Sansa", "favorite_number": 99, "favorite_color": "white"} {"name": "Harry", "favorite_number": 10, "favorite_color": "black"} {"name": "Hermione", "favorite_number": 1, "favorite_color": "red"} {"name": "Ron", "favorite_number": 0, "favorite_color": "pink"} {"name": "Jay", "favorite_number": 0, "favorite_color": "pink"} {"id": "commute_1","amount": 3.5} {"id": "grocery_1","amount": 25.5} {"id": "entertainment_1","amount": 19.2} {"id": "entertainment_2","amount": 105} {"id": "commute_1","amount": 15}
筛选后的记录:
{"name": "Sansa", "favorite_number": 99, "favorite_color": "white"} {"name": "Harry", "favorite_number": 10, "favorite_color": "black"} {"name": "Hermione", "favorite_number": 1, "favorite_color": "red"} {"name": "Ron", "favorite_number": 0, "favorite_color": "pink"} {"id": "commute_1","amount": 3.5} {"id": "grocery_1","amount": 25.5} {"id": "entertainment_1","amount": 19.2} {"id": "entertainment_2","amount": 105}
使用案例:Apache Kafka Connect
Apache Kafka Connect 与 Amazon Glue 架构注册表集成,支持您从连接器获取架构信息。Apache Kafka 转换器指定 Apache Kafka 内数据的格式以及如何将其转换为 Apache Kafka Connect 数据。每个 Apache Kafka Connect 用户都需要配置这些转换器,基于从 Apache Kafka 加载数据或将数据存储到 Apache Kafka 时期望数据采用的格式。通过这种方式,您可以定义自己的转换器,将 Apache Kafka Connect 数据转换为 Amazon Glue 架构注册表(例如:Avro),并使用我们的序列化程序注册其架构并执行序列化。然后,转换器还能够使用我们的反序列化程序来反序列化从 Apache Kafka 接收的数据,并将其转换回 Apache Kafka Connect 数据。下面提供了一个示例工作流图。
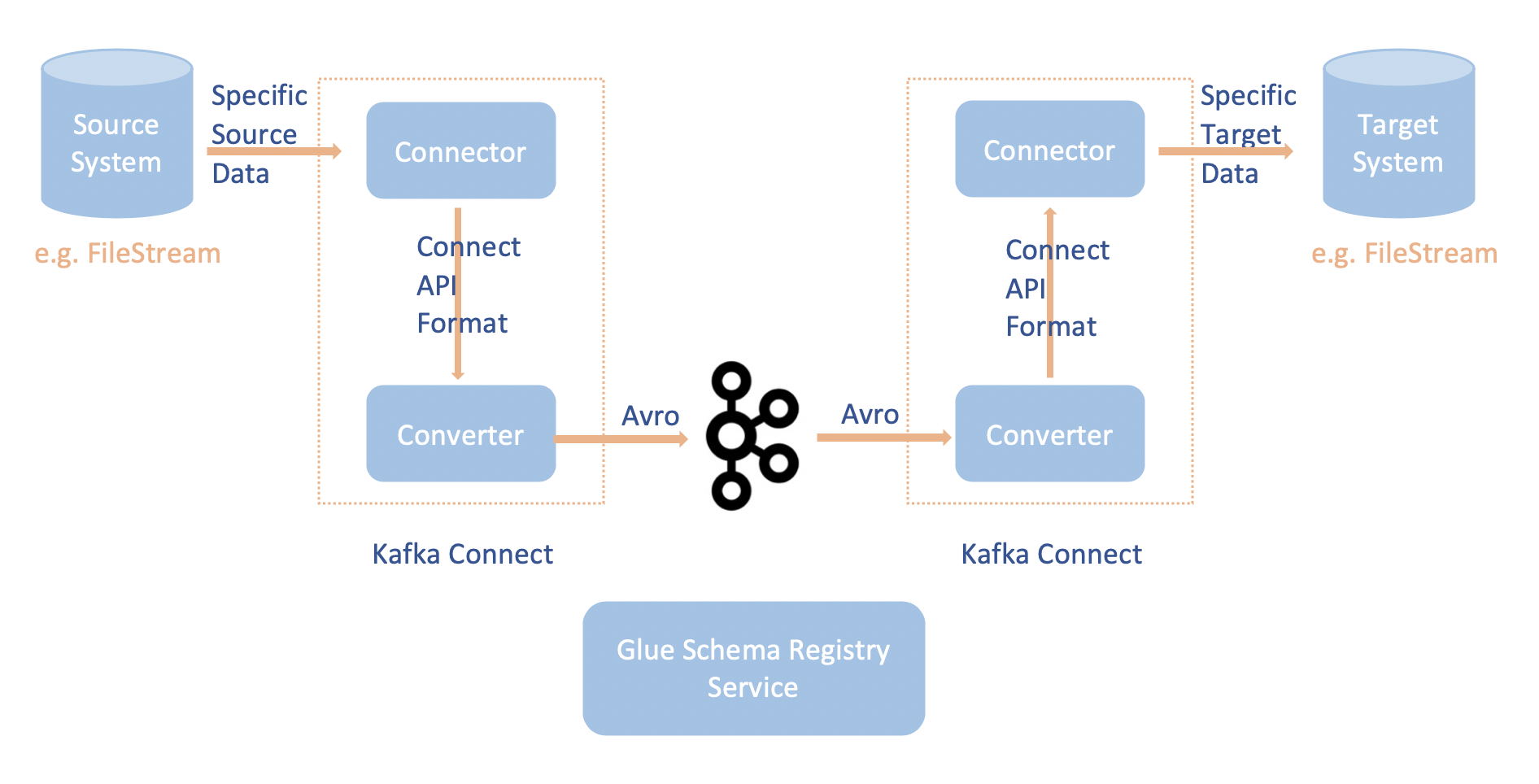
克隆适用于 Amazon Glue 架构注册表的 Github 存储库
,安装 aws-glue-schema-registry项目。git clone git@github.com:awslabs/aws-glue-schema-registry.git cd aws-glue-schema-registry mvn clean install mvn dependency:copy-dependencies如果您计划以独立模式使用 Apache Kafka Connect,请按照下面针对本步骤的说明更新 connect-standalone.properties。如果您计划以分布式模式使用 Apache Kafka Connect,请按照相同的说明更新 connect-avro-distributed.properties。
您还可以将这些属性添加到 Apache Kafka Connect 属性文件:
key.converter.region=aws-regionvalue.converter.region=aws-regionkey.converter.schemaAutoRegistrationEnabled=true value.converter.schemaAutoRegistrationEnabled=true key.converter.avroRecordType=GENERIC_RECORD value.converter.avroRecordType=GENERIC_RECORD将下面的命令添加到 kafka-run-class.sh 下面的 Launch mode (启动模式):
-cp $CLASSPATH:"<your Amazon GlueSchema Registry base directory>/target/dependency/*"
将下面的命令添加到 kafka-run-class.sh 下面的 Launch mode (启动模式)
