本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
Amazon ParallelCluster 进程
本节仅适用于使用支持的传统作业调度器之一部署的 HPC 集群 (SGE, Slurm,或 Torque)。 与这些调度器一起使用时,通过与 Amazon ParallelCluster Auto Scaling 组和底层作业调度器交互来管理计算节点的配置和移除。
对于基于的 HPC 集群 Amazon Batch, Amazon ParallelCluster 依赖于提供的 Amazon Batch 计算节点管理功能。
注意
从 2.11.5 版开始, Amazon ParallelCluster 不支持使用 SGE 或 Torque 调度器。您可以在 2.11.4 及之前的版本中继续使用它们,但它们没有资格获得 Amazon 服务和支持团队的未来更新或故障排除 Amazon 支持。
SGE and Torque integration processes
注意
本节仅适用于 Amazon ParallelCluster 2.11.4 及以下的版本。从 2.11.5 版开始, Amazon ParallelCluster 不支持使用 SGE 以及 Torque 调度程序、亚马逊 SNS 和亚马逊 SQS。
一般概述
集群的生命周期在用户创建集群后开始。通常,从命令行界面 (CLI) 创建集群。集群创建后会一直存在,直到它被删除。 Amazon ParallelCluster 守护程序在群集节点上运行,主要是为了管理 HPC 集群的弹性。下图显示了用户工作流程和集群生命周期。以下各节描述了用于管理集群的 Amazon ParallelCluster 守护程序。
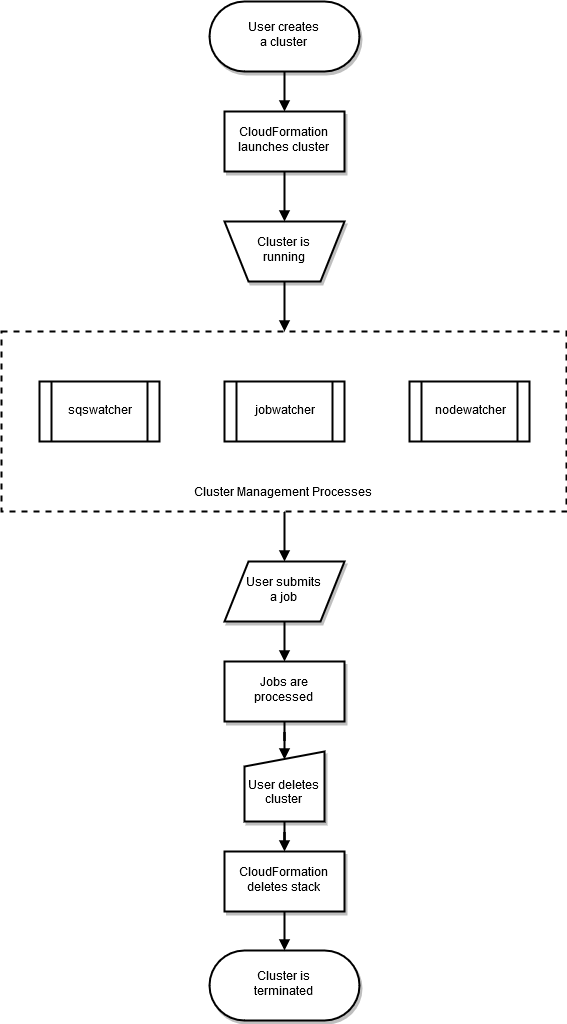
With SGE 以及 Torque 调度器nodewatcherjobwatcher、 Amazon ParallelCluster 使用和sqswatcher进程。
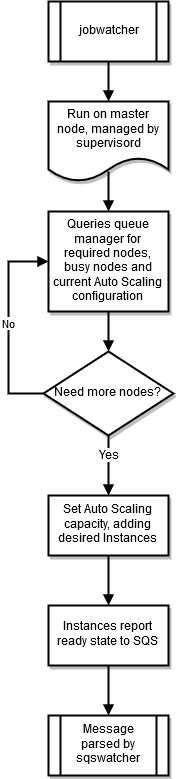
jobwatcher
