从补丁 198 开始,Amazon Redshift 将不再支持创建新的 Python UDF。现有的 Python UDF 将继续正常运行至 2026 年 6 月 30 日。有关更多信息,请参阅博客文章
从 Amazon EMR 中加载数据
您可以使用 COPY 命令从一个具有如下配置的 Amazon EMR 集群并行加载数据:将文本文件作为固定宽度文件、字符分隔文件、CSV 文件或 JSON 格式文件写入到集群的 Hadoop Distributed File System (HDFS)。
从 Amazon EMR 中加载数据的过程
本节演练从 Amazon EMR 集群加载数据的过程。以下各节提供您必须完成每个步骤的详细信息。
-
用户必须拥有必要的权限才能创建 Amazon EMR 集群和运行 Amazon Redshift COPY 命令。
-
将集群配置为将文本文件输出到 Hadoop Distributed File System (HDFS)。您需要 Amazon EMR 集群 ID 和集群的主节点公有 DNS(托管集群的 Amazon EC2 实例的端点)。
-
步骤 3:检索 Amazon Redshift 集群公有密钥和集群节点 IP 地址
公有密钥使 Amazon Redshift 集群节点能够建立与主机的 SSH 连接。您将使用每个集群节点的 IP 地址来配置主机安全组,从而允许使用这些 IP 地址从 Amazon Redshift 集群访问。
-
步骤 4:将 Amazon Redshift 集群公有密钥添加到每个 Amazon EC2 主机的授权密钥文件
您将 Amazon Redshift 集群公有密钥添加到主机的授权密钥文件,以便让主机识别 Amazon Redshift 集群并接受 SSH 连接。
-
步骤 5:将主机配置为接受 Amazon Redshift 集群的所有 IP 地址
修改 Amazon EMR 实例的安全组,以添加接受 Amazon Redshift IP 地址的输入规则。
-
从 Amazon Redshift 数据库运行 COPY 命令,以便将数据加载到 Amazon Redshift 表中。
步骤 1:配置 IAM 权限
用户必须拥有必要的权限才能创建 Amazon EMR 集群和运行 Amazon Redshift COPY 命令。
配置 IAM 权限
-
为将要创建 Amazon EMR 集群的用户添加以下权限。
ec2:DescribeSecurityGroups ec2:RevokeSecurityGroupIngress ec2:AuthorizeSecurityGroupIngress redshift:DescribeClusters -
为将要运行 COPY 命令的 IAM 角色或用户添加以下权限。
elasticmapreduce:ListInstances -
向 Amazon EMR 集群的 IAM 角色添加以下权限。
redshift:DescribeClusters
步骤 2:创建 Amazon EMR 集群
COPY 命令从 Amazon EMR Hadoop Distributed File System (HDFS) 上的文件加载数据。当您创建 Amazon EMR 集群时,请将集群配置为将数据文件输出到集群的 HDFS。
要创建 Amazon EMR 集群
-
在与 Amazon Redshift 集群相同的 Amazon 区域中创建 Amazon EMR 集群。
如果 Amazon Redshift 集群在 VPC 中,则 Amazon EMR 集群必须在同一 VPC 组中。如果 Amazon Redshift 集群使用 EC2-Classic 模式(即,它不在 VPC 中),则 Amazon EMR 集群必须也使用 EC2-Classic 模式。有关更多信息,请参阅《Amazon Redshift 管理指南》中的管理 Virtual Private Cloud (VPC) 中的集群。
-
将集群配置为将数据文件输出到集群的 HDFS。HDFS 文件名不能包括星号 (*) 或问号 (?)。
重要
文件名不能包括星号 (*) 或问号 (?)。
-
在 Amazon EMR 集群配置中,将自动终止选项指定为否,以便集群在 COPY 命令运行时保持可用。
重要
如果在 COPY 完成前更改或删除了任何数据文件,则您可能会遇到意外结果,或者 COPY 操作可能失败。
-
请记下集群 ID 和主节点公有 DNS(托管集群的 Amazon EC2 实例的端点)。您将在后面的步骤中用到这些信息。
步骤 3:检索 Amazon Redshift 集群公有密钥和集群节点 IP 地址
您将使用每个集群节点的 IP 地址来配置主机安全组,从而允许使用这些 IP 地址从 Amazon Redshift 集群访问。
要使用控制台为您的集群检索 Amazon Redshift 集群公有密钥和集群节点 IP 地址
-
访问 Amazon Redshift 管理控制台。
-
在导航窗格中选择集群链接。
-
从列表中选择您的集群。
-
找到 SSH 数据摄取组。
记下 Cluster Public Key 和 Node IP addresses 中的值。您将在后面的步骤中用到它们。
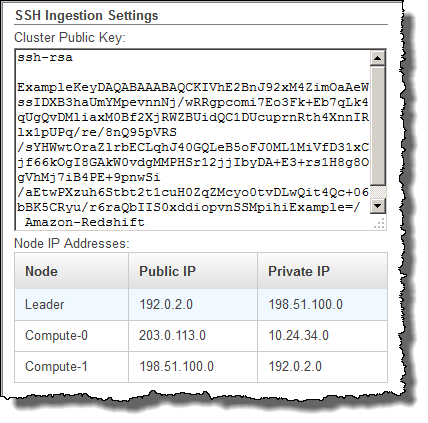
您将使用步骤 3 中的私有 IP 地址将 Amazon EC2 主机配置为接受来自 Amazon Redshift 的连接。
