本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
Amazon OpenSearch 服务的自动语义丰富
简介
与其他传统搜索引擎类似,Amazon S OpenSearch ervice 使用单词匹配(词法搜索)来查找结果。这种方法适用于产品代码或型号等特定查询,但在抽象搜索中很难理解用户意图。例如,当您搜索 “沙滩鞋” 时,词汇搜索会匹配目录商品中的单个单词 “鞋子”、“沙滩”、“for” 和 “the”,这可能会缺少不包含确切搜索词的相关商品,例如 “防水凉鞋” 或 “冲浪鞋”。
自动语义扩充通过考虑关键字匹配和搜索背后的上下文含义来解决这一限制。此功能可理解搜索意图,并将搜索相关性提高多达 20%。为索引中的文本字段启用此功能可增强搜索结果。
注意
运行版本 2.19 或更高版本的 OpenSearch 服务域可以使用自动语义扩充。此外, OpenSearch 版本为 2.19 的域名还需要使用最新的服务软件版本更新。目前,该功能适用于公共域,不支持 VPC 域。
型号详情和性能基准
虽然此功能可以在不公开底层模型的情况下处理幕后的技术复杂性,但我们通过简短的模型描述和基准测试结果提供透明度,以帮助您就关键工作负载中的功能采用做出明智的决定。
自动语义丰富使用服务托管、预训练的稀疏模型,无需自定义微调即可有效运行。该模型分析您指定的字段,根据从各种训练数据中学到的关联将它们扩展为稀疏向量。扩展后的术语及其显著性权重以原生 Lucene 索引格式存储,便于高效检索。我们已经使用仅限文档模式优化了此过程,在这种模式下,
我们在功能开发期间的性能验证使用了 MS MARCO
-
英语-与词汇搜索相比,相关性提高了20%。与词法搜索相比,它还将P90的搜索延迟降低了7.7%(BM25为26毫秒,自动语义丰富为24毫秒)。
-
Multi-lingual -与词法搜索相比,相关性提高了105%,而P90搜索延迟比词汇搜索增加了38.4%(BM25为26毫秒,自动语义丰富为36毫秒)。
鉴于每种工作负载的独特性,我们鼓励您在做出实施决策之前,使用自己的基准测试标准在开发环境中评估此功能。
支持的语言
该功能支持英语。此外,该模型还支持阿拉伯语、孟加拉语、中文、芬兰语、法语、印地语、印度尼西亚语、日语、韩语、波斯语、俄语、西班牙语、斯瓦希里语和泰卢固语。
为域名设置自动语义丰富索引
为文本字段设置启用自动语义丰富功能的索引非常简单,而且在创建新索引期间,您可以通过控制台、API 和 Amazon CloudFormation 模板对其进行管理。要为现有索引启用该功能,您需要在为文本字段启用自动语义丰富功能的情况下重新创建索引。
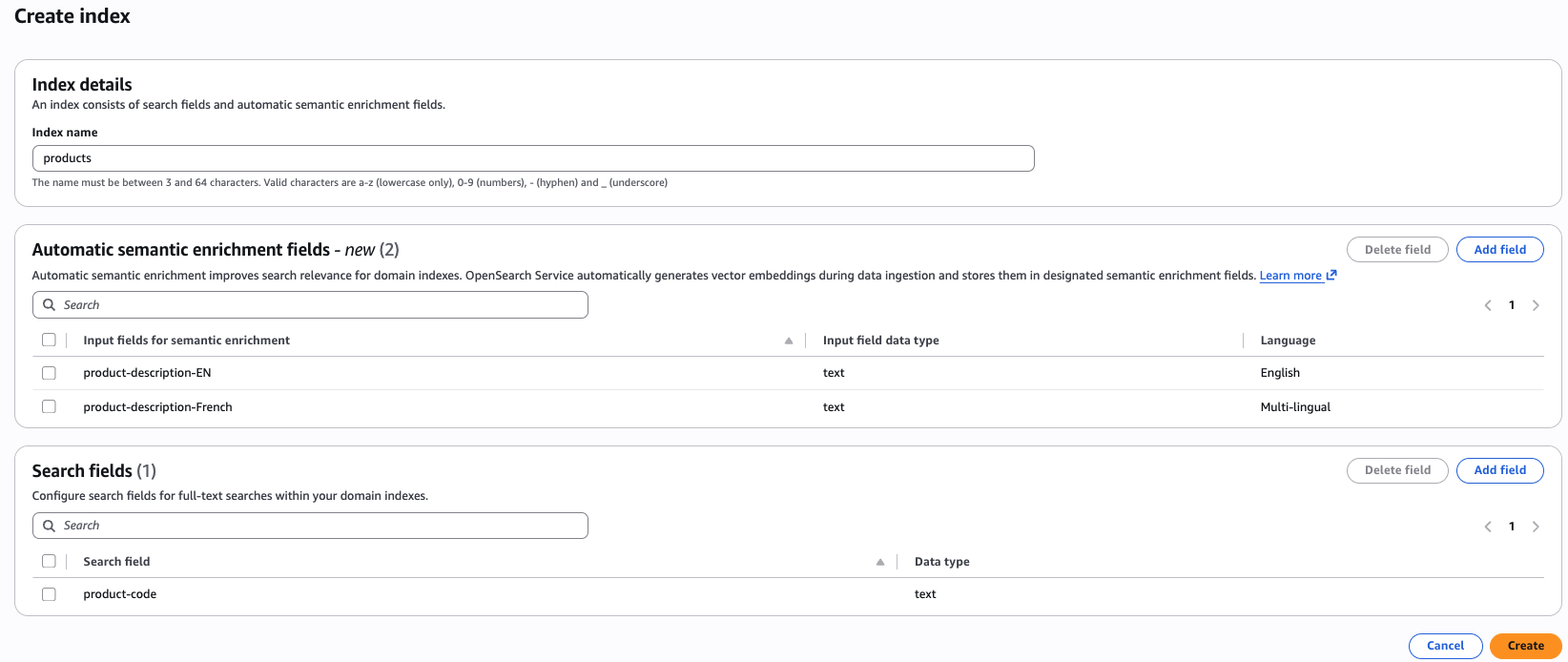
控制台体验- Amazon 控制台允许您轻松创建带有自动语义丰富字段的索引。选择域名后,您将在控制台顶部找到 “创建索引” 按钮。单击 “创建索引” 按钮后,您将找到用于定义自动语义丰富字段的选项。在一个索引中,您可以组合英语和多语言的自动语义扩充以及词汇字段。
API 体验-要使用 Amazon 命令行界面 (Amazon CLI) 创建自动语义丰富索引,请使用 create-index 命令:
aws opensearch create-index \ --domain-name [domain_name] \ --index-name [index_name] \ --index-schema [index_body] \
在以下示例索引架构中,t itle_semantic 字段的字段类型设置为文本,并将参数 semantic_ enrichmentic_enrichmentic 设置为 “已启用” 状态。设置 s emantic_enrichmentic_ entrich 参数可以自动扩充标题_语义字段。您可以使用 l anguage_option s 字段来指定英语或。MULTI-LINGUAL