-cp $CLASSPATH:"<your Amazon GlueSchema Registry base directory>/target/dependency/*"它应如下所示:
# Launch mode if [ "x$DAEMON_MODE" = "xtrue" ]; then nohup "$JAVA" $KAFKA_HEAP_OPTS $KAFKA_JVM_PERFORMANCE_OPTS $KAFKA_GC_LOG_OPTS $KAFKA_JMX_OPTS $KAFKA_LOG4J_OPTS -cp $CLASSPATH:"/Users/johndoe/aws-glue-schema-registry/target/dependency/*" $KAFKA_OPTS "$@" > "$CONSOLE_OUTPUT_FILE" 2>&1 < /dev/null & else exec "$JAVA" $KAFKA_HEAP_OPTS $KAFKA_JVM_PERFORMANCE_OPTS $KAFKA_GC_LOG_OPTS $KAFKA_JMX_OPTS $KAFKA_LOG4J_OPTS -cp $CLASSPATH:"/Users/johndoe/aws-glue-schema-registry/target/dependency/*" $KAFKA_OPTS "$@" fi如果使用 Bash,请运行以下命令以在 bash_profile 中设置您的 CLASSPATH。对于任何其他 Shell,请相应地更新环境。
echo 'export GSR_LIB_BASE_DIR=<>' >>~/.bash_profile echo 'export GSR_LIB_VERSION=1.0.0' >>~/.bash_profile echo 'export KAFKA_HOME=<your Apache Kafka installation directory>' >>~/.bash_profile echo 'export CLASSPATH=$CLASSPATH:$GSR_LIB_BASE_DIR/avro-kafkaconnect-converter/target/schema-registry-kafkaconnect-converter-$GSR_LIB_VERSION.jar:$GSR_LIB_BASE_DIR/common/target/schema-registry-common-$GSR_LIB_VERSION.jar:$GSR_LIB_BASE_DIR/avro-serializer-deserializer/target/schema-registry-serde-$GSR_LIB_VERSION.jar' >>~/.bash_profile source ~/.bash_profile(可选)如果要使用简单的文件源进行测试,请克隆文件源连接器。
git clone https://github.com/mmolimar/kafka-connect-fs.git cd kafka-connect-fs/在源连接器配置下,将数据格式编辑为 Avro,将文件读取器编辑为
AvroFileReader并从您正在读取的文件路径中更新示例 Avro 对象。例如:vim config/kafka-connect-fs.propertiesfs.uris=<path to a sample avro object> policy.regexp=^.*\.avro$ file_reader.class=com.github.mmolimar.kafka.connect.fs.file.reader.AvroFileReader安装源连接器。
mvn clean package echo "export CLASSPATH=\$CLASSPATH:\"\$(find target/ -type f -name '*.jar'| grep '\-package' | tr '\n' ':')\"" >>~/.bash_profile source ~/.bash_profile更新
<your Apache Kafka installation directory>/config/connect-file-sink.propertiesfile=<output file full path> topics=<my topic>
启动源连接器(在本示例中,它是一个文件源连接器)。
$KAFKA_HOME/bin/connect-standalone.sh $KAFKA_HOME/config/connect-standalone.properties config/kafka-connect-fs.properties运行接收器连接器(在本示例中,它是一个文件接收器连接器)。
$KAFKA_HOME/bin/connect-standalone.sh $KAFKA_HOME/config/connect-standalone.properties $KAFKA_HOME/config/connect-file-sink.properties有关 Kafka Connect 用法的示例,请查看适用于 Amazon Glue 架构注册表的 Github 存储库
中 integration-tests 文件夹下的 run-local-tests.sh 脚本。