本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
# Gremlin 加载数据格式
要使用 CSV 格式加载 Apache TinkerPop Gremlin 数据,必须在单独的文件中指定顶点和边。
加载程序可以在单个加载任务中从多个顶点文件和多个边缘文件加载。
对于每个加载命令,要加载的文件集必须与 Amazon S3 桶位于同一文件夹中,并且为 `source` 参数指定文件夹名称。文件名和文件扩展名不重要。
Amazon Neptune CSV 格式遵循 RFC 4180 CSV 规范。有关更多信息,请参阅 Internet Engineering Task Force (IETF) 网站上的 [CSV 文件的一般格式和 MIME 类型](https://tools.ietf.org/html/rfc4180)。
**注意**
所有文件必须采用 UTF-8 格式编码。
每个文件都包含一个逗号分隔的标题行。此标题行由系统列标题和属性列标题组成。
## 系统列标题
顶点文件和边文件需要和允许的系统列标题不同。
每个系统列在标题中只能出现一次。
所有标签都区分大小写。
**顶点标题**
+ `~id` - **必需**
顶点的 ID。
+ `~label`
顶点的标签。允许使用多个标签值,用分号 (`;`) 分隔。
如果不存在,`~label`则为标签 TinkerPop 提供该值`vertex`,因为每个顶点都必须至少有一个标签。
**边标题**
+ `~id` - **必需**
边的 ID。
+ `~from` - **必需**
*源* 顶点的顶点 ID。
+ `~to` - **必需**
*目标* 顶点的顶点 ID。
+ `~label`
边的标签。边只能具有单个标签。
如果不存在,`~label`则为标签 TinkerPop 提供该值`edge`,因为每条边都必须有一个标签。
## 属性列标题
可通过使用以下语法指定属性的列 (`:`)。类型名称不区分大小写。但请注意,如果属性名称中出现冒号,则必须在其前面加上反斜杠来对其进行转义:`\:`。
```
{{propertyname}}:{{type}}
```
**注意**
不允许在列标题中使用空格、逗号、回车和换行符,因此属性名称不得包含这些字符。
您可以通过将 `[]` 添加到类型来指定数组列:
```
{{propertyname}}:{{type}}[]
```
**注意**
边缘属性只能有一个值,如果指定了数组类型或指定了另一个值,则会导致错误。
以下示例显示了名为 `age`、类型为 `Int` 的属性的列标题。
```
age:Int
```
文件中的每行都需要在该位置具有整数或保留为空。
允许使用字符串数组,但是数组中的字符串不能包含分号 (`;`) 字符,除非使用反斜杠对其进行转义(如 `\;`)。
**指定列的基数**
列标题可用于为该列标识的属性指定*基数*。这使得批量加载程序可以按照类似于 Gremlin 请求所用的方法来遵循基数。
可以如下所示指定列的基数:
```
{{propertyname}}:{{type}}({{cardinality}})
```
该{{cardinality}}值可以是 `single` 或`set`。默认值为 `set`,表示列可以接受多个值。对于边缘文件,基数始终是单一的,并且指定任何其他基数都会导致加载程序引发异常。
当基数是 `single` 时,如果加载某个值时以前的值已存在,或者如果加载了多个值,则加载程序引发错误。此行为可以覆盖,因此在使用 `updateSingleCardinalityProperties` 标记加载新值时,将替换现有值。请参阅[加载程序命令](load-api-reference-load.md)。
可以将基数设置用于数组类型,虽然通常并不需要这样做。以下是可能的组合:
+ `name:type` – 基数为 `set`,内容为单值。
+ `name:type[]` – 基数为 `set`,内容为多值。
+ `name:type(single)` – 基数为 `single`,内容为单值。
+ `name:type(set)` – 基数为 `set`,这与默认值相同,内容为单值。
+ `name:type(set)[]` – 基数为 `set`,内容为多值。
+ `name:type(single)[]` – 这自相矛盾,导致引发错误。
以下部分列出了所有可用 Gremlin 数据类型。
## Gremlin 数据类型
下面列出了允许的属性值,以及对每种类型的描述。
**Bool (或 Boolean)**
指示 Boolean 字段。允许的值:`false`、`true`
**注意**
`true` 以外的任何值都将被视为 False。
**整数类型**
超出所定义范围的值将导致错误。
|
|
| Type | Range |
| --- |--- |
| 字节 | -128 到 127 |
| 短型 | -32768 到 32767 |
| Int | -2^31 到 2^31-1 |
| Long | -2^63 到 2^63-1 |
**小数类型**
支持十进制记数法或科学记数法。此外允许使用符号 [如 (\+/-) Infinity 或 NaN]。不支持 INF。
|
|
| Type | Range |
| --- |--- |
| 浮点型 | 32 位 IEEE 754 浮点 |
| 双精度 | 64 位 IEEE 754 浮点 |
对于太长的浮点值和双精度值,将加载并四舍五入到最近的 24 位 (浮点) 和 53 位 (双精度) 值。对于位级别的最后剩余数位,中间值将四舍五入到 0。
