从补丁 198 开始,Amazon Redshift 将不再支持创建新的 Python UDF。现有的 Python UDF 将继续正常运行至 2026 年 6 月 30 日。有关更多信息,请参阅博客文章
查看集群性能数据
通过使用 Amazon Redshift 中的集群指标,您可以执行以下常见性能任务:
-
判断集群指标在指定时间范围内是否异常;如果异常的话,则确定负责这种性能冲击的查询。
-
查看历史或当前查询是否对集群性能造成了影响。如果您识别出了一个有问题的查询,则可以在查询执行期间查看有关该查询的详细信息(包括集群性能)。您可以使用此信息来诊断为何查询速度慢以及可以采取哪些措施来提高它的性能。
查看性能数据
-
登录到 Amazon Web Services 管理控制台并打开 Amazon Redshift 控制台,网址:https://console.aws.amazon.com/redshiftv2/
。 -
在导航菜单上,选择集群,然后从列表中选择集群名称以打开其详细信息。此时将显示集群的详细信息,其中包括集群性能、查询监控、数据库、数据共享、计划、维护和属性选项卡。
-
选择集群性能选项卡以查看性能信息,其中包括以下信息:
-
CPU 使用率
-
已使用磁盘空间的百分比
-
数据库连接
-
运行状况
-
查询持续时间
-
查询吞吐量
-
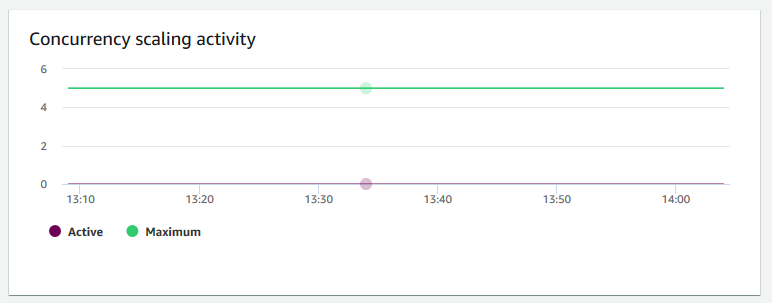
并发扩展活动