aws opensearch create-index \ --id XXXXXXXXX \ --index-name 'product-catalog' \ --index-schema '{ "mappings": { "properties": { "product_id": { "type": "keyword" }, "title_semantic": { "type": "text", "semantic_enrichment": { "status": "ENABLED", "language_options": "english" } }, "title_non_semantic": { "type": "text" } } } }'
要描述创建的索引,请使用以下命令:
aws opensearch get-index \ --domain-name [domain_name] \ --index-name [index_name] \
更新现有索引
您可以更新现有索引以添加新的语义丰富字段,在现有字段上启用或禁用语义丰富功能,或者添加非语义文本字段。使用update-index命令并在中仅提供要更改的字段index-schema。请求中未包含的字段保持不变。
注意
settings无法更新索引。如果您在请求中包含一个settings块,则该操作会返回验证错误。要更改索引设置,必须删除并重新创建索引。
要使用更新索引 Amazon CLI,请使用以下update-index命令:
aws opensearch update-index \ --domain-name [domain_name] \ --index-name [index_name] \ --index-schema [index_body]
添加新的语义丰富字段
您可以向现有索引添加启用语义丰富功能的新text字段。该服务会自动设置所需的机器学习模型、采集管道和搜索管道。更新后编入索引的新文档会自动丰富。
重要
现有文档不会回填。要在现有文档上填充语义丰富字段,必须在更新后重新收录它们。在重新摄取之前,现有文档将无法从新字段的语义搜索中受益。
aws opensearch update-index \ --domain-name my-domain \ --index-name product-catalog \ --index-schema '{ "mappings": { "properties": { "description": { "type": "text", "semantic_enrichment": { "status": "ENABLED", "language_options": "english" } } } } }'
在字段上禁用语义丰富
要在当前启用语义丰富功能的字段上禁用语义扩展,请将其设置status为。DISABLED该字段已从采集和搜索管道中移除。基础文本字段及其嵌入字段保留在索引中,但不再丰富。
aws opensearch update-index \ --domain-name my-domain \ --index-name product-catalog \ --index-schema '{ "mappings": { "properties": { "title_semantic": { "type": "text", "semantic_enrichment": { "status": "DISABLED" } } } } }'
更新限制
索引不支持以下操作,需要您删除并重新创建索引:update-index
-
language_options在当前启用语义丰富功能的字段上进行@@ 更改。先禁用该字段,然后使用新的语言选项将其重新启用。 -
更新嵌套字段。仅顶级
text字段支持语义扩充。 -
正在更新索引
settings。
注意
如果索引的自定义采集或搜索管道不是通过自动语义丰富创建的,则更新操作将被阻止。在添加语义丰富字段之前,请移除自定义管道。
数据摄取和搜索
创建启用了自动语义扩充功能的索引后,该功能将在数据摄取过程中自动运行,无需进行其他配置。
数据摄取:当您将文档添加到索引中时,系统会自动:
-
分析您为丰富语义而指定的文本字段
-
使用 OpenSearch 服务托管稀疏模型生成语义编码
-
将这些丰富的表示法与您的原始数据一起存储
