本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
在 Step Function 中使用分布式模式下的 Map 状态处理大规模并行工作负载
管理状态和转换数据
了解有关使用变量在状态之间传递数据和使用转换数据的信息 JSONata。
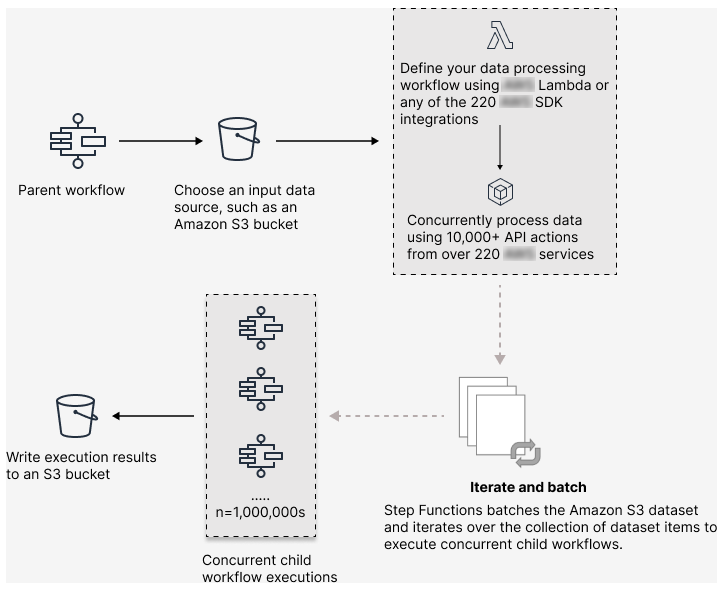
借助 Step Functions,您可以编排大规模的并行工作负载来执行任务,例如按需处理半结构化数据。这些并行工作负载允许您同时处理存储在 Amazon S3 中的大规模数据来源。例如,您可以处理包含大量数据的单个 JSON 或 CSV 文件。或者,您也可以处理一大组 Amazon S3 对象。
要在工作流中设置大规模的并行工作负载,请添加一个分布式模式下的 Map 状态。Map 状态 可同时处理数据集中的项目。设置为分布式的 Map 状态被称为分布式 Map 状态。在分布式模式下,Map 状态允许高并发处理。在分布式模式下,Map 状态在称为子工作流执行 迭代中处理数据集中的项目。您可以指定可并行运行的子工作流执行的数量。每个子工作流执行都有自己的、独立于父工作流的执行历史记录。如果您未指定,Step Functions 将并行运行 1 万个并行子工作流执行。
下图说明了如何在工作流中设置大规模的并行工作负载。
在讲习会上了解
了解 Step Functions 和 Lambda 等无服务器技术如何可以简化管理和扩展、卸载无差异的任务以及应对大规模分布式数据处理的挑战。在此过程中,您将使用分布式 Map 来进行高并发处理。该讲习会还介绍了用于优化工作流程的最佳实践,以及索赔处理、漏洞扫描和 Monte Carlo 模拟的实际用例。
关键术语
- 分布式模式
-
Map 状态的一种处理模式。在此模式下,
Map状态的每次迭代都作为子工作流执行来运行,从而实现高并发数。每个子工作流执行都有自己的执行历史记录,独立于父工作流的执行历史。该模式支持从大规模 Amazon S3 数据来源读取输入。 - 分布式 Map 状态
-
设置为分布式处理模式的 Map 状态。
- Map 工作流
Map状态运行的一组步骤。- 父工作流
-
包含一个或多个分布式 Map 状态的工作流。
- 子工作流执行
-
分布式 Map 状态的一次迭代。子工作流执行有自己的执行历史记录,独立于父工作流的执行历史。
- Map Run
-
当您运行分布式模式下的
Map状态时,Step Functions 会创建一个 Map Run 资源。Map Run 是指分布式 Map 状态 启动的一组子工作流执行,以及控制这些执行的运行时设置。Step Functions 会为 Map Run 分配一个 Amazon 资源名称 (ARN)。您可以在 Step Functions 控制台中查看 Map Run。您也可以调用DescribeMapRunAPI 操作。Map Run 的子工作流程执行会将指标发送到 CloudWatch;。这些指标将有一个标有状态机的 ARN,格式如下:
arn:partition:states:region:account:stateMachine:stateMachineName/MapRunLabel or UUID有关更多信息,请参阅 查看 Map Run。
分布式地图状态定义示例 (JSONPath)
当您需要编排满足以下任意条件组合的大规模并行工作负载时,请使用分布式模式的 Map 状态:
数据集的大小超过 256 KiB。
该工作流的执行事件历史记录超过 2.5 万个条目。
您需要一个超过 40 次并行迭代的并发数。
下面的分布式 Map 状态 定义示例将数据集指定为存储在 Amazon S3 存储桶中的 CSV 文件。它还指定了一个 Lambda 函数,用于处理 CSV 文件每一行中的数据。由于此示例使用了一个 CSV 文件,因此它还指定了 CSV 列标题的位置。要查看此示例的完整状态机定义,请参阅教程使用分布式 Map 复制大规模 CSV 数据。
{
"Map": {
"Type": "Map",
"ItemReader": {
"ReaderConfig": {