此外,还提供了许多其他指标。要查看可用指标并选择要显示的指标,请选择首选项图标。
-
集群性能图表
以下示例显示新的 Amazon Redshift 控制台中显示的一些图表。
-
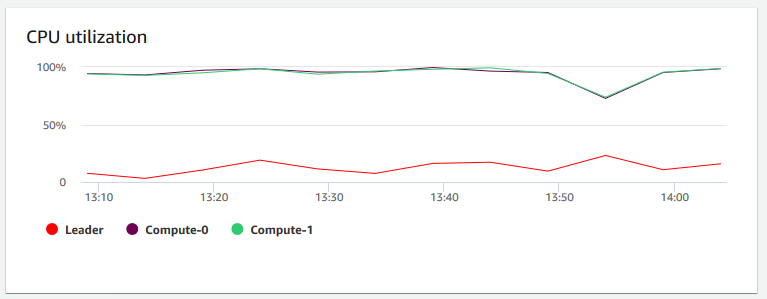
CPU 利用率 – 显示所有节点(领导节点和计算节点)的 CPU 利用率百分比。要在计划集群迁移或其他资源消耗型操作之前查找集群使用率最低的时间,请监控此图表以查看每个节点或所有节点的 CPU 使用率。
-
维护模式 – 通过使用
On和Off指示灯显示集群在所选时间是否处于维护模式。您可以查看集群正在进行维护的时间。然后,您可以将此时间与对集群执行的操作相关联,以估计其将来发生重复性事件的停机时间。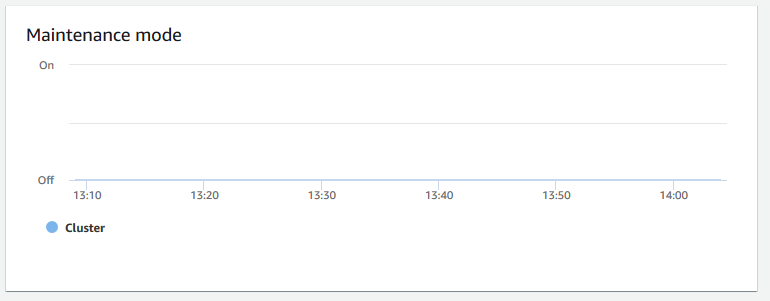
-
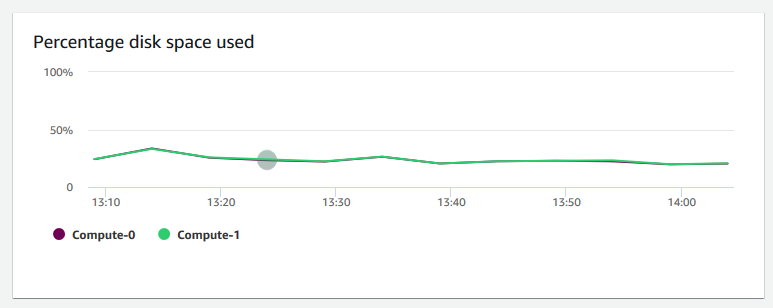
已使用磁盘空间的百分比 – 显示每个计算节点(而不是整个集群)的磁盘空间使用量百分比。您可以浏览此图表来监控磁盘利用率。VACUUM 和 COPY 等维护操作使用中间临时存储空间来执行排序操作,因此预计磁盘使用量会出现峰值。
-
读取吞吐量 – 显示每秒从磁盘读取的平均兆字节数。您可以评估此图表以监控集群的相应物理方面。此吞吐量不包括集群中的实例与集群的卷之间的网络流量。
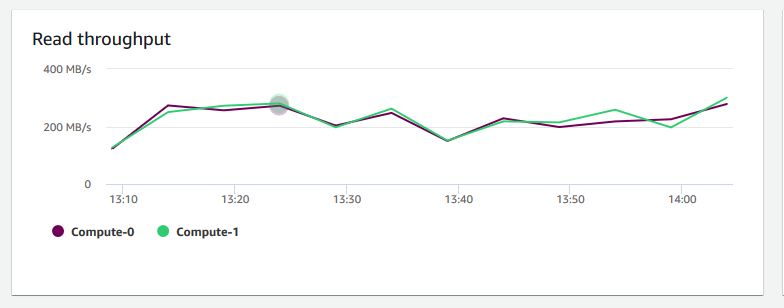
-
