从补丁 198 开始,Amazon Redshift 将不再支持创建新的 Python UDF。现有的 Python UDF 将继续正常运行至 2026 年 6 月 30 日。有关更多信息,请参阅博客文章
最大程度地减少 vacuum 次数
Amazon Redshift 自动对数据进行排序,并在后台运行 VACUUM DELETE。这减少了运行 VACUUM 命令的需要。Vacuum 可能是一个耗时的过程。根据数据的性质,建议您采用以下做法来最大程度地减少 vacuum 次数。
决定是否重建索引
通常,您可以使用交错排序样式来显著提高查询性能,但是随着时间的推移,如果排序键列中值的分配更改,性能可能会下降。
最初使用 COPY 或 CREATE TABLE AS 加载空交错表时,Amazon Redshift 自动构建交错索引。如果您最初使用 INSERT 加载交错表,则需要在之后运行 VACUUM REINDEX 以初始化交错索引。
随着时间的推移,在添加带有新排序键值的行后,如果排序键列中值的分布发生更改,性能可能会下降。如果新行主要处于现有排序键值的范围内,则不必重建索引。可以运行 VACUUM SORT ONLY 或 VACUUM FULL 恢复排序顺序。
查询引擎能够使用排序顺序高效地选择处理查询所需扫描的数据块。对于交错排序,Amazon Redshift 将分析排序键列值以确定最佳排序顺序。如果键值的分配在添加行时发生更改或偏移,则排序策略将不再是最佳的排序策略,并且排序的性能优势也会减小。要重新分析排序键分配,您可以运行 VACUUM REINDEX。重建索引操作非常耗时,因此,要决定表是否将从重建索引中获益,请查询 SVV_INTERLEAVED_COLUMNS 视图。
例如,以下查询将显示使用交错排序键的表的详细信息。
select tbl as tbl_id, stv_tbl_perm.name as table_name, col, interleaved_skew, last_reindex from svv_interleaved_columns, stv_tbl_perm where svv_interleaved_columns.tbl = stv_tbl_perm.id and interleaved_skew is not null;tbl_id | table_name | col | interleaved_skew | last_reindex --------+------------+-----+------------------+-------------------- 100048 | customer | 0 | 3.65 | 2015-04-22 22:05:45 100068 | lineorder | 1 | 2.65 | 2015-04-22 22:05:45 100072 | part | 0 | 1.65 | 2015-04-22 22:05:45 100077 | supplier | 1 | 1.00 | 2015-04-22 22:05:45 (4 rows)
interleaved_skew 的值是一个比率,指示偏移量。值 1 表示无偏移。如果偏移大于 1.4,VACUUM REINDEX 通常会提高性能,除非偏移是基础集中固有的。
您可以使用 last_reindex 中的数据值来确定自上次重建索引以来经历的时间。
减少未排序区域的大小
在将大量新数据加载到已包含数据的表中时,或在例行维护操作不包含对表进行的 vacuum 操作时,未排序区域将增大。要避免长时间运行的 vacuum 操作,请使用以下做法:
-
定期运行 vacuum 操作。