"InputType": "CSV",
"CSVHeaderLocation": "FIRST_ROW"
},
"Resource": "arn:aws:states:::s3:getObject",
"Parameters": {
"Bucket": "amzn-s3-demo-bucket",
"Key": "csv-dataset/ratings.csv"
}
},
"ItemProcessor": {
"ProcessorConfig": {
"Mode": "DISTRIBUTED",
"ExecutionType": "EXPRESS"
},
"StartAt": "LambdaTask",
"States": {
"LambdaTask": {
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"OutputPath": "$.Payload",
"Parameters": {
"Payload.$": "$",
"FunctionName": "arn:aws:lambda:us-east-2:account-id:function:processCSVData"
},
"End": true
}
}
},
"Label": "Map",
"End": true,
"ResultWriter": {
"Resource": "arn:aws:states:::s3:putObject",
"Parameters": {
"Bucket": "amzn-s3-demo-destination-bucket",
"Prefix": "csvProcessJobs"
}
}
}
}运行分布式 Map 的权限
当您在工作流中包含分布式 Map 状态 时,Step Functions 需要适当的权限才能允许状态机角色为分布式 Map 状态 调用 StartExecution API 操作。
以下 IAM 策略示例授予您的状态机角色运行分布式 Map 状态 所需的最低权限。
注意
确保将 stateMachineNamearn:aws:states:。region:account-id:stateMachine:mystateMachine
-
{ "Version":"2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "states:StartExecution" ], "Resource": [ "arn:aws:states:us-east-1:123456789012:stateMachine:myStateMachineName" ] }, { "Effect": "Allow", "Action": [ "states:DescribeExecution" ], "Resource": "arn:aws:states:us-east-1:123456789012:execution:myStateMachineName:*" } ] }
此外,您需要确保您拥有访问分布式地图状态下使用的 Amazon 资源(例如 Amazon S3 存储桶)所需的最低权限。有关信息,请参阅使用分布式 Map 状态的 IAM 策略。
分布式 Map 状态字段
要在工作流中使用分布式 Map 状态,请指定其中一个或多个字段。除了公共状态字段外,您还可以指定以下字段。
Type(必填)-
设置状态的类型,例如
Map。 ItemProcessor(必填)-
包含以下 JSON 对象,用于指定
Map状态处理模式和定义。-
ProcessorConfig:指定用于处理项目的模式的 JSON 对象,具有以下子字段:-
Mode– 设置为DISTRIBUTED,以在分布式模式下使用Map状态。警告
标准工作流程支持分布式模式,但快速工作流程不支持该模式。
-
ExecutionType– 将 Map 工作流的执行类型指定为标准或快速。如果您为Mode子字段指定了DISTRIBUTED,则必须提供此字段。有关工作流类型的更多信息,请参阅在 Step Functions 中选择工作流程类型。
-