此过程使用内置 OpenSearch的 ML 连接器和采集管道,这些管道是在后台自动创建和管理的。
搜索:语义丰富数据已编制索引,因此查询无需再次调用 ML 模型即可高效运行。这意味着您可以提高搜索相关性,而不会产生额外的搜索延迟开销。
为自动语义增强配置权限
在创建具有自动语义丰富功能的索引之前,您需要配置所需的权限。本节介绍不同索引操作所需的权限,以及如何为 Amazon Identity and Access Management (IAM) 和精细访问控制场景设置这些权限。
IAM 权限
自动语义丰富操作需要以下 IAM 权限。这些权限因您要执行的特定索引操作而异。
CreateIndex API 权限
要创建具有自动语义丰富功能的索引,您需要以下 IAM 权限:
-
es:CreateIndex— 创建具有语义丰富功能的索引。 -
es:ESHttpHead— 执行 HEAD 请求以检查索引是否存在。 -
es:ESHttpPut— 执行 PUT 请求以创建索引。 -
es:ESHttpPost— 执行索引操作的 POST 请求。
UpdateIndex API 权限
要使用自动语义丰富功能更新现有索引,您需要以下 IAM 权限:
-
es:UpdateIndex— 更新索引设置和映射。 -
es:ESHttpPut— 执行索引更新的 PUT 请求。 -
es:ESHttpGet— 执行 GET 请求以检索索引信息。 -
es:ESHttpPost— 执行索引操作的 POST 请求。
GetIndex API 权限
要通过自动语义丰富功能检索有关索引的信息,您需要以下 IAM 权限:
-
es:GetIndex— 检索索引信息和设置。 -
es:ESHttpGet— 执行 GET 请求以检索索引数据。
DeleteIndex API 权限
要使用自动语义丰富功能删除索引,您需要以下 IAM 权限:
-
es:DeleteIndex— 删除索引及其语义丰富组件。 -
es:ESHttpDelete— 执行删除索引的删除请求。
IAM 策略示例
以下基于身份的访问策略示例通过自动语义丰富为用户提供了管理索引所需的权限:
{ "Version": "2012-10-17", "Statement": [ { "Sid": "AllowSemanticEnrichmentIndexOperations", "Effect": "Allow", "Action": [ "es:CreateIndex", "es:UpdateIndex", "es:GetIndex", "es:DeleteIndex", "es:ESHttpHead", "es:ESHttpGet", "es:ESHttpPut", "es:ESHttpPost", "es:ESHttpDelete" ], "Resource": "arn:aws:es:aws-region:111122223333:domain/domain-name" } ] }
用您的特定值替换aws-region111122223333、和domain-name。您可以通过在资源 ARN 中指定特定的索引模式来进一步限制访问权限。
Fine-grained 访问控制权限
如果您的 Amazon S OpenSearch ervice 域启用了精细访问控制,则除了 IAM 权限之外,您还需要其他权限。每个索引操作都需要以下权限。
CreateIndex API 权限
启用精细访问控制后,需要以下额外权限才能创建具有自动语义丰富功能的索引:
-
indices:admin/create— 创建索引操作。 -
indices:admin/mapping/put— 创建和更新索引映射。 -
cluster:admin/opensearch/ml/create_connector— 创建用于语义处理的机器学习连接器。 -
cluster:admin/opensearch/ml/register_model— 注册机器学习模型以丰富语义。 -
cluster:admin/ingest/pipeline/put— 创建用于数据处理的采集管道。 -
cluster:admin/search/pipeline/put— 创建用于查询处理的搜索管道。
