从补丁 198 开始,Amazon Redshift 将不再支持创建新的 Python UDF。现有的 Python UDF 将继续正常运行至 2026 年 6 月 30 日。有关更多信息,请参阅博客文章
从远程主机中加载数据
您可使用 COPY 命令从一个或多个远程主机并行加载数据,例如 Amazon EC2 实例或其他计算机。COPY 将连接到使用 SSH 的远程主机并在远程主机上运行命令以生成文本输出。
远程主机可以是 Amazon EC2 Linux 实例或配置为接受 SSH 连接的另一台 Unix 或 Linux 计算机。本指南假定您的远程主机是 Amazon EC2 实例。如果过程与其他计算机不同,指南中将会指出差别。
Amazon Redshift 可连接到多台主机,并可以打开到每台主机的多个 SSH 连接。Amazon Redshift 会通过每个连接发送一个唯一命令来生成到主机标准输出的文本输出,然后 Amazon Redshift 会像读取文本文件一样读取它。
开始前的准备工作
在开始之前,您应做好以下准备:
-
您可使用 SSH 连接的一个或多个主机(如 Amazon EC2 实例)。
-
主机上的数据来源。
您将提供一些命令,Amazon Redshift 集群将在主机上运行这些命令以生成文本输出。在集群连接到主机后,COPY 命令将运行这些命令,从主机的标准输出中读取文本,并将数据并行加载到 Amazon Redshift 表中。文本输出必须采用 COPY 命令可提取的形式。有关更多信息,请参阅准备输入数据。
-
从您的计算机访问主机的权限。
对于 Amazon EC2 实例,您将使用 SSH 连接来访问主机。您必须访问主机以将 Amazon Redshift 集群的公有密钥添加到主机的授权密钥文件。
-
正在运行的 Amazon Redshift 集群。
有关如何启动集群的信息,请参阅 Amazon Redshift 入门指南。
加载数据的过程
本节指导您完成从远程主机加载数据的过程。以下各节提供每个步骤中必须完成的操作的详细信息。
-
公有密钥使 Amazon Redshift 集群节点能够建立与远程主机的 SSH 连接。您将使用每个集群节点的 IP 地址来配置主机安全组或防火墙,从而允许使用这些 IP 地址从 Amazon Redshift 集群进行访问。
-
步骤 2:将 Amazon Redshift 集群公有密钥添加到主机的授权密钥文件
您将 Amazon Redshift 集群公有密钥添加到主机的授权密钥文件,以便让主机识别 Amazon Redshift 集群并接受 SSH 连接。
-
步骤 3:将主机配置为接受 Amazon Redshift 集群的所有 IP 地址
对于 Amazon EC2,修改该实例的安全组,以添加接受 Amazon Redshift IP 地址的输入规则。对于其他主机,请修改防火墙,以便 Amazon Redshift 节点能够建立与远程主机的 SSH 连接。
-
您可以选择指定 Amazon Redshift 应使用公有密钥来标识主机。您必须找到公有密钥并将文本复制到您的清单文件中。
-
清单是一个 JSON 格式的文本文件,其中包含 Amazon Redshift 连接到主机并提取数据所需的详细信息。
-
Amazon Redshift 将读取清单文件并使用该信息连接到远程主机。如果 Amazon S3 桶不在您的 Amazon Redshift 集群所在的区域内,则必须使用 REGION 选项指定数据所在的区域。
-
从 Amazon Redshift 数据库运行 COPY 命令,以便将数据加载到 Amazon Redshift 表中。
步骤 1:检索集群公有密钥和集群节点 IP 地址
您将使用每个集群节点的 IP 地址来配置主机安全组,从而允许使用这些 IP 地址从 Amazon Redshift 集群访问。
使用控制台为您的集群检索集群公有密钥和集群节点 IP 地址
-
访问 Amazon Redshift 管理控制台。
-
在导航窗格中选择集群链接。
-
从列表中选择您的集群。
-
找到 SSH 数据摄取组。
记下 Cluster Public Key 和 Node IP addresses 中的值。您将在后面的步骤中用到它们。
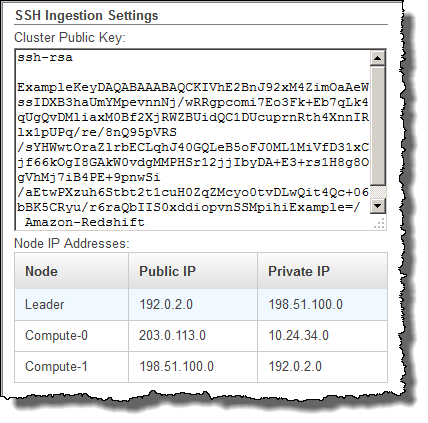
您将使用步骤 3 中的 IP 地址将主机配置为接受来自 Amazon Redshift 的连接。根据您连接到的主机的类型以及该主机是否在 VPC 中,您将使用公有 IP 地址或私有 IP 地址。
若要使用 Amazon Redshift CLI 检索您的集群的集群公有密钥和集群节点 IP 地址,请运行 describe-clusters 命令。
例如:
aws redshift describe-clusters --cluster-identifier <cluster-identifier>
响应将包含 ClusterPublicKey 以及私有和公有 IP 地址的列表,类似于以下内容:
