本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
# Amazon Lake Formation:工作原理
Amazon Lake Formation 提供了关系数据库管理系统 (RDBMS) 权限模型,用于授予或撤消对数据目录资源的访问权限,例如在 Amazon S3 中包含基础数据的数据库、表和列。易于管理的 Lake Formation 权限取代了复杂的 Amazon S3 存储桶策略和相应的 IAM 策略。
在 Lake Formation 中,您可以在两个级别实施权限:
+ 对数据目录资源(例如,数据库和表)强制实施元数据级别权限
+ 代表集成引擎管理 Amazon S3 上存储的基础数据的存储访问权限
## Lake Formation 权限管理工作流
Lake Formation 与分析引擎集成,以查询已在 Lake Formation 中注册的 Amazon S3 数据存储和元数据对象。下图说明了 Lake Formation 中权限管理的工作原理。
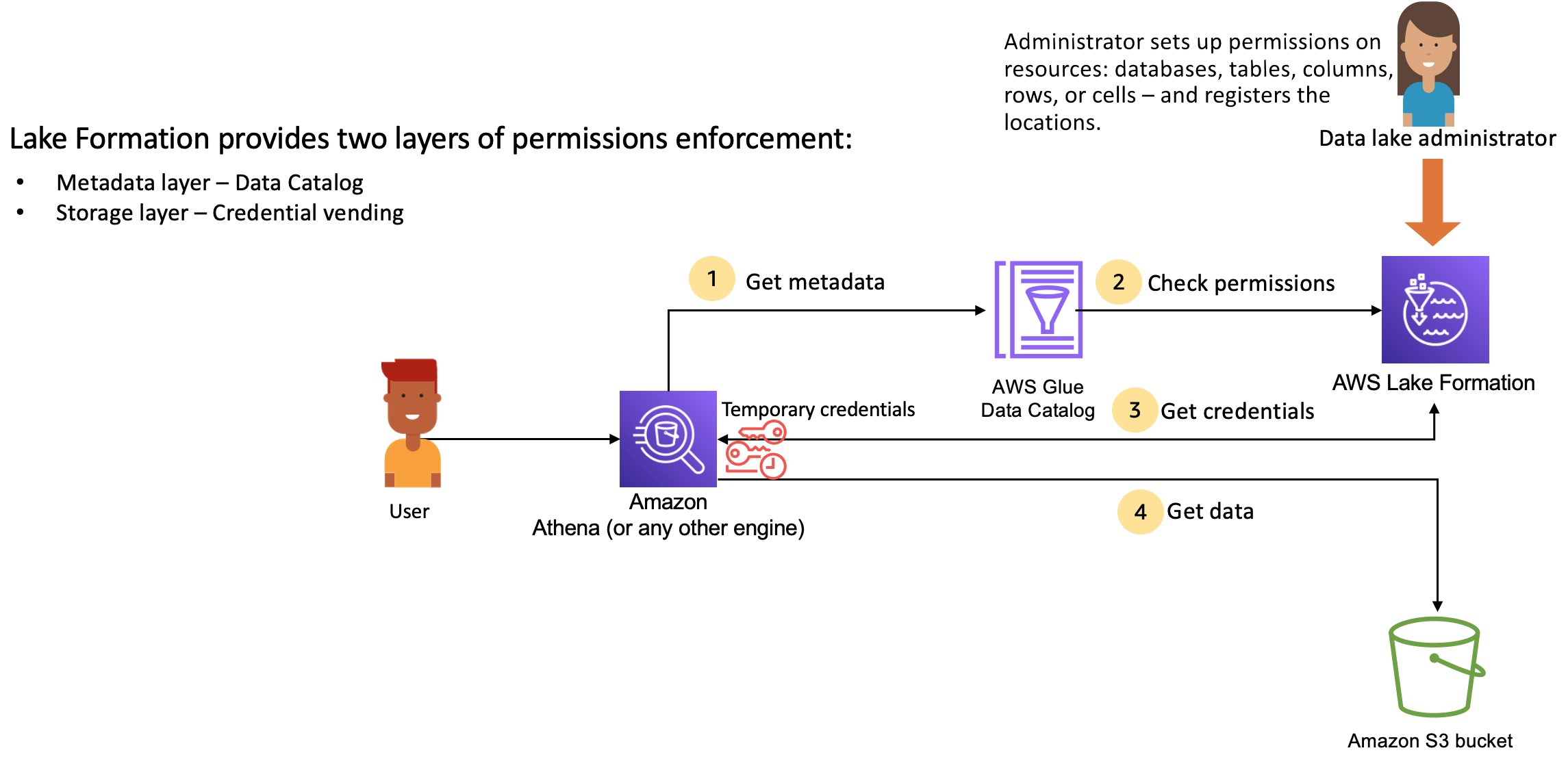
**Lake Formation 权限管理主要步骤**
[*数据湖管理员*](initial-lf-config.md#create-data-lake-admin)或具有管理权限的用户需设置单个数据目录表用户策略以允许或拒绝使用 Lake Formation 权限访问数据目录表,之后,Lake Formation 方可提供对数据湖中数据的访问控制。
然后,数据湖管理员或管理员委派的用户向各用户授予对数据目录数据库和表的 Lake Formation 权限,并将该表的 Amazon S3 位置注册到 Lake Formation 中。
1. **获取元数据** — 委托人(用户)向[集成分析引擎](working-with-services.md)(例如亚马逊 Athena、Amazon EMR 或 Amazon Glue Amazon Redshift Spectrum)提交查询或 ETL 脚本。集成分析引擎可识别正在请求的表,并将元数据请求发送到数据目录。
1. **检查权限** – 数据目录检查用户在 Lake Formation 中的权限,如果用户有权访问该表,则会将允许该用户查看的元数据返回给引擎。
1. **获取凭证** — 数据目录会告知引擎,该表是否由 Lake Formation 管理。如果基础数据已在 Lake Formation 中注册,则分析引擎会请求 Lake Formation 通过授予临时访问权限来提供数据访问权限。
1. **获取数据** – 如果用户有权访问该表,Lake Formation 将提供对集成分析引擎的临时访问权限。通过使用临时访问权限,分析引擎可从 Amazon S3 获取数据,并执行必要的筛选,例如列、行或单元格筛选。当引擎运行完作业后,它会将结果返回给用户。此过程称为[凭证售卖](using-cred-vending.md)。
如果该表不是由 Lake Formation 管理的,则分析引擎会直接向 Amazon S3 进行第二次调用。系统会对相关 Amazon S3 存储桶策略和 IAM 用户策略进行评估以确定是否支持访问数据。
每当您使用 IAM 策略时,请确保遵循 IAM 最佳实践。有关更多信息,请参阅《[IAM 用户指南](https://docs.amazonaws.cn/IAM/latest/UserGuide/best-practices.html)》中的 *IAM 安全最佳实践*。
**Topics**
+ [Lake Formation 权限管理工作流](#lf-workflow)
+ [元数据权限](metadata-permissions.md)
+ [存储访问管理](storage-permissions.md)
+ [Lake Formation 中的跨账户数据共享](cross-data-sharing-lf.md)