设计 Lambda 应用程序
架构完善的事件驱动型应用程序使用 Amazon 服务和自定义代码的组合来处理和管理请求与数据。本章重点介绍应用程序设计中特定于 Lambda 的主题。在为繁忙的生产系统设计应用程序时,无服务器架构师有许多需要考虑的重要注意事项。
许多适用于软件开发和分布式系统的最佳实践也适用于无服务器应用程序开发。总体目标是开发满足以下条件的工作负载:
-
可靠 – 为您的最终用户提供高水平的可用性。Amazon 无服务器服务之所以可靠,是因为它们也是为应对故障而设计的。
-
耐用 – 提供可满足工作负载耐用性需求的存储选项。
-
安全 – 遵循最佳实践并使用提供的工具来保护对工作负载的访问并限制影响范围。
-
性能 – 高效使用计算资源,并满足最终用户的性能需求。
-
成本效益 – 设计的架构可避免不必要的成本,既可以在不超支的情况下进行扩展,也可以在必要时停用,而不会产生大量开销。
以下设计原则有助于构建满足这些目标的工作负载。并非所有原则都适用于每种架构,但它们应能够指导您做出一般的架构决策。
使用服务而不是自定义代码
无服务器应用程序通常包含多项 Amazon 服务,这些服务与在 Lambda 函数中运行的自定义代码集成。虽然 Lambda 可以与大多数 Amazon 服务集成,但无服务器应用程序中最常用的服务有:
| 类别 | Amazon 服务 |
|---|---|
|
计算 |
Amazon Lambda |
|
数据存储 |
Amazon S3 Amazon DynamoDB Amazon RDS |
|
API |
Amazon API Gateway |
|
应用程序集成 |
Amazon EventBridge Amazon SNS Amazon SQS |
|
编排 |
Lambda 持久性函数 Amazon Step Functions |
|
流式传输数据和分析 |
Amazon Data Firehose |
注意
许多无服务器服务都为多个区域提供复制和支持,包括 DynamoDB 和 Amazon S3。作为部署管线的一部分,Lambda 函数可以部署在多个区域,并且 API Gateway 可以配置为支持此配置。请参阅此示例架构
分布式架构中有许多成熟的常见模式,您可以自行构建或使用 Amazon 服务来实施。对于大多数客户来说,投入时间从零开始开发这些模式几乎没有商业价值。当您的应用程序需要以下其中一个模式时,请使用相应的 Amazon 服务:
| 模式 | Amazon 服务 |
|---|---|
|
队列 |
Amazon SQS |
|
事件总线 |
Amazon EventBridge |
|
发布/订阅(扇出) |
Amazon SNS |
|
编排 |
Lambda 持久性函数 Amazon Step Functions |
|
API |
Amazon API Gateway |
|
事件流 |
Amazon Kinesis |
这些服务旨在与 Lambda 集成,您可以使用基础设施即代码(IaC)来创建和丢弃服务中的资源。您可以通过 Amazon SDK
了解 Lambda 抽象级别
Lambda 服务限制您对运行 Lambda 函数的底层操作系统、虚拟机监控程序和硬件的访问。该服务不断改进和更改基础设施,以增加功能、降低成本并提高服务的性能。您的代码应假设不了解 Lambda 的架构方式,且假设没有硬件关联性。
同样,Lambda 与其他服务的集成由 Amazon 管理,且仅向您公开少量配置选项。例如,API Gateway 和 Lambda 交互时,没有负载均衡概念,因为负载均衡完全由服务管理。您也无法直接控制服务在任何时间点调用函数时使用哪些可用区
此抽象可帮助您专注于应用程序的集成方面、数据流,以及工作负载为最终用户提供价值的业务逻辑。允许服务管理底层机制可以帮助您更快地开发应用程序,并减少需要维护的自定义代码。
在函数中实施无状态性
对于标准 Lambda 函数时,您应假设环境仅存在于单次调用中。函数应在首次启动时初始化所有必需的状态。例如,您的函数可能需要从 DynamoDB 表提取数据。在退出之前,它应将任何永久性数据更改提交到持久存储(例如 Amazon S3、DynamoDB 或 Amazon SQS)。它不应依赖任何现有的数据结构或临时文件,也不应依赖将由多次调用管理的任何内部状态。