UpdateIndex API 权限
启用精细访问控制后,需要以下额外权限才能使用自动语义丰富功能更新索引:
-
indices:admin/get— 检索索引信息。 -
indices:admin/settings/update— 更新索引设置。 -
indices:admin/mapping/put— 更新索引映射。 -
cluster:admin/opensearch/ml/create_connector— 创建机器学习连接器。 -
cluster:admin/opensearch/ml/register_model— 注册机器学习模型。 -
cluster:admin/ingest/pipeline/put— 创建采集管道。 -
cluster:admin/search/pipeline/put— 创建搜索管道。 -
cluster:admin/ingest/pipeline/get— 检索采集管道信息。 -
cluster:admin/search/pipeline/get— 检索搜索管道信息。
GetIndex API 权限
启用细粒度访问控制后,需要以下额外权限才能通过自动语义丰富功能检索索索索索引的信息:
-
indices:admin/get— 检索索引信息。 -
cluster:admin/ingest/pipeline/get— 检索采集管道信息。 -
cluster:admin/search/pipeline/get— 检索搜索管道信息。
DeleteIndex API 权限
启用精细访问控制后,需要以下额外权限才能删除具有自动语义丰富功能的索引:
-
indices:admin/delete— 删除索引操作。
查询重写
自动语义丰富功能无需修改查询即可自动将现有的 “匹配” 查询转换为语义搜索查询。如果匹配查询是复合查询的一部分,则系统会遍历您的查询结构,找到匹配查询,然后将其替换为神经稀疏查询。目前,该功能仅支持替换 “匹配” 查询,无论是独立查询还是复合查询的一部分。 不支持 “多重匹配”。此外,该功能还支持所有复合查询来替换其嵌套的匹配查询。复合查询包括:bool、boosting、constant_score、dis_max、function_score 和混合。
自动语义扩充的局限性
当应用于包含自然语言内容(例如电影标题、产品描述、评论和摘要)的中小型字段时,自动语义搜索最为有效。尽管语义搜索增强了大多数用例的相关性,但它可能不是某些场景的最佳选择。在决定是否针对您的特定用例实现自动语义丰富时,请考虑以下限制。
-
很长的文档 — 当前的稀疏模型仅处理每个文档的前 8,192 个英文标记。对于多语言文档,它是 512 个代币。对于篇幅较长的文章,可以考虑实施文档分块,以确保完整的内容处理。
-
日志分析工作负载 — 语义丰富会显著增加索引大小,这对于通常需要精确匹配的日志分析来说可能是不必要的。额外的语义上下文很少能提高日志搜索的有效性,足以证明存储需求的增加是合理的。
-
自动语义丰富与 “派生来源” 功能不兼容。
-
限制 — 服务域的索引推理请求目前上限为 200 TPS。 OpenSearch 这是一个软限制;如需更高的限额,请联系 Su Amazon pport。
定价
Amazon S OpenSearch ervic OpenSearch e 根据索引时稀疏向量生成过程中消耗的计算单位 (OCU) 自动计费语义扩充费用。您只需为启用自动语义丰富功能的文本字段编制索引期间的实际使用量付费。一个语义搜索 OCU 可以处理 1110 万个英语内容令牌。要处理24亿个代币,你需要大约216个语义搜索 OCU-hours (24亿/110万个)。每次语义搜索的价格为0.24美元 OCU-hour,处理10 GB数据以进行自动语义搜索的成本为51美元(216 x 0美元)。 OCU-hours 24/OCU-小时)。在搜索操作或数据存储期间,无需支付额外的语义搜索 OCU 费用。
您可以使用 Amazon CloudWatch 指标监控此消费SemanticSearchOCU。有关模型代币限制、每个 OCU 的吞吐量以及示例计算示例的具体详细信息,请访问OpenSearch 服务定价