如果您以较小增量加载您的表(例如,表示表中行总数的一小部分的日常更新),定期运行 VACUUM 将帮助确保各个 vacuum 操作快速执行。
-
首先运行最大加载。
如果您需要使用多个 COPY 操作加载新表,请首先运行最大加载。当您运行到新的或截断的表中的初始加载时,所有数据将直接加载到已排序区域,因此无需执行 vacuum 操作。
-
截断表而不是删除所有行。
从表中删除行不会回收行占用的空间,除非您执行 vacuum 操作;不过,截断表将清空表并回收磁盘空间,因此无需执行 vacuum 操作。或者,请删除表并重新创建它。
-
截断或删除测试表。
如果您正在将少量行加载到表中以进行测试,请在完成此操作后不要删除这些行。相反,作为后续生产加载操作的一部分,请截断表并重新加载这些行。
-
执行深层复制。
如果使用复合排序键的表具有大型未排序区域,则深层复制要比 vacuum 快得多。深层复制将使用批量插入来重新创建并重新填充表,这将自动对表进行重新排序。如果表拥有大型未排序区域,深层复制将比真空化快得多。这样做的代价是,您不能在深层复制操作过程中进行并行更新,但可以在真空化时这样做。有关更多信息,请参阅 设计查询的 Amazon Redshift 最佳实践。
减少合并的行数
如果 vacuum 操作需要将新行合并到表的已排序区域,vacuum 所需的时间将随表的增大而增多。您可以通过减少必须合并的行数来提高 vacuum 性能。
在执行 vacuum 操作之前,表包含一个已排序区域(位于表开头处),后跟一个未排序区域(当添加或更新行时,该区域将增大)。如果 COPY 操作添加一组行,则这组新行在添加到表结尾处的未排序区域时将基于排序键进行排序。新行将在其自己的集合中进行排序,而不是在未排序区域内进行排序。
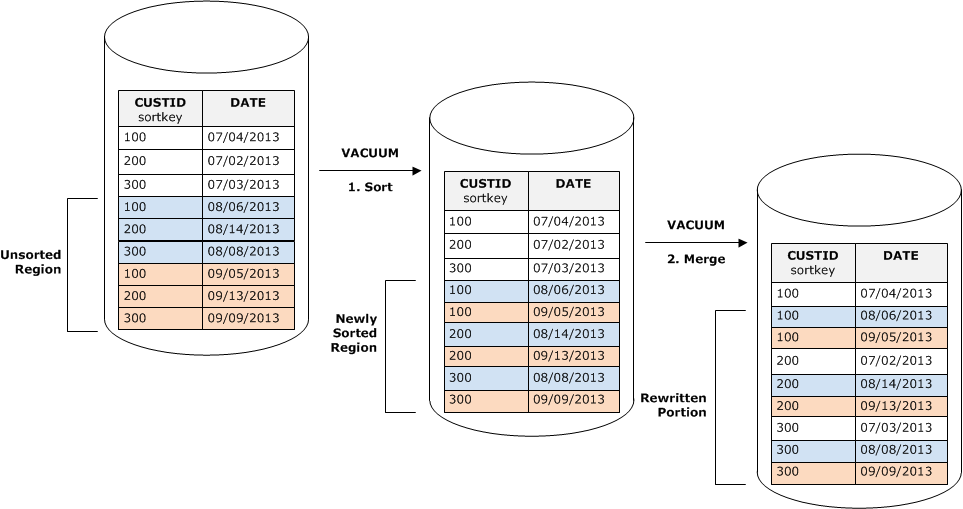
下图说明了两次连续 COPY 操作后的未排序区域,其中排序键为 CUSTID。为简便起见,此示例显示一个复合排序键,但相同的原则适用于交错排序键,只不过未排序区域对交错表的影响更大。

Vacuum 将按两个阶段还原复表的排序顺序:
-
将未排序区域归入新排序的区域。
第一个阶段的成本相对较低,因为仅重写未排序区域。如果新排序区域的排序键值的范围大于现有范围,则仅需要重写新行即可完成 vacuum。例如,如果已排序区域包含的 ID 值介于 1 和 500 之间,并且后续复制操作将添加大于 500 的键值,则仅需重写未排序区域。
-
将新排序的区域与之前排序的区域合并。
如果新排序的区域中的键与已排序区域中的键重叠,则 VACUUM 需要合并这些行。从新排序区域(最低排序键处)的开头开始,vacuum 会将从之前排序的区域和新排序的区域中的合并行写入一组新数据块。
新排序键范围与现有排序键重叠的程度将决定之前排序的区域需要被重写的程度。如果未排序键遍布于现有排序范围中,则 vacuum 可能需要重写表的现有部分。
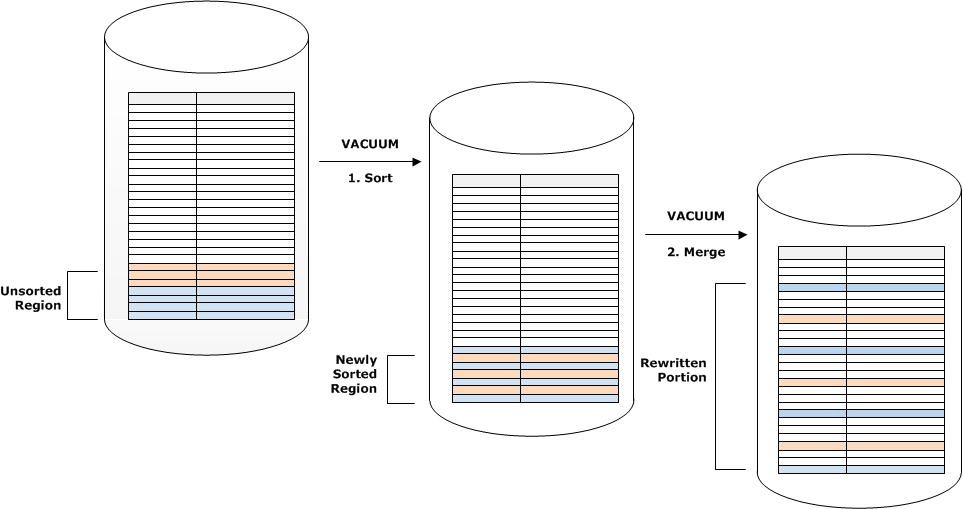
下图说明 vacuum 如何对添加到排序键为 CUSTID 的表中的行进行排序和合并。由于每个复制操作将添加一组键值与现有键重叠的新行,因此几乎需要重写整个表。该图显示单一排序和合并,但在实践中,大型 vacuum 包含一系列增量排序和合并步骤。
如果一组新行中的排序键范围与现有键的范围重叠,则合并阶段的成本将继续随表的增大与表大小成比例的增长,而排序阶段的成本与未排序区域的大小成正比。在这种情况下,合并阶段的成本远远超过排序阶段的成本,如下图所示。
要确定已重新合并的表的比例,请在 vacuum 操作完成后查询 SVV_VACUUM_SUMMARY。以下查询表明,在 CUSTSALES 随时间的推移而增大时,六个连续 vacuum 操作的效果。