{ "Clusters": [ { "VpcSecurityGroups": [], "ClusterStatus": "available", "ClusterNodes": [ { "PrivateIPAddress": "10.nnn.nnn.nnn", "NodeRole": "LEADER", "PublicIPAddress": "10.nnn.nnn.nnn" }, { "PrivateIPAddress": "10.nnn.nnn.nnn", "NodeRole": "COMPUTE-0", "PublicIPAddress": "10.nnn.nnn.nnn" }, { "PrivateIPAddress": "10.nnn.nnn.nnn", "NodeRole": "COMPUTE-1", "PublicIPAddress": "10.nnn.nnn.nnn" } ], "AutomatedSnapshotRetentionPeriod": 1, "PreferredMaintenanceWindow": "wed:05:30-wed:06:00", "AvailabilityZone": "us-east-1a", "NodeType": "dc2.large", "ClusterPublicKey": "ssh-rsa AAAABexamplepublickey...Y3TAl Amazon-Redshift", ... ... }
若要使用 Amazon Redshift API 检索您的集群的集群公有密钥和集群节点 IP 地址,请使用 DescribeClusters 操作。有关更多信息,请参阅《Amazon Redshift CLI 指南》中的 describe-clusters 或《Amazon Redshift API 指南》中的 DescribeClusters。
步骤 2:将 Amazon Redshift 集群公有密钥添加到主机的授权密钥文件
您将集群公有密钥添加到每个主机的授权密钥文件,以便让主机识别 Amazon Redshift 并接受 SSH 连接。
要将 Amazon Redshift 集群公有密钥添加到主机的授权密钥文件
-
使用 SSH 连接访问主机。
有关使用 SSH 连接到实例的信息,请参阅《Amazon EC2 用户指南》中的连接到您的实例。
-
从控制台或从 CLI 响应文本复制 Amazon Redshift 公有密钥。
-
将公有密钥的内容复制并粘贴到远程主机上的
/home/<ssh_username>/.ssh/authorized_keys文件中。<ssh_username>必须与清单文件中的“username”字段的值匹配。请包括完整字符串(包含前缀“ssh-rsa”和后缀“Amazon-Redshift”)。例如:ssh-rsa AAAACTP3isxgGzVWoIWpbVvRCOzYdVifMrh… uA70BnMHCaMiRdmvsDOedZDOedZ Amazon-Redshift
步骤 3:将主机配置为接受 Amazon Redshift 集群的所有 IP 地址
如果要使用 Amazon EC2 实例或 Amazon EMR 集群,请向主机的安全组添加入站规则以允许来自每个 Amazon Redshift 集群节点的流量。对于 Type,请选择在端口 22 上使用 TCP 协议的 SSH。对于源,请输入您在步骤 1:检索集群公有密钥和集群节点 IP 地址中检索的 Amazon Redshift 集群节点 IP 地址。有关添加规则到 Amazon EC2 安全组的信息,请参阅《Amazon EC2 用户指南》中的为您的实例授权入站流量。
请在以下情况下使用私有 IP 地址:
-
您具有一个没有位于 Virtual Private Cloud (VPC) 中的 Amazon Redshift 集群和一个 Amazon EC2 -Classic 实例,二者位于同一 Amazon 区域中。
-
您具有一个位于 VPC 中的 Amazon Redshift 集群和一个 Amazon EC2 -VPC 实例,二者位于同一 Amazon 区域和同一 VPC 中。
否则,请使用公有 IP 地址。
有关在 VPC 中使用 Amazon Redshift 的更多信息,请参阅《Amazon Redshift 管理指南》中的管理 Virtual Private Cloud (VPC) 中的集群。
步骤 4:获取主机的公有密钥
您可以选择在清单文件中提供主机的公有密钥以便让 Amazon Redshift 可以标识主机。COPY 命令不需要主机公有密钥,但出于安全原因,我们强烈建议使用公有密钥来帮助防止“中间人”攻击。
您可以在以下位置查找主机的公有密钥(其中 <ssh_host_rsa_key_name> 是主机的公有密钥的唯一名称):
: /etc/ssh/<ssh_host_rsa_key_name>.pub
注意
Amazon Redshift 仅支持 RSA 密钥。我们不支持 DSA 密钥。
在步骤 5 中创建清单文件时,您应将公有密钥的文本粘贴到清单文件条目中的“Public Key”字段中。
步骤 5:创建清单文件
COPY 命令可连接到使用 SSH 的多台主机,并可以与每台主机建立多个 SSH 连接。COPY 通过每个主机连接运行一个命令,然后将来自这些命令的输出并行加载到表中。清单文件是 Amazon Redshift 用于连接主机的文本文件,采用 JSON 格式。清单文件指定 SSH 主机端点以及将在主机上运行的用于将数据返回到 Amazon Redshift 的命令。另外,您还可以包含主机公有密钥、登录用户名和每个条目的 mandatory 标志。
在本地计算机上创建清单文件。在后一个步骤中,将文件上载到 Amazon S3。
清单文件应采用以下格式:
