本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
RANDOM_CUT_FOREST
在数据流中检测异常。 如果某个记录与其他记录相距较远,则表明该记录是异常的。 要检测各个记录列中的异常情况,请参阅RANDOM_CUT_FOREST_WITH_EXPLANATION。
注意
RANDOM_CUT_FOREST 函数检测异常的能力取决于应用程序。要确定业务问题以便通过此函数解决,需要具备领域专业知识。例如,确定要将输入流中的哪些列组合传递给此函数,并可能对数据进行规范化。有关更多信息,请参阅 inputStream。
流记录可以有非数字列,但该函数仅使用数字列来分配异常分数。一条记录可以有一个或多个数字列。该算法使用所有数字数据来计算异常分数。 如果一个记录有 n 个数字列,底层算法将假定每个记录都是 n 维空间中的一个点。n 维空间中与其他点相距较远的点将获得较高的异常分数。
当您启动应用程序时,该算法开始使用流中的当前记录开发机器学习模型。该算法不使用流中较旧的记录进行机器学习,也不使用来自应用程序的之前执行的统计数据。
该算法接受 DOUBLE、INTEGER、FLOAT、TINYINT、SMALLINT、REAL 和 BIGINT 数据类型。
注意
DECIMAL 不是受支持的类型。请改用 DOUBLE。
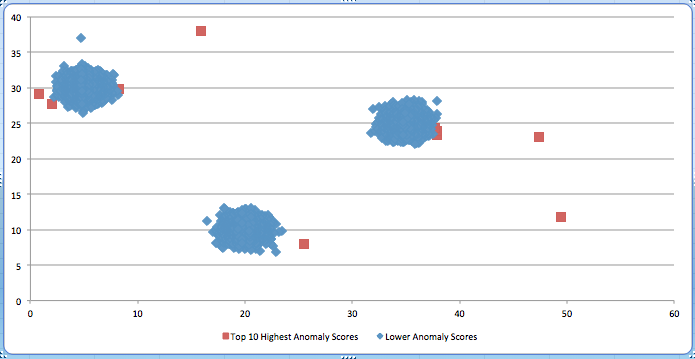
以下是异常检测的示例。该图显示了三个集群和几个随机插入的异常。根据 RANDOM_CUT_FOREST 函数,红色方块显示获得最高异常分数的记录。蓝色菱形代表剩余的记录。 请注意分数最高的记录如何倾向于位于集群外面。
有关带分步指导的示例应用程序,请参阅检测异常情况。
语法
RANDOM_CUT_FOREST (inputStream, numberOfTrees, subSampleSize, timeDecay, shingleSize)
参数
以下各节介绍了这些参数。
inputStream
指向输入流的指针。您可以使用 CURSOR 函数设置指针。例如,以下语句将设置指向 InputStream 的指针。
CURSOR(SELECT STREAM * FROM InputStream) CURSOR(SELECT STREAM IntegerColumnX, IntegerColumnY FROM InputStream) -– Perhaps normalize the column X value. CURSOR(SELECT STREAM IntegerColumnX / 100, IntegerColumnY FROM InputStream) –- Combine columns before passing to the function. CURSOR(SELECT STREAM IntegerColumnX - IntegerColumnY FROM InputStream)
CURSOR 函数是 RANDOM_CUT_FOREST 函数的唯一必需参数。该函数假设其他参数的默认值如下:
数字 OfTrees = 100
sub SampleSize = 256
timeDecay = 100,000
shingleSize = 1
使用此函数时,输入流最多可以有 30 个数字列。
数字 OfTrees
使用此参数,您可以指定森林中随机砍伐的树木数量。
注意
默认情况下,该算法会构造许多树,每棵树都是使用输入流中给定数量的样本记录(请参阅本列表后面的 subSampleSize)构造的。该算法使用每棵树来分配异常分数。所有这些分数的平均值是最终的异常分数。
numberOfTrees 的默认值为 100。您可以将此值设置为介于 1 和 1000 之间(含 1 和 1000)。通过增加森林中树的数量,您可以获得异常分数的更准确估算,但这也会延长运行时间。
sub SampleSize
使用此参数,您可以指定在构造每棵树时希望算法使用的随机样本的大小。 森林中每棵树都是使用记录的一个(不同的)随机样本构建的。 该算法使用每棵树来分配异常分数。当样本达到 subSampleSize 条记录时,会随机删除记录,较旧记录的删除概率高于较新记录。
subSampleSize 的默认值为 256。 您可以将此值设置为介于 10 和 1,000 之间(含 10 和 1,000)。