StartAt– 指定表示工作流中第一个状态的字符串。该字符串区分大小写,必须与某个状态对象的名称相匹配。此状态首先针对数据集中的每个项目运行。您向Map状态提供的任何执行输入都将首先传递给StartAt状态。States– 一个 JSON 对象,其中包含逗号分隔的状态集合。在此对象中,您可以定义 Map workflow。
-
ItemReader-
指定一个数据集及其位置。
Map状态接收来自指定数据集的输入数据。在分布式模式下,您可以使用从先前状态传递的 JSON 有效负载,也可以使用大规模的 Amazon S3 数据来源作为数据集。有关更多信息,请参阅 ItemReader (地图)。
Items( JSONata 仅限可选)-
JSON 数组、JSON 对象或必须计算为数组或对象的 JSONata 表达式。
ItemsPath( JSONPath 仅限可选)-
使用JsonPath
语法指定参考路径,选择包含项目数组的 JSON 节点或状态输入中包含键值对的对象。 在分布式模式下,只有使用上一步中的 JSON 数组或对象作为状态输入时,才能指定此字段。有关更多信息,请参阅 ItemsPath ( JSONPath 仅限地图)。
ItemSelector( JSONPath 仅限可选)-
在将单个数据集项目的值传递到每次
Map状态迭代之前,覆盖这些值。在此字段中,指定包含键值对集合的有效 JSON 输入。这些对可以是您在状态机定义中定义的静态值,使用路径从状态输入中选择的值,或者从上下文对象中获取的值。有关更多信息,请参阅ItemSelector(Map)。
ItemBatcher(可选)-
指定批量处理数据集项目。然后,每个子工作流执行都会收到一批这些项目作为输入。有关更多信息,请参阅ItemBatcher(Map)。
MaxConcurrency(可选)-
指定可并行运行的子工作流数量。解释器只允许执行指定数量的并行子工作流。如果您未指定并发值或将其设置为零,Step Functions 不会限制并发,并且会运行 1 万个并行子工作流程执行。在 JSONata 状态中,您可以指定计算结果为整数的 JSONata 表达式。
注意
虽然您可以为并行子工作流程执行指定更高的并发限制,但我们建议您不要超过下游 Amazon 服务的容量,例如 Amazon Lambda。
MaxConcurrencyPath( JSONPath 仅限可选)-
如果要使用参考路径从状态输入中动态提供最大并发数值,请使用
MaxConcurrencyPath。解决后,参考路径必须选择一个值为非负整数的字段。注意
一个
Map状态不能同时包含MaxConcurrency和MaxConcurrencyPath。 ToleratedFailurePercentage(可选)-
定义在 Map Run 中允许的失败项目的百分比。如果超过此百分比,Map Run 将自动失败。Step Functions 通过失败或超时项目总数除以项目总数计算失败项目的百分比。您可以指定 0 到 100 之间的值。有关更多信息,请参阅 在 Step Functions 中为分布式 Map 状态设置故障阈值。
在 JSONata 状态中,您可以指定计算结果为整数的 JSONata 表达式。
ToleratedFailurePercentagePath( JSONPath 仅限可选)-
如果要使用参考路径从状态输入中动态提供容许的故障百分比值,请使用
ToleratedFailurePercentagePath。解决后,参考路径必须选择一个值介于 0 到 100 之间的字段。 ToleratedFailureCount(可选)-
定义 Map Run 中允许的失败项目数量。如果超过此数量,Map Run 将自动失败。有关更多信息,请参阅 在 Step Functions 中为分布式 Map 状态设置故障阈值。
在 JSONata 状态中,您可以指定计算结果为整数的 JSONata 表达式。
ToleratedFailureCountPath( JSONPath 仅限可选)-
如果要使用参考路径从状态输入中动态提供容许的故障计数值,请使用
ToleratedFailureCountPath。解决后,参考路径必须选择一个值为非负整数的字段。 Label(可选)-