select * from svv_vacuum_summary where table_name = 'custsales';table_name | xid | sort_ | merge_ | elapsed_ | row_ | sortedrow_ | block_ | max_merge_ | | partitions | increments | time | delta | delta | delta | partitions -----------+------+------------+------------+------------+-------+------------+---------+--------------- custsales | 7072 | 3 | 2 | 143918314 | 0 | 88297472 | 1524 | 47 custsales | 7122 | 3 | 3 | 164157882 | 0 | 88297472 | 772 | 47 custsales | 7212 | 3 | 4 | 187433171 | 0 | 88297472 | 767 | 47 custsales | 7289 | 3 | 4 | 255482945 | 0 | 88297472 | 770 | 47 custsales | 7420 | 3 | 5 | 316583833 | 0 | 88297472 | 769 | 47 custsales | 9007 | 3 | 6 | 306685472 | 0 | 88297472 | 772 | 47 (6 rows)
merge_increments 列指明了为每个 vacuum 操作合并的数据量。如果连续 vacuum 操作的合并增量的数量按表大小增长的比例增加,它表示每个 vacuum 操作重新合并的表中的行数正在增加,因为现有排序区域和新排序区域重叠。
按排序键顺序加载数据
如果您使用 COPY 命令按排序键顺序加载数据,可能会减少甚至消除对 vacuum 的需求。
当满足以下所有条件时,COPY 会向表的有序区域自动添加新行:
-
表使用了只有一个排序列的复合排序键。
-
排序列 NOT NULL。
-
表 100% 有序或为空。
-
所有新行的排序顺序均优先于现有行,包括标记为要删除的行。在此实例中,Amazon Redshift 使用排序键的前八个字节来确定排序顺序。
-
COPY 命令未触发特定负载优化。加载大量数据时,Amazon Redshift 可能会通过创建新的排序分区(而不是向表的排序区域添加行)来优化性能。
例如,假设您有一个使用客户 ID 和时间记录客户事件的表。如果按客户 ID 进行排序,则增量加载添加的新行的排序键范围可能会与现有范围重叠(如上一个示例中所示),从而导致昂贵的 vacuum 操作。
如果您将排序键设置为时间戳列,新行将按排序顺序追加到表的结尾(如下图所示),从而减少甚至消除对 vacuum 的需求。

使用时间序列表来减少存储的数据
如果您将数据保留滚动时段,请使用一系列表,如下图所示。

每当添加一组数据时创建一个新表,然后删除系列中最旧的表。您将获得双重好处:
-
避免增加删除行的成本,因为 DROP TABLE 操作比大规模 DELETE 更高效。
-
如果按时间戳对表进行排序,则不需要执行 vacuum 操作。如果每个表包含一个月的数据,则 vacuum 最多必须重写一个月的数据,即使表不是按时间戳排序的也是如此。
您可以创建 UNION ALL 视图供报告查询使用,从而隐藏数据存储在多个表中的事实。如果查询按排序键进行筛选,则查询计划程序可高效地跳过未使用的所有表。UNION ALL 对其他类型的查询可能不太高效,因此您应在所有使用表的查询的环境中评估查询性能。