使用自动平衡处理转换来优化运行时
自动平衡处理转换在工作线程之间重新分配数据,以提高性能。当数据不平衡或数据来自源时不允许对其进行足够的并行处理时,这很有用。在源代码为 GZIP 或 JDBC 的情况下,这种情况很常见。数据的再分发具有适度的性能成本,因此,如果数据已经很好地平衡,优化可能并不总是能弥补这种努力。在下面,转换使用 Apache Spark 重新分区在最适合集群容量的多个分区之间随机重新分配数据。对于高级用户,可以手动输入多个分区。此外,它还可用于通过根据指定列重新组织数据来优化分区表的写入。这会使输出文件更加合并。
-
打开资源面板,然后选择自动平衡处理将新转换添加到作业图。添加节点时选择的节点将是其父节点。
-
(可选)在节点属性选项卡上,输入任务图中节点的名称。如果尚未选择父节点,请从 Node parents (父节点) 列表中选择一个节点,用作转换的输入源。
-
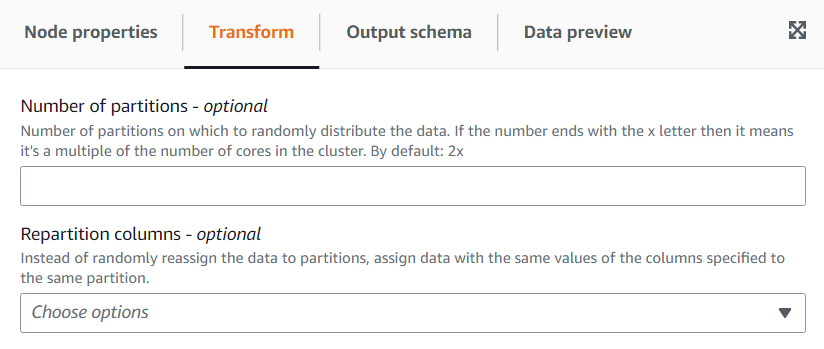
(可选)在转换选项卡上,可以输入多个分区。通常,建议您让系统决定该值,但是如果您需要控制该值,则可以调整乘数或输入特定值。如果要保存按列分区的数据,则可以选择与重新分区列相同的列。这样,它将最大限度地减少每个分区上的文件数量,并避免每个分区有多个文件,这将阻碍查询该数据的工具的性能。