**字符串**
引号是可选的。如果双引号 (`"`) 括起来的字符串中包含逗号字符、换行符和回车符,则将自动对这些字符进行转义。*示例*:`"Hello, World"`
要在用引号引起来的字符串中包含引号,可通过在一行中使用两个引号来对引号进行转义:*示例:*`"Hello ""World"""`
允许使用字符串数组,但是数组中的字符串不能包含分号 (`;`) 字符,除非使用反斜杠对其进行转义(如 `\;`)。
如果要使用引号将数组内的字符串括起来,则必须使用一组引号将整个数组括起来。*示例*:`"String one; String 2; String 3"`
**日期**
ISO-8601 格式的Java 日期。支持以下格式:`yyyy-MM-dd`、`yyyy-MM-ddTHH:mm`、`yyyy-MM-ddTHH:mm:ss`、`yyyy-MM-ddTHH:mm:ssZ`。这些值将转换为 epoch 时间并进行存储。
**日期时间**
ISO-8601 格式的Java 日期。支持以下格式:`yyyy-MM-dd`、`yyyy-MM-ddTHH:mm`、`yyyy-MM-ddTHH:mm:ss`、`yyyy-MM-ddTHH:mm:ssZ`。这些值将转换为 epoch 时间并进行存储。
## Gremlin 行格式
**分隔符**
行中的字段是用逗号分隔的。记录是用换行符或换行符后跟回车符来分隔的。
**空白字段**
非必需列 (如用户定义的属性) 允许使用空白字段。空白字段仍需要逗号分隔符。必填列上的空白字段将导致解析错误。空字符串值将被解读为该字段的空字符串值;而不是空白字段。下一节中的示例在每个示例顶点中都有一个空白字段。
**Vertex IDs**
每个顶点文件中所有顶点的 `~id` 值都必须是唯一的。`~id` 值相同的多个顶点行适用于图形中的单个顶点。空字符串(`""`)是有效的 ID,顶点便是使用空字符串作为 ID 创建的。
**边缘 IDs**
此外,每个边文件中所有边的 `~id` 值都必须是唯一的。`~id` 值相同的多个边行适用于图形中的单个边。空字符串(`""`)是有效的 ID,边缘便是使用空字符串作为 ID 创建的。
**标签**
标签区分大小写,不能为空。值为 `""` 将导致错误。
**字符串值**
引号是可选的。如果双引号 (`"`) 括起来的字符串中包含逗号字符、换行符和回车符,则将自动对这些字符进行转义。空字符串值 `("")` 将被解读为该字段的空字符串值;而不是空白字段。
## CSV 格式规范
Neptune CSV 格式遵循 RFC 4180 CSV 规范,其中包含以下要求。
+ 支持 Unix 和 Windows 样式行结尾 (\\n 或 \\r\\n)。
+ 任何字段都可以使用引号引起来 (使用双引号)。
+ 包含换行符、双引号或逗号的字段必须用引号引起来。(如果未引起来,加载将立即中止。)
+ 字段中的双引号字符 (`"`) 必须用两个 (双) 引号字符表示。例如,字符串在数据中 `Hello "World"` 必须显示为 `"Hello ""World"""`。
+ 将忽略分隔符之间的周围空格。如果某个行显示为 `value1, value2`,则它们将以 `"value1"` 和 `"value2"` 的形式进行存储。
+ 任何其他转义字符将以逐字字符串形式存储。例如,`"data1\tdata2"` 将以 `"data1\tdata2"` 的形式存储。只要这些字符围在引号内,就不需要任何其他转义。
+ 允许使用空白字段。空白字段将视为空值。
+ 字段的多个值是在值之间使用分号 (`;`) 来指定的。
有关更多信息,请参阅 Internet Engineering Task Force (IETF) 网站上的 [CSV 文件的一般格式和 MIME 类型](https://tools.ietf.org/html/rfc4180)。
## Gremlin 示例
下图显示了取自 TinkerPop 现代图的两个顶点和一条边的示例。
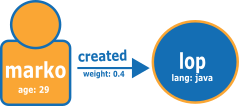
以下是 Neptune CSV 加载格式的图形。
顶点文件:
```
~id,name:String,age:Int,lang:String,interests:String[],~label
v1,"marko",29,,"sailing;graphs",person
v2,"lop",,"java",,software
```
顶点文件的表格视图:
| | | | | | |
| --- |--- |--- |--- |--- |--- |
| \~id | name:String | age:Int | lang:String | 兴趣:字符串 [] | \~label |
| v1 | "marko" | 29 | | [“帆船”,“图表”] | person |
| v2 | "lop" | | "java" | | 软件 |
边文件:
```
~id,~from,~to,~label,weight:Double
e1,v1,v2,created,0.4
```
边文件的表格视图:
| | | | | |
| --- |--- |--- |--- |--- |
| \~id | \~from | \~到 | \~label | weight:Double |
| e1 | v1 | v2 | created | 0.4 |
**后续步骤**
现在要了解有关加载格式的更多信息,请参阅[示例:将数据加载到 Neptune 数据库实例中](bulk-load-data.md)。