读取延迟 – 显示磁盘读取输入/输出操作所花费的平均时间(以毫秒为单位)。您可以查看要返回的数据的响应时间。当延迟很高时,这意味着发送方处于空闲状态的时间会更多(不发送任何新的数据包),这会降低吞吐量的增长速度。
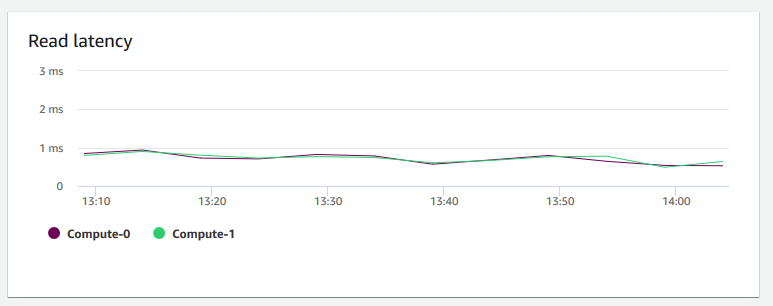
-
写入吞吐量 – 显示每秒写入磁盘的平均兆字节数。您可以评估此指标,以监控集群的相应物理方面。此吞吐量不包括集群中的实例与集群的卷之间的网络流量。
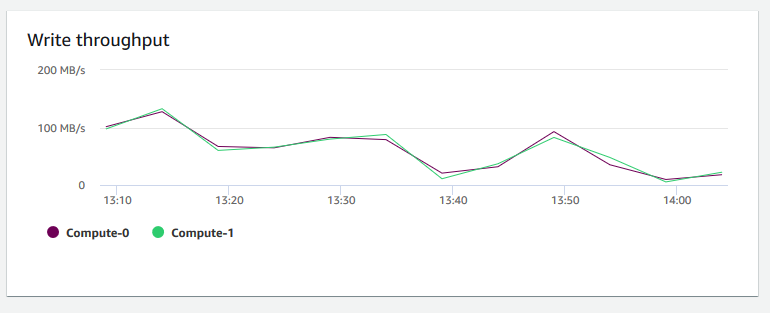
-
写入延迟 – 显示磁盘写入输入/输出操作所花费的平均时间(以毫秒为单位)。您可以评估返回写确认的时间。当延迟很高时,这意味着发送方处于空闲状态的时间会更多(不发送任何新的数据包),这会降低吞吐量的增长速度。
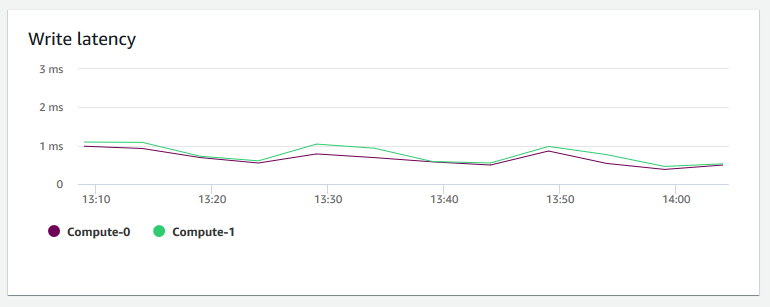
-
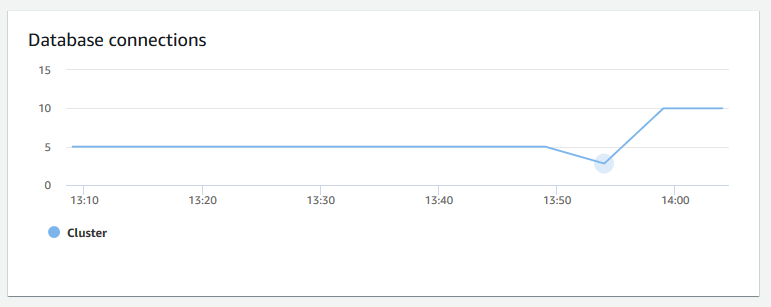
数据库连接数 – 显示到集群的数据库连接数。您可以使用此图表查看与数据库建立的连接数,并查找集群使用率最低的时间。
-
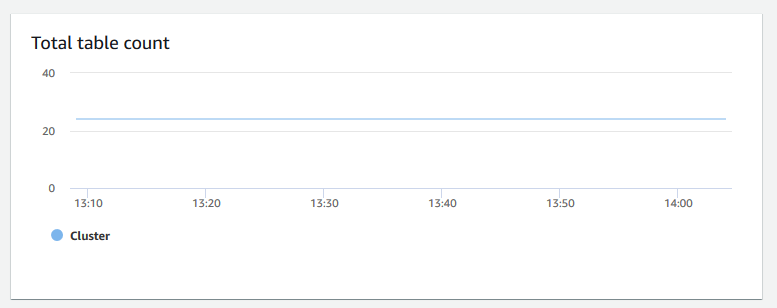
总的表计数 – 显示集群内在某个特定时间点打开的用户表的数量。您可以在打开的表计数较高时监控集群性能。
-
运行状况 – 将集群的运行状况指示为