要初始化数据库连接和库或加载状态,可以利用静态初始化。由于尽可能重复使用执行环境以提高性能,因此您可以通过多次调用来分摊初始化这些资源所花的时间。但是,不应该在此全局范围内存储函数中使用的任何变量或数据。
最小化耦合
大多数架构应首选大量且较短的函数,而不是少量且较大的函数。每个函数的目的应该是处理传递到函数中的事件,而无需了解或预期整体工作流或事务量。这使得该函数与事件源无关,与其他服务的耦合最少。
任何不经常更改的全局范围常量都应作为环境变量来实施,以便无需部署即可进行更新。任何机密或敏感信息都应存储在 Amazon Systems Manager Parameter Store 或 Amazon Secrets Manager
为按需数据而非批量数据构建
许多传统系统旨在定期运行并处理随着时间而积累的批量事务。例如,银行应用程序可能每小时运行一次,将 ATM 交易处理到中央分类账。在基于 Lambda 的应用程序中,自定义处理应由每个事件触发,从而允许服务根据需要纵向扩展并发,以提供近乎实时的事务处理。
虽然标准 Lambda 函数的执行时间限制在 15 分钟以内,但持久性函数的运行时间最长可达一年,因此非常适合长时间运行的处理需求。然而,在可能的情况下,您仍应优先选择事件驱动型处理而非批量处理。
虽然您可以在 Amazon EventBridge 中使用规则的计划表达式在无服务器应用程序中运行 cron
例如,使用触发 Lambda 函数的批量处理来获取新 Amazon S3 对象列表并不是最佳实践。这是因为该服务在批处理之间接收的新对象可能比在 15 分钟的 Lambda 函数内处理的要多。
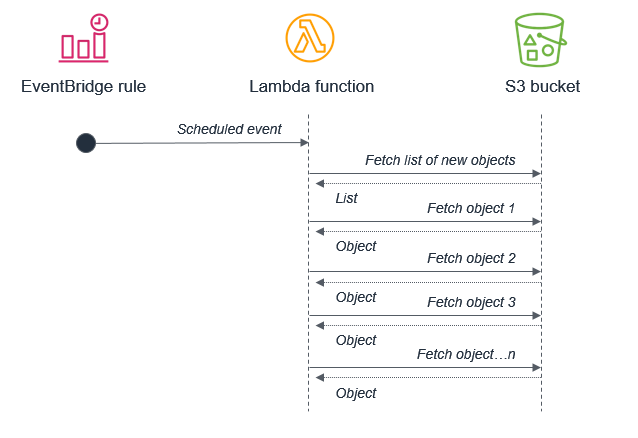
相反,每次将新对象放入存储桶时,Amazon S3 都应该调用 Lambda 函数。此方法的可扩展性要高得多,且可以近乎实时地工作。
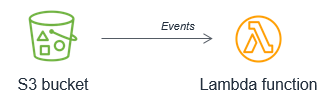
为复杂的工作流选择编排选项
涉及分支逻辑、不同类型的故障模型和重试逻辑的工作流通常使用编排工具来跟踪整体执行的状态。请勿在标准 Lambda 函数中构建临时编排。这会导致紧密耦合、复杂的路由代码以及无自动状态恢复。
请改用下面其中一个专门构建的编排选项:
-
Lambda 持久性函数:使用标准编程语言进行以应用程序为中心的编排,具有自动检查点机制、内置重试和执行恢复功能。非常适合那些喜欢将工作流逻辑与 Lambda 中的业务逻辑一起保留在代码中的开发人员。
-
Amazon Step Functions:可视化工作流编排,与 220 多种 Amazon 服务本机集成。非常适合多服务协调、零维护基础设施和可视化工作流设计。
有关在这些选项之间进行选择的指导,请参阅持久性函数或 Step Functions。
使用 Step Functions
随着时间的推移,Lambda 函数中较简单的工作流程通常会变得越来越复杂。在操作生产无服务器应用程序时,识别何时发生这种情况非常重要,这样您就可以将此逻辑迁移到状态机或持久性函数。
实施幂等性
包括 Lambda 在内的 Amazon 无服务器服务具有容错能力,并且专为处理故障而设计。例如,如果某项服务调用 Lambda 函数并且出现服务中断,则 Lambda 会在不同的可用区中调用您的函数。如果您的函数引发错误,则 Lambda 将重试调用。
由于同一事件可能会被多次接收,因此函数应该设计为幂等性
您可以使用 DynamoDB 表跟踪最近处理的标识符,从而在 Lambda 函数中实施幂等性,以确定之前是否处理过事务。DynamoDB 表通常会实施生存时间(TTL)值来使项目过期,以限制使用的存储空间。
使用多个 Amazon 账户管理配额
Amazon 中的许多服务配额都是在账户级别设置。这意味着,添加更多的工作负载时,您的限额可迅速耗尽。
解决此问题的有效方法是使用多个 Amazon 账户,将每个工作负载专用于自身账户。这样可以防止与其他工作负载或非生产资源一起共享配额。
此外,使用 Amazon Organizations
一种常见的方法是为每位开发人员提供一个 Amazon 账户,然后在测试版部署阶段和生产阶段使用不同的账户:
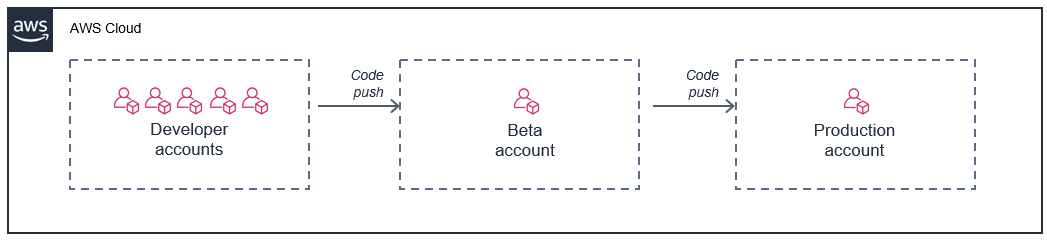
在此模型中,每个开发人员都有自己的一组账户限制,因此他们的使用不会影响您的生产环境。这种方法还允许开发人员在开发机器上根据个人账户中的实时云资源在本地测试 Lambda 函数。