集群运行时,root 用户拥有的进程会监视配置的调度程序 (SGE 或 Torque)。 它每分钟都会评估队列,以决定何时扩大规模。
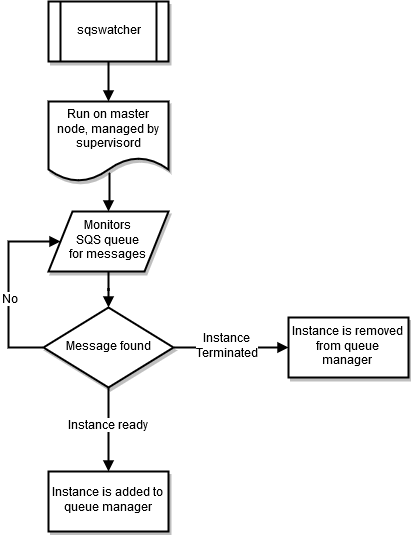
sqswatcher
sqswatcher 进程监控由 Auto Scaling 发送的 Amazon SQS 消息,这会告知您集群内的状态更改。当一个实例联机时,它会向 Amazon SQS 提交“实例就绪”消息。此消息由运行于头节点上的 sqs_watcher 接收。这些消息用于通知队列管理员有新实例联机或遭到终止,以便能够在队列中添加或删除它们。
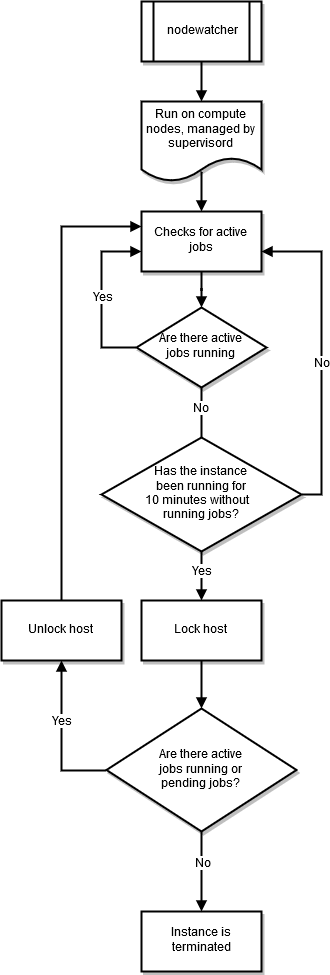
nodewatcher
nodewatcher 进程在计算队列中的每个节点上运行。在用户定义的 scaledown_idletime 期间之后,实例将终止。
Slurm integration processes
With Slurm 调度程序、 Amazon ParallelCluster 用途clustermgtd和computemgt进程。
clustermgtd
在异构模式(通过指定 queue_settings 值来指示)下运行的集群具有在头节点上运行的集群管理进程守护程序 (clustermgtd) 进程。以下任务由集群管理进程守护程序执行。
-
非活动分区清理
-
静态容量管理:确保静态容量始终处于正常运行状态
-
将计划程序与 Amazon EC2 同步。
-
孤立实例清理
-
在暂停工作流程之外发生的 Amazon EC2 终止时恢复计划程序节点状态
-
Amazon EC2 实例管理不正常(亚马逊运行 EC2 状况检查失败)
-
定期维护事件管理
-
不正常调度器节点管理(调度器运行状况检查失败)
computemgtd
在异构模式(通过指定 queue_settings 值来指示)下运行的集群具有在每个计算节点上运行的计算管理进程守护程序 (computemgtd) 进程。每隔五 (5) 分钟,计算管理进程守护程序就会确认头节点可以访问并且运行正常。如果在五 (5) 分钟内无法访问头节点或头节点运行状况不佳,则将关闭计算节点。