若要使用 Amazon Redshift CLI 检索您的集群的集群公有密钥和集群节点 IP 地址,请运行 describe-clusters 命令。例如:
aws redshift describe-clusters --cluster-identifier <cluster-identifier>
响应将包括 ClusterPublicKey 值和私有 IP 地址及公有 IP 地址的列表,类似于以下内容:
{ "Clusters": [ { "VpcSecurityGroups": [], "ClusterStatus": "available", "ClusterNodes": [ { "PrivateIPAddress": "10.nnn.nnn.nnn", "NodeRole": "LEADER", "PublicIPAddress": "10.nnn.nnn.nnn" }, { "PrivateIPAddress": "10.nnn.nnn.nnn", "NodeRole": "COMPUTE-0", "PublicIPAddress": "10.nnn.nnn.nnn" }, { "PrivateIPAddress": "10.nnn.nnn.nnn", "NodeRole": "COMPUTE-1", "PublicIPAddress": "10.nnn.nnn.nnn" } ], "AutomatedSnapshotRetentionPeriod": 1, "PreferredMaintenanceWindow": "wed:05:30-wed:06:00", "AvailabilityZone": "us-east-1a", "NodeType": "dc2.large", "ClusterPublicKey": "ssh-rsa AAAABexamplepublickey...Y3TAl Amazon-Redshift", ... ... }
要使用 Amazon Redshift API 检索您的集群的集群公有密钥和集群节点 IP 地址,请使用 DescribeClusters 操作。有关更多信息,请参阅《Amazon Redshift CLI 指南》中的 describe-clusters 或《Amazon Redshift API 指南》中的 DescribeClusters。
步骤 4:将 Amazon Redshift 集群公有密钥添加到每个 Amazon EC2 主机的授权密钥文件
您将所有 Amazon EMR 集群节点的集群公有密钥添加到每个主机的授权密钥文件,以便主机识别 Amazon Redshift 并接受 SSH 连接。
要将 Amazon Redshift 集群公有密钥添加到主机的授权密钥文件
-
使用 SSH 连接访问主机。
有关使用 SSH 连接到实例的信息,请参阅《Amazon EC2 用户指南》中的连接到您的实例。
-
从控制台或从 CLI 响应文本复制 Amazon Redshift 公有密钥。
-
将公有密钥的内容复制并粘贴到主机上的
/home/<ssh_username>/.ssh/authorized_keys文件中。请包括完整字符串(包含前缀“ssh-rsa”和后缀“Amazon-Redshift”)。例如:ssh-rsa AAAACTP3isxgGzVWoIWpbVvRCOzYdVifMrh… uA70BnMHCaMiRdmvsDOedZDOedZ Amazon-Redshift
步骤 5:将主机配置为接受 Amazon Redshift 集群的所有 IP 地址
若要允许到主机实例的入站流量,请编辑安全组并为每个 Amazon Redshift 集群节点添加一个入站规则。对于 Type,请选择在端口 22 上使用 TCP 协议的 SSH。对于源,请输入您在步骤 3:检索 Amazon Redshift 集群公有密钥和集群节点 IP 地址中检索的 Amazon Redshift 集群节点私有 IP 地址。有关添加规则到 Amazon EC2 安全组的信息,请参阅《Amazon EC2 用户指南》中的为您的实例授权入站流量。
步骤 6:运行 COPY 命令以加载数据
运行 COPY 命令以连接到 Amazon EMR 集群并将数据加载到 Amazon Redshift 表中。Amazon EMR 集群必须继续运行,直到 COPY 命令完成。例如,不要将集群配置为自动终止。
重要
如果在 COPY 完成前更改或删除了任何数据文件,则您可能会遇到意外结果,或者 COPY 操作可能失败。
在 COPY 命令中,指定 Amazon EMR 集群 ID 和 HDFS 文件路径及文件名。
COPY sales FROM 'emr://myemrclusterid/myoutput/part*' CREDENTIALS IAM_ROLE 'arn:aws:iam::0123456789012:role/MyRedshiftRole';
您可以使用通配符星号 (*) 和问号 (?) 作为文件名参数的一部分。例如,part* 加载文件 part-0000、part-0001,等等。如果您仅指定一个文件夹名称,则 COPY 将尝试加载该文件夹中的所有文件。
重要
如果您使用通配符或仅使用文件夹名称,请确认不会加载不需要的文件,否则 COPY 命令将失败。例如,某些流程可能会将日志文件写入到输出文件夹。