唯一标识
Map状态的字符串。对于每个 Map Run,Step Functions 都会将标签添加到 Map Run ARN。以下是带有名为demoLabel的自定义标签的 Map Run ARN 的示例:arn:aws:states:region:account-id:mapRun:demoWorkflow/demoLabel:3c39a231-69bb-3d89-8607-9e124eddbb0b如果您未指定标签,则 Step Functions 会自动生成一个唯一标签。
注意
标签长度不能超过 40 个字符,在状态机定义中必须唯一,并且不能包含任何以下字符:
-
空格
-
通配符 (
? *) -
方括号字符 (
< > { } [ ]) -
特殊字符 (
: ; , \ | ^ ~ $ # % & ` ") -
控制字符(
\\u0000-\\u001f或\\u007f-\\u009f)
Step Functions 对于状态机、执行、活动和标签接受包含非 ASCII 字符的名称。由于此类字符会 CloudWatch 阻止亚马逊记录数据,因此我们建议您仅使用 ASCII 字符,这样您就可以跟踪 Step Functions 的指标。
-
ResultWriter(可选)-
指定 Step Functions 写入所有子工作流执行结果的 Amazon S3 位置。
Step Functions 整合了所有子工作流执行数据,例如执行输入和输出、ARN 和执行状态。然后,它将状态相同的执行导出到指定 Amazon S3 位置的相应文件中。有关更多信息,请参阅 ResultWriter (地图)。
如果您不导出
Map状态结果,它将返回一个包含所有子工作流执行结果的数组。例如:[1, 2, 3, 4, 5] ResultPath( JSONPath 仅限可选)-
指定输入中放置迭代输出的位置。接下来,输入将按照 OutputPath 字段(如果存在)指定的内容进行筛选,然后再用作状态输出传递。有关更多信息,请参阅输入和输出处理。
ResultSelector(可选)-
传递一个键值对集合,其中,值为静态值或从结果中选择的值。有关更多信息,请参阅 ResultSelector。
提示
如果您在状态机中使用的 Parallel 或 Map 状态返回由数组组成的数组,您可以使用 ResultSelector 字段将他们转换为一个平面数组。有关更多信息,请参阅展平由数组组成的数组。
Retry(可选)-
一个称为重试器的对象数组,用于定义重试策略。如果状态遇到运行时错误,则执行将使用重试策略。有关更多信息,请参阅 使用 Retry 和 Catch 的状态机示例。
注意
如果您为分布式 Map 状态 定义了重试器,则重试策略将应用于
Map状态启动的所有子工作流执行。例如,假设Map状态启动了三个子工作流执行,其中一个失败了。失败发生时,将执行将使用Retry字段(如果已定义),用于Map状态。重试策略应用于所有子工作流执行,而不仅仅是失败的执行。如果一个或多个子工作流执行失败,则 Map Run 将失败。当您重试某个
Map状态时,它会创建一个新的 Map Run。 Catch(可选)-
一个称为捕获器的对象数组,用于定义回退状态。如果状态遇到运行时错误,Step Functions 将使用
Catch中定义的捕获器。发生错误时,执行会首先使用Retry中定义的任何重试器。如果重试策略未定义或已用尽,则执行将使用其捕获器(如果已定义)。有关更多信息,请参阅回退状态。 Output( JSONata 仅限可选)-
用于指定和转换状态的输出。指定后,该值将覆盖状态输出默认值。
输出字段接受任何 JSON 值(对象、数组、字符串、数字、布尔值、null)。任何字符串值,包括对象或数组内部的值,都将被计算为 JSONata 被 {%%} 个字符包围。
输出也直接接受 JSONata 表达式,例如:“输出”:“{% jsonata expression%}”
有关更多信息,请参阅在 Step Functions 中使用 JSONata 转换数据。
-
Assign(可选) -
用于存储变量。该
