本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
创建 Apache Iceberg 表
Amazon Lake Formation 支持创建使用 Apache Parquet 数据格式的 Apache Iceberg 表,数据驻留在 Amazon Glue Data Catalog Amazon S3 中。该数据目录中的表是表示数据存储中数据的元数据定义。默认情况下,Lake Formation 会创建 Iceberg v2 表。有关 v1 和 v2 表之间的区别,请参阅 Apache Iceberg 文档中的格式版本更改
Apache Iceberg
你可以使用 Lake Formation 控制台或 Amazon Glue API 中的CreateTable操作在数据目录中创建 Iceberg 表。有关更多信息,请参阅CreateTable 操作(Python:create_table)。
在数据目录中创建 Iceberg 表时,您必须在 Amazon S3 中指定表格式和元数据文件路径,以便能够执行读取和写入操作。
在注册 Amazon S3 数据位置时,您可以使用精细的访问控制权限使用 Lake Formation 来保护您的 Iceberg 表。 Amazon Lake Formation对于亚马逊 S3 中的源数据和未在 Lake Formation 中注册的元数据,访问权限由 Amazon S3 的 IAM 权限策略和 Amazon Glue 操作决定。有关更多信息,请参阅 管理 Lake Formation 权限。
注意
数据目录不支持创建分区和添加 Iceberg 表属性。
先决条件
要在数据目录中创建 Iceberg 表并设置 Lake Formation 数据访问权限,您需要完成以下要求:
-
在没有向 Lake Formation 注册数据的情况下创建 Iceberg 表所需的权限。
除了在数据目录中创建表所需的权限外,表创建者还需要以下权限:
针对资源 arn:aws:s3:::{bucketName} 的
s3:PutObject-
针对资源 arn:aws:s3:::{bucketName} 的
s3:GetObject -
针对资源 arn:aws:s3:::{bucketName} 的
s3:DeleteObject
-
使用向 Lake Formation 注册的数据创建 Iceberg 表所需的权限:
要使用 Lake Formation 管理和保护数据湖中的数据,请向 Lake Formation 注册包含表数据的 Amazon S3 位置。这样,Lake Formation 就可以将证书出售给 Athena、Redshift Spectrum 和 Amazon EMR 等 Amazon 分析服务机构以访问数据。有关注册 Amazon S3 位置的更多信息,请参阅向数据湖添加 Amazon S3 位置。
读取和写入向 Lake Formation 注册的基础数据的主体需要以下权限:
-
lakeformation:GetDataAccess -
DATA_LOCATION_ACCESS对某个位置具有数据位置权限的主体也对所有子位置具有位置权限。
有关数据位置权限的更多信息,请参阅基础数据访问控制。
-
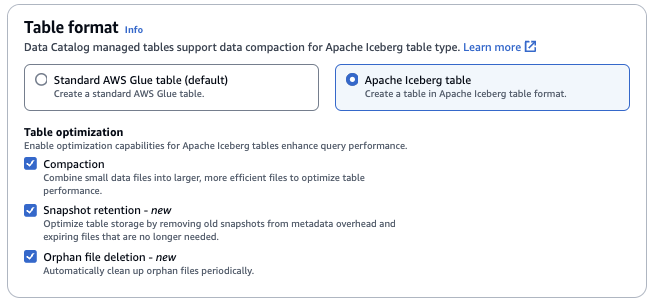
要启用压缩,该服务需要代入有权更新数据目录中的表的 IAM 角色。有关详细信息,请参阅表优化先决条件。
创建 Iceberg 表
你可以使用 Lake Formation 控制台创建 Iceberg v1 和 v2 表,也可以 Amazon Command Line Interface 按照本页上的说明创建。您也可以使用 Amazon Glue 控制台或 Amazon Glue 爬网程序创建 Iceberg 表。有关更多信息,请参阅《 Amazon Glue 开发人员指南》中的数据目录和爬网程序。
创建 Iceberg 表