Healthy或Unhealthy。如果集群可以连接到其数据库并成功执行简单查询,则集群将被视为运行状况良好。否则,视为集群运行状况不佳。当数据库集群负载极重,或者集群上的数据库存在配置问题时,集群会出现运营状况不佳的情况。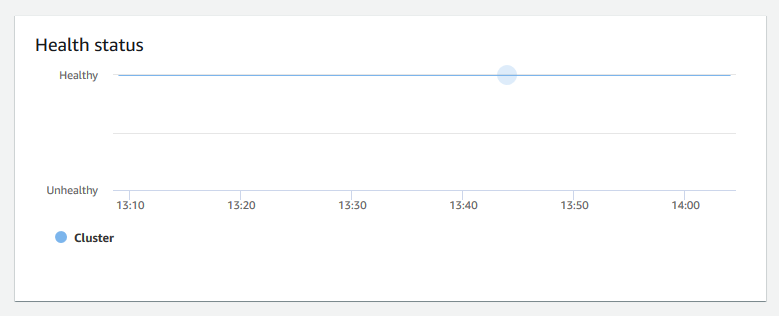
-
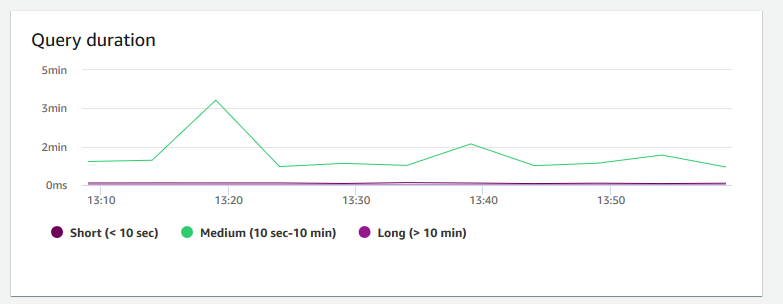
查询持续时间 – 显示完成查询的平均时间量(以微秒为单位)。您可以将此图表上的数据作为基准以衡量集群内的 I/O 性能,并在必要时调整其最耗时的查询。
-
查询吞吐量 – 显示每秒完成的查询的平均数。您可以分析此图表上的数据以衡量数据库性能,并表明系统以均衡的方式支持多用户工作负载的能力。
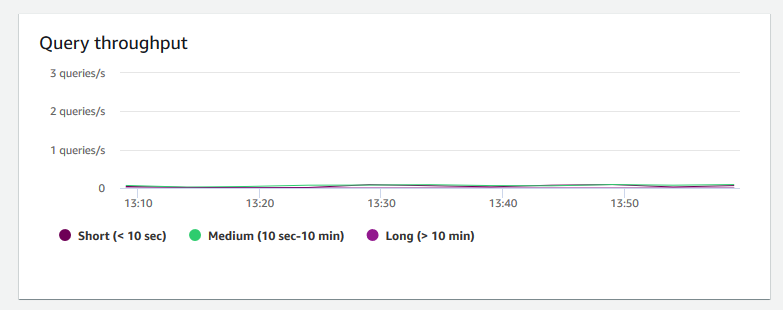
-
每个 WLM 队列的查询持续时间 – 显示完成查询的平均时间量(以微秒为单位)。您可以将此图表上的数据作为基准测试,以衡量每个 WLM 队列的 I/O 性能,并在必要时调整其最耗时的查询。
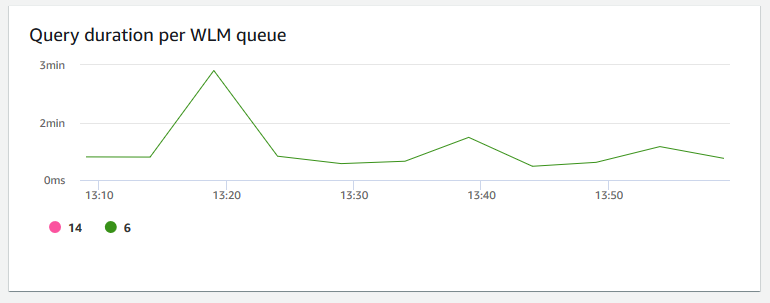
-
每个 WLM 队列的查询吞吐量 – 显示每秒完成的查询的平均数。您可以分析此图表上的数据,以衡量每个 WLM 队列的数据库性能。
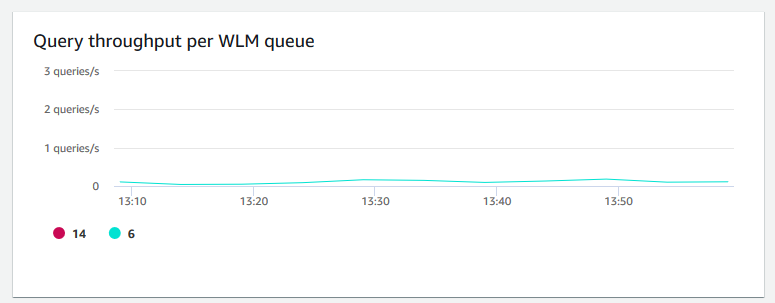
-
并发扩缩活动 – 显示活动的并发扩展集群的数量。启用并发扩展后,Amazon Redshift 会在需要时自动增加额外的集群容量来处理增多的并发读取查询。