{ "entries": [ {"endpoint":"<ssh_endpoint_or_IP>", "command": "<remote_command>", "mandatory":true, "publickey": "<public_key>", "username": "<host_user_name>"}, {"endpoint":"<ssh_endpoint_or_IP>", "command": "<remote_command>", "mandatory":true, "publickey": "<public_key>", "username": "host_user_name"} ] }
该清单文件为每个 SSH 连接包含一个 "entries" 结构。每个条目表示一个 SSH 连接。您可以与单台主机建立多个连接或与多台主机建立多个连接。如上所示,字段名称和值均需要使用双引号。唯一的一个不需要双引号的值是 mandatory 字段的布尔值 true 或 false。
下面描述了清单文件中的字段。
- endpoint
-
主机的 URL 地址或 IP 地址。例如,“
ec2-111-222-333.compute-1.amazonaws.com”或“22.33.44.56”。 - 命令
-
将由主机运行的命令,用于生成文本或二进制(gzip、lzop 或 bzip2)输出。该命令可以是用户 "host_user_name" 有权运行的任何命令。命令可以是像打印文件这样简单的命令,也可以查询数据库或启动脚本。输出(文本文件、gzip 二进制文件、lzop 二进制文件或 bzip2 二进制文件)必须采用 Amazon Redshift COPY 命令可摄取的形式。有关更多信息,请参阅 准备输入数据。
- publickey
-
(可选)主机的公有密钥。如果提供了公有密钥,Amazon Redshift 将使用它来标识主机。如果未提供公有密钥,Amazon Redshift 将不会尝试主机标识。例如,如果远程主机的公有密钥是
ssh-rsa AbcCbaxxx…xxxDHKJ root@amazon.com,请在公有密钥字段中输入以下文本:AbcCbaxxx…xxxDHKJ。 - 必需:
-
(可选)指示在连接失败的情况下 COPY 命令是否应失败。默认值为
false。如果 Amazon Redshift 未成功建立至少一个连接,COPY 命令将失败。 - username
-
(可选)将用于登录到主机系统并运行远程命令的用户名。用户登录名必须与步骤 2 中用于将公有密钥添加到主机的授权密钥文件的登录名相同。默认用户名为“redshift”。
以下示例显示了用于与同一主机建立四个连接并通过每个连接运行不同的命令的完整清单:
{ "entries": [ {"endpoint":"ec2-184-72-204-112.compute-1.amazonaws.com", "command": "cat loaddata1.txt", "mandatory":true, "publickey": "ec2publickeyportionoftheec2keypair", "username": "ec2-user"}, {"endpoint":"ec2-184-72-204-112.compute-1.amazonaws.com", "command": "cat loaddata2.txt", "mandatory":true, "publickey": "ec2publickeyportionoftheec2keypair", "username": "ec2-user"}, {"endpoint":"ec2-184-72-204-112.compute-1.amazonaws.com", "command": "cat loaddata3.txt", "mandatory":true, "publickey": "ec2publickeyportionoftheec2keypair", "username": "ec2-user"}, {"endpoint":"ec2-184-72-204-112.compute-1.amazonaws.com", "command": "cat loaddata4.txt", "mandatory":true, "publickey": "ec2publickeyportionoftheec2keypair", "username": "ec2-user"} ] }
步骤 6:将清单文件上载到 Amazon S3 桶
将清单文件上载到 Amazon S3 桶。如果 Amazon S3 桶不在您的 Amazon Redshift 集群所在的 Amazon 区域内,则必须使用 REGION 选项指定清单所在的 Amazon 区域。有关创建 Amazon S3 桶并上载文件的信息,请参阅 Amazon Simple Storage Service 用户指南。
步骤 7:运行 COPY 命令以加载数据
运行 COPY 命令以连接到主机并将数据加载到 Amazon Redshift 表中。在 COPY 命令中,指定清单文件的显式 Amazon S3 对象路径并包含 SSH 选项。例如,
COPY sales FROM 's3://amzn-s3-demo-bucket/ssh_manifest' IAM_ROLE 'arn:aws:iam::0123456789012:role/MyRedshiftRole' DELIMITER '|' SSH;
注意
如果使用自动压缩,则 COPY 命令将执行两次数据读取,这意味着它将运行两次远程命令。第一次读取用于提供压缩分析的样本,第二次读取实际加载数据。如果运行远程命令两次可能会由于潜在副作用而导致问题,则应关闭自动压缩。要关闭自动压缩,请运行 COPY 命令,同时将 COMPUPDATE 选项设置为 OFF。有关更多信息,请参阅 使用自动压缩加载表。