Assign字段接受一个 JSON 对象,该对象包含定义变量名及其分配值的 key/value 对。任何字符串值,包括对象或数组内部的值,都将按照被{% %}字符包围 JSONata 时的计算方式进行计算有关更多信息,请参阅 使用变量在状态之间传递数据。
在 Step Functions 中为分布式 Map 状态设置故障阈值
在编排大规模并行工作负载时,您还可以定义一个容许的故障阈值。此值可用于指定失败项目的最大数量或百分比作为 Map Run 的失败阈值。根据您指定的数量值或百分比值,如果超出阈值,Map Run 将自动失败。如果同时指定两个值,则当工作流超过任一值时,工作流就会失败。
指定阈值可以帮助您在整个 Map Run 失败之前允许特定定数量的项目失败。当 Map Run 因超过指定阈值而失败时,Step Functions 会返回 States.ExceedToleratedFailureThreshold 错误。
注意
即使在超过容许的失败阈值之后,Step Functions 仍可能在 Map Run 失败之前继续运行 Map Run 中的子工作流。
要在 Workflow Studio 中指定阈值,请在运行时设置字段下的其他配置中选择设置容许的故障阈值。
- 容许的失败百分比
-
定义容许的失败项目所占的百分比。如果超过此值,Map Run 将失败。Step Functions 通过失败或超时项目总数除以项目总数计算失败项目的百分比。您可以指定 0 到 100 之间的值。默认百分比值为零,意味着如果任何一个子工作流执行失败或超时,工作流就会失败。如果将百分比指定为 100,则即使所有子工作流执行都失败,该工作流也不会失败。
或者,您可以将百分比指定为分布式 Map 状态 输入中现有键值对的参考路径。在运行时,此路径必须解析为 0 到 100 之间的正整数。您可以在
ToleratedFailurePercentagePath子字段中指定参考路径。例如,给定以下输入:
{"percentage":15}您可以使用该输入的参考路径来指定百分比,如下所示:
{ ... "Map": { "Type": "Map", ..."ToleratedFailurePercentagePath":"$.percentage"... } }重要
您可以在分布式 Map 状态定义中指定
ToleratedFailurePercentage或ToleratedFailurePercentagePath,但不能同时指定两者。 - 容许的失败数
-
定义容许的失败项目数。如果超过此值,Map Run 将失败。
或者,您可以将该数值指定为分布式 Map 状态 输入中现有键值对的参考路径。在运行时,此路径必须解析为正整数。您可以在
ToleratedFailureCountPath子字段中指定参考路径。例如,给定以下输入:
{"count":10}您可以使用该输入的参考路径来指定数值,如下所示:
{ ... "Map": { "Type": "Map", ..."ToleratedFailureCountPath":"$.count"... } }重要
您可以在分布式 Map 状态定义中指定
ToleratedFailureCount或ToleratedFailureCountPath,但不能同时指定两者。
了解有关分布式 Map 的更多信息
要继续了解有关分布式 Map 状态的更多信息,请参阅以下资源:
-
输入和输出处理
为了配置分布式 Map 状态接收的输入及其生成的输出,Step Functions 提供了以下字段:
除了这些字段外,Step Functions 还可以为分布式 Map 定义容许的故障阈值。此值可用于指定失败项目的最大数量或百分比作为 Map Run 的失败阈值。有关配置容许的故障阈值的更多信息,请参阅在 Step Functions 中为分布式 Map 状态设置故障阈值。
-
使用分布式 Map 状态
要开始使用分布式 Map 状态,请参阅以下教程和示例项目。
-
检查分布式 Map 状态执行
Step Functions 控制台提供 Map Run 详细信息 页面,其中显示了与分布式 Map 状态 执行相关的所有信息。有关如何检查此页面上显示的信息的信息,请参阅查看 Map Run。