请注意,subSampleSize 必须小于 timeDecay 参数(默认情况下设置为 100000)。 增大样本大小将为每棵树提供更大的数据视图,但也会延长运行时间。
注意
在训练机器学习模型时,算法为首批 subSampleSize 个记录返回零。
timeDecay
timeDecay 参数允许您指定计算异常分数时要考虑过去的多长时间。这是因为数据流会随着时间的推移而自然演变。例如,随着时间的推移,电子商务网站的收入可能会不断增加,或者全球温度可能会逐渐升高。 在这些情况下,我们希望对照较早的数据对最近的数据中的异常进行标记。
默认值为 100000 条记录(如果使用瓦形,则为 100000 个瓦形,如下一节所述)。您可以将此值设置为介于 1 和最大整数(即 2147483647)之间。该算法以指数方式降低了旧数据的重要性。
如果您选择 timeDecay 的默认值 100000,则异常检测算法将执行以下操作:
-
在计算中仅使用最近的 100000 条记录(并忽略较早的记录)。
-
在最近的 100000 条记录中,进行异常检测计算时,近期记录的权重呈指数级增长,而较早记录的权重则呈指数级下降。
如果不想使用默认值,则可以计算要在算法中使用的记录数。为此,请将每天的预期记录数乘以您希望算法考虑的天数。例如,如果您预计每天有 1,000 条记录,并且您希望分析 7 天的记录,请将此参数设置为 7,000 (1,000 * 7)。
timeDecay 参数决定了在异常检测算法的工作集中保留的最大最近记录数量。 如果数据改变得很快,则需要较小的 timeDecay 值。 怎样的 timeDecay 值最合适取决于应用程序。
shingleSize
此处给出的说明针对的是一维流(即,只有一个数值列的流),但也可用于多维流。
瓦形是最近记录的连续序列。 例如,时间 t 处大小为 10 的 shingleSize 对应于截至时间 t(含该时间)收到的最后 10 条记录的向量。 算法将此序列视为跨最后 shingleSize 个记录的向量。
如果数据以统一的时间到达,则时间 t 处的大小为 10 的瓦形对应于在时间 t-9、t-8、…、t 处收到的数据。 在时间 t+1 处,瓦形跨一个单位滑动,且包含来自时间 t-8、t-7、…、t、t+1 的数据。 随着时间的推移收集的这些瓦形记录对应于一个 10 维向量集合,异常检测算法将对该集合运行。
直觉告诉我们,瓦形可以捕获近期的形状。 您的数据可能有一个典型的形状。 例如,如果您的数据是每小时收集一次,大小为 24 的瓦形可以捕获您的数据的每日节奏。
默认 shingleSize 是一条记录(因为瓦形大小取决于数据)。您可以将此值设置为介于 1 和 30 之间(含 1 和 30)。
请注意有关设置 shingleSize 的以下内容:
-
如果将
shingleSize设置得过小,算法更容易受数据的细微波动的影响,从而导致并非异常的记录获得高异常分数。 -
如果将
shingleSize设置得过大,则可能需要更多时间来检测异常记录,因为非异常的瓦形中有更多记录。 确定异常情况已结束也可能需要更长时间。 -
确定正确的瓦形大小取决于应用程序。 请试验不同的瓦形大小以确定影响。
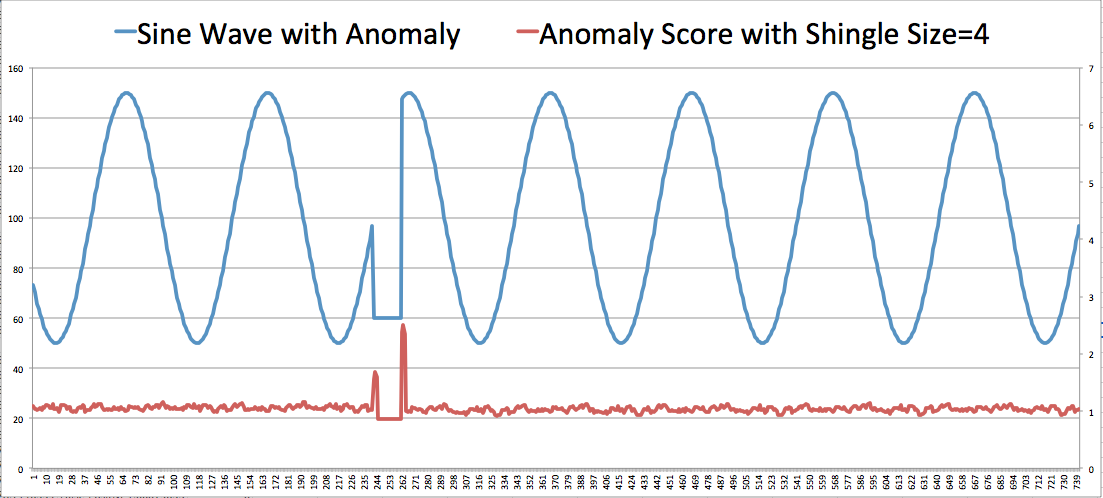
以下示例说明了在监控异常分数最高的记录时如何捕获异常。在这个特殊的示例中,两个最高的异常分数也表示人为注入的异常的开始和结束。
考虑这种以正弦波表示的程式化一维流,旨在捕捉昼夜节律。 此曲线显示了某个电子商务网站每小时收到的订单的典型数量、已登录服务器的用户的数量、每小时收到的广告点击量等。 图的中部人为插入了 20 个连续记录的急剧下降。

我们使用四条记录的瓦形大小运行 RANDOM_CUT_FOREST 函数。结果如下所示。红线表示异常分数。 请注意,异常的开头和结尾获得高分数。
使用此函数时,建议您将最高分数作为潜在异常进行调查。
注意
当 Kinesis Data Analytics 服务进行服务维护时,机器学习功能用于确定分析分数的趋势很少会被重置。发生服务维护后,您可能意外地看到分析分数为 0。我们建议您设置筛选条件或其他机制,以便在这些值出现时适当地处理它们。
有关更多信息,请参阅 Journal of Machine Learning Research 网站上的针对随机砍伐的森林在流上进行